

此页面或文档已过期,请点击链接跳转到新页面。
前往新页面 →第五章:向量数据库
此页面或文档已过期,请点击链接跳转到新页面。
前往新页面 →- 作者:影子, Spring AI Alibaba Committer
- 本文档基于 Spring AI 1.0.0 版本,Spring AI Alibaba 1.0.0.2 版本
- 本章是快速上手(内存、Redis、Elasticsearch)+源码解读(向量数据库源码、Redis自动注入、Es自动注入)
向量数据库快速上手
向量数据库,查询不同于传统的关系型数据库,执行相似性搜索而不是完全匹配。当给定一个向量作为查询时,向量数据库会返回与查询向量“相似”的向量。 以下实现了向量数据库的典型案例:基于内存、Redis、Elasticsearch,实战代码可见:https://github.com/GTyingzi/spring-ai-tutorial 下的vector
基础 pom 文件
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-autoconfigure-model-openai</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-vector-store</artifactId> </dependency>
</dependencies>内存
application.yml
server: port: 8080
spring: application: name: vector-simple
ai: openai: api-key: ${DASHSCOPEAPIKEY} base-url: https://dashscope.aliyuncs.com/compatible-mode embedding: options: model: text-embedding-v1选择对应的嵌入模型:text-embedding-v1
VectorSimpleController
@RestController@RequestMapping("/vector/simple")public class VectorSimpleController { private static final Logger logger = LoggerFactory.getLogger(VectorSimpleController.class); private final SimpleVectorStore simpleVectorStore; private final String SAVEPATH = System.getProperty("user.dir") + "/vector/vector-simple/src/main/resources/save.json";
public VectorSimpleController(EmbeddingModel embeddingModel) { this.simpleVectorStore = SimpleVectorStore .builder(embeddingModel).build(); }
@GetMapping("/add") public void add() { logger.info("start add data");
HashMap<String, Object> map = new HashMap<>(); map.put("year", 2025); map.put("name", "yingzi"); List<Document> documents = List.of( new Document("The World is Big and Salvation Lurks Around the Corner"), new Document("You walk forward facing the past and you turn back toward the future.", Map.of("year", 2024)), new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", map), new Document("1", "test content", map)); simpleVectorStore.add(documents); }
@GetMapping("/delete") public void delete() { logger.info("start delete data"); simpleVectorStore.delete(List.of("1")); }
@GetMapping("/save") public void save() { logger.info("start save data: {}", SAVEPATH); File file = new File(SAVEPATH); if (file.exists()) { file.delete(); } simpleVectorStore.save(file); }
@GetMapping("/load") public void load() { logger.info("start load data: {}", SAVEPATH); File file = new File(SAVEPATH); simpleVectorStore.load(file); }
@GetMapping("/search") public List<Document> search() { logger.info("start search data"); return simpleVectorStore.similaritySearch(SearchRequest .builder() .query("Spring") .topK(2) .build()); }
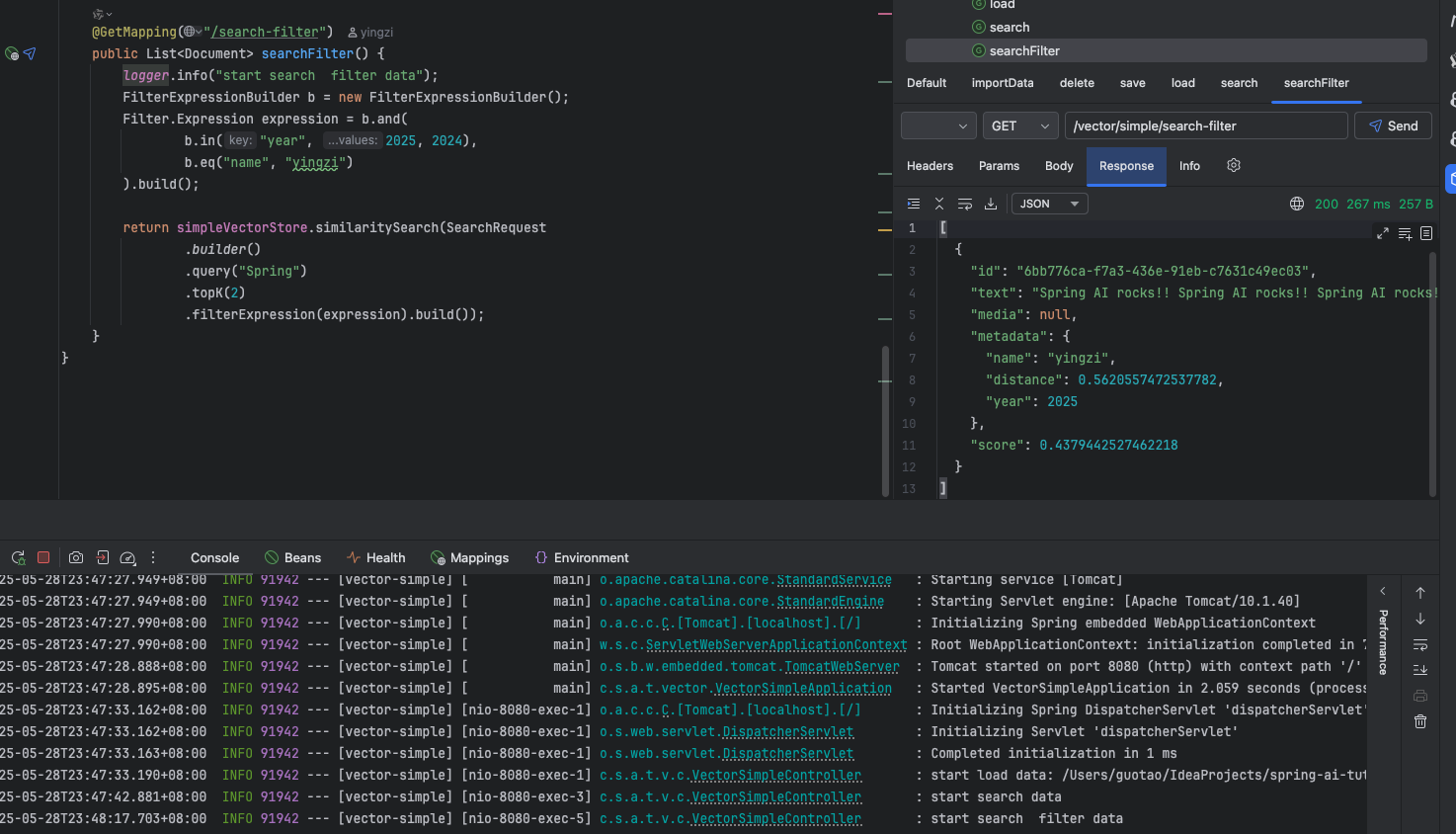
@GetMapping("/search-filter") public List<Document> searchFilter() { logger.info("start search filter data"); FilterExpressionBuilder b = new FilterExpressionBuilder(); Filter.Expression expression = b.and( b.in("year", 2025, 2024), b.eq("name", "yingzi") ).build();
return simpleVectorStore.similaritySearch(SearchRequest .builder() .query("Spring") .topK(2) .filterExpression(expression).build()); }}效果
导入 4 条数据
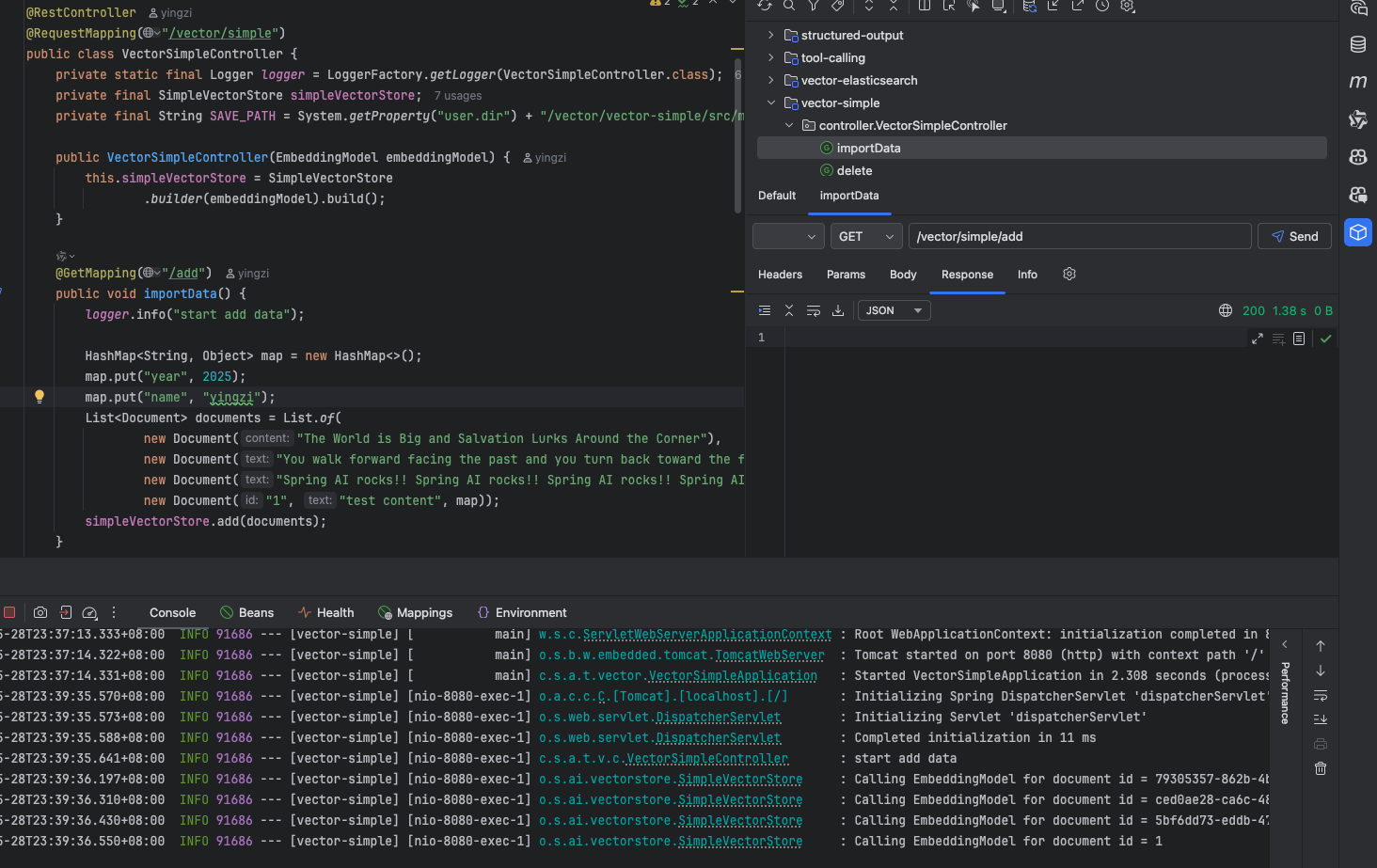
删除 id=1 的数据
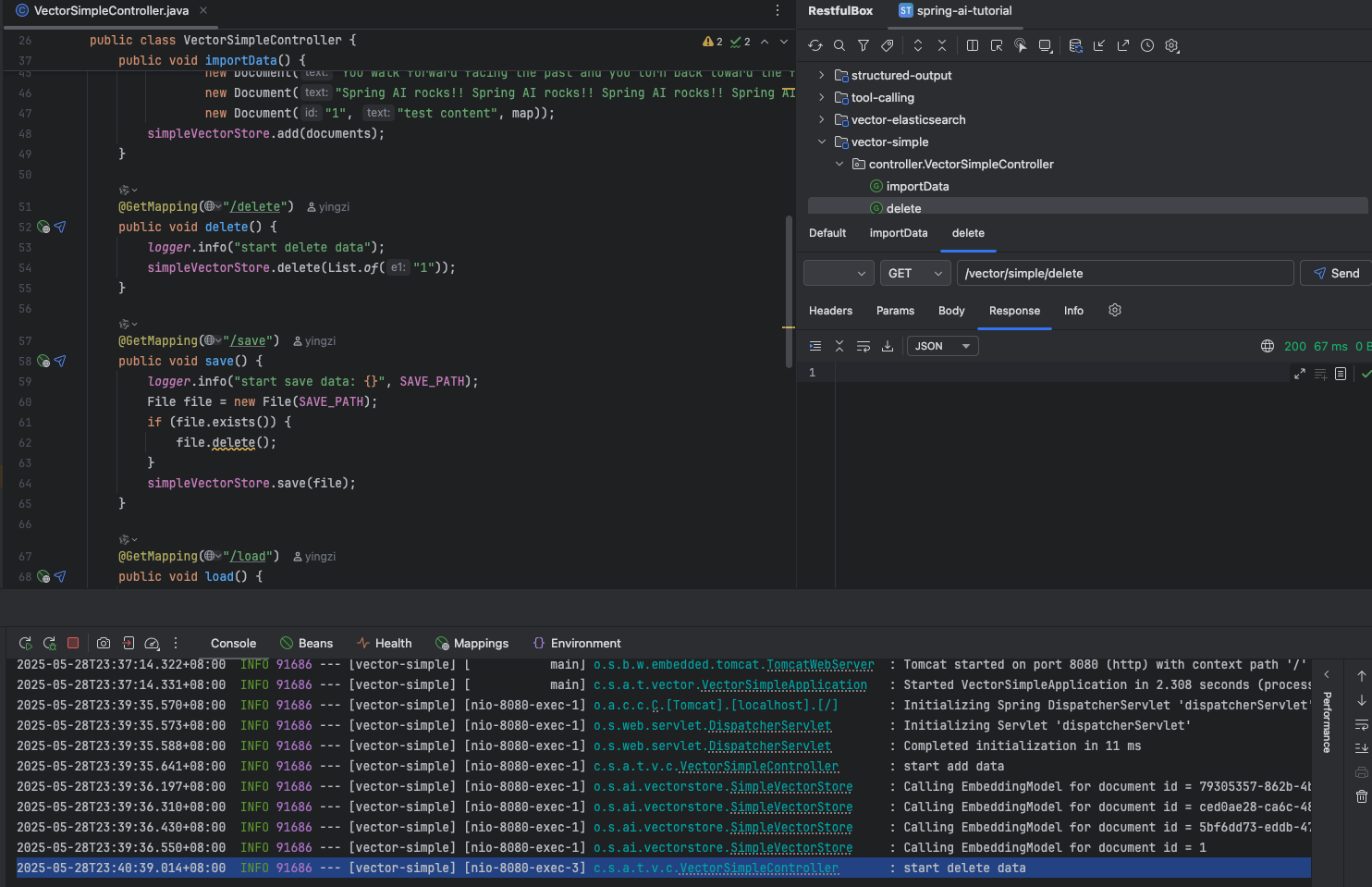
将内存里数据保存到本地
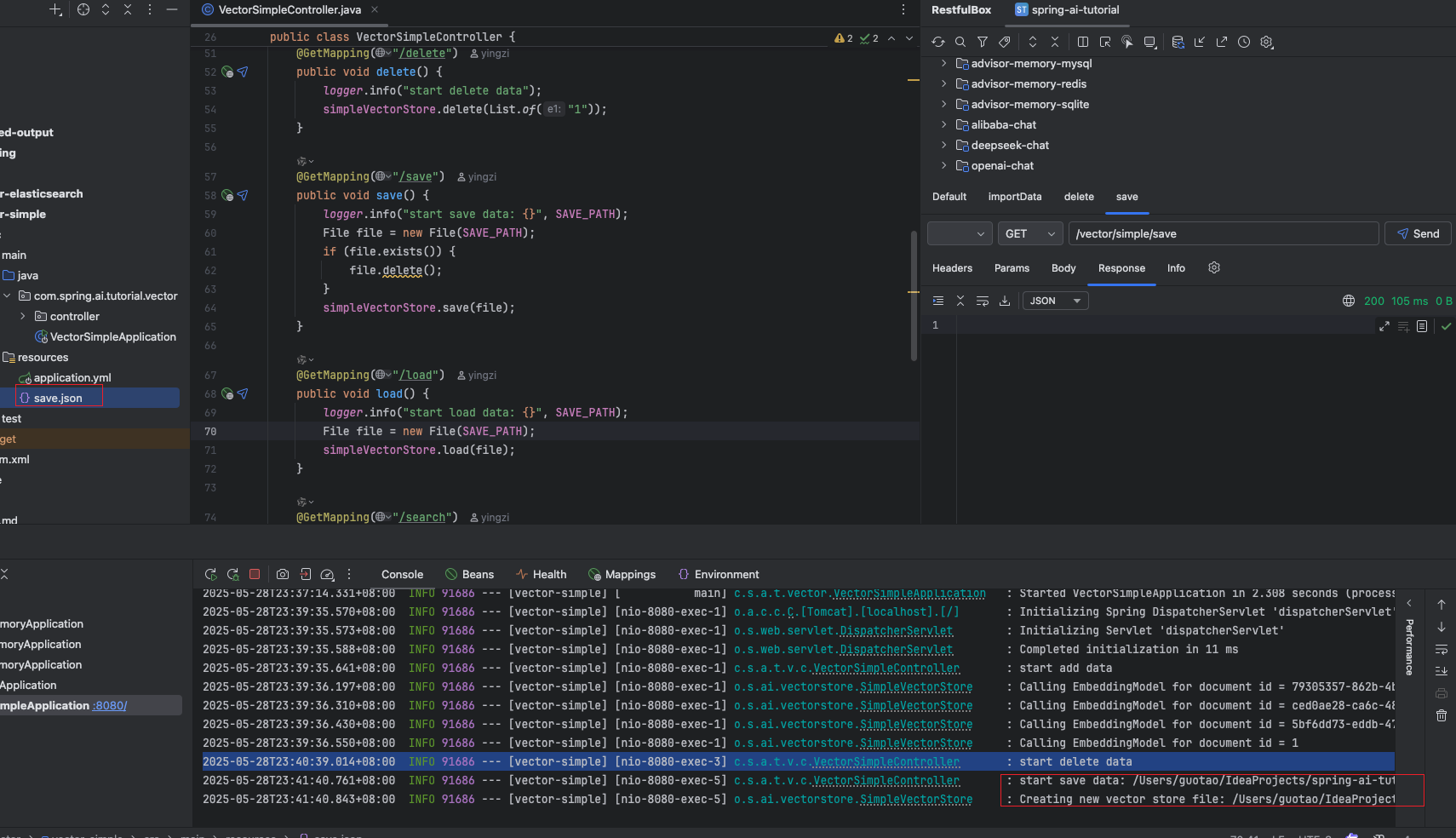
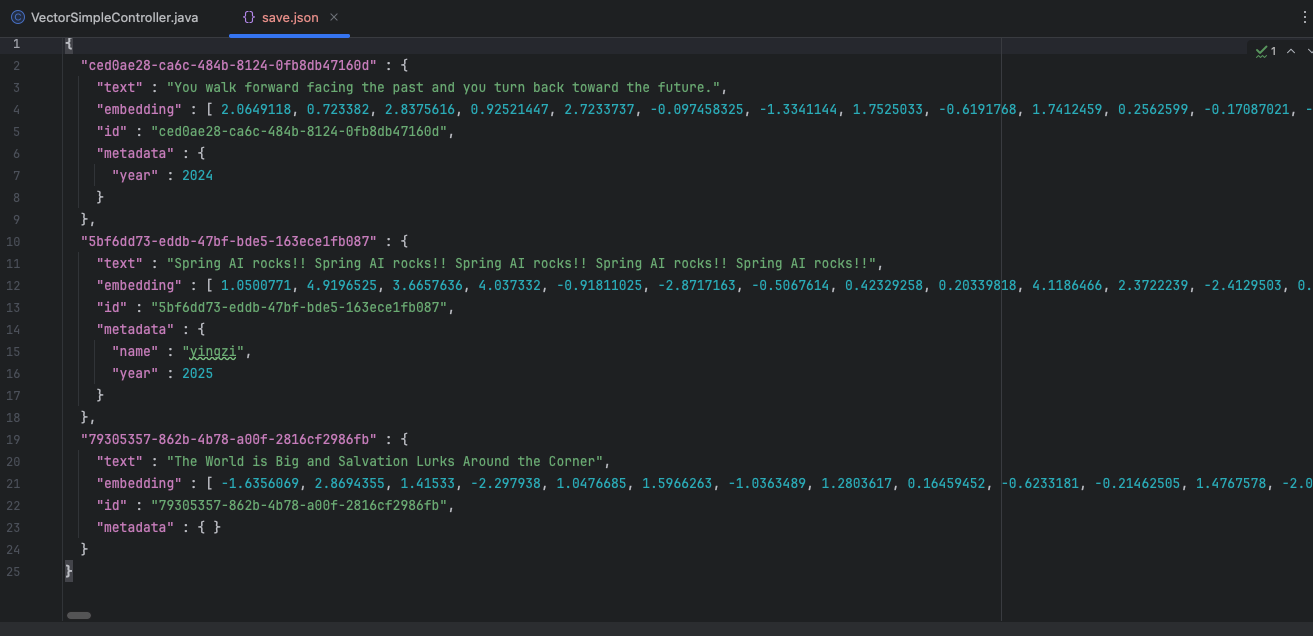
这是对应的 json 数据,可以看到只有三条数据,其中 id=1 的数据被删除了
现在让我们重启服务,并调用 load 接口,重新从本地文件中加载数据到内存
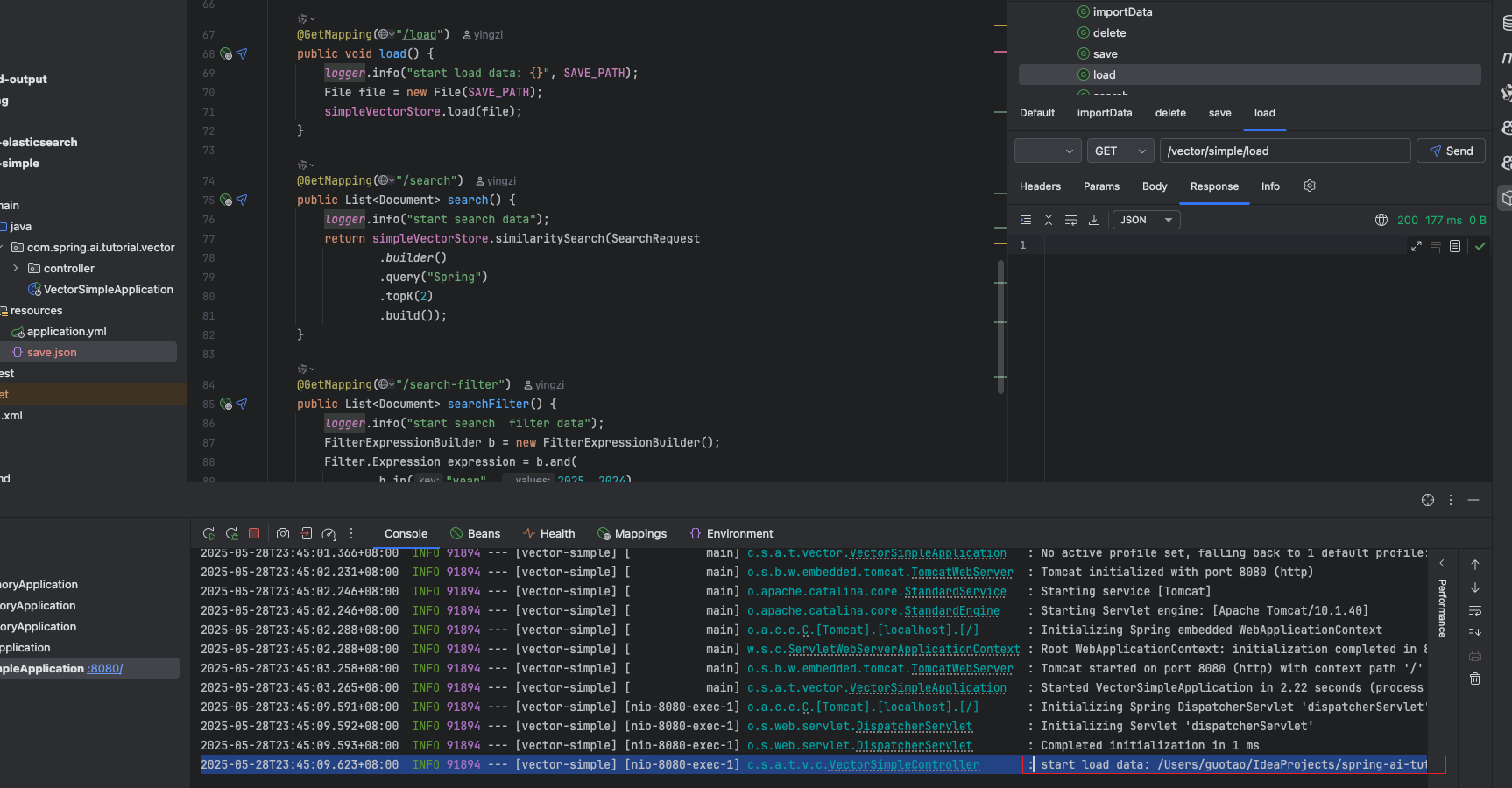
调用 search 查询数据
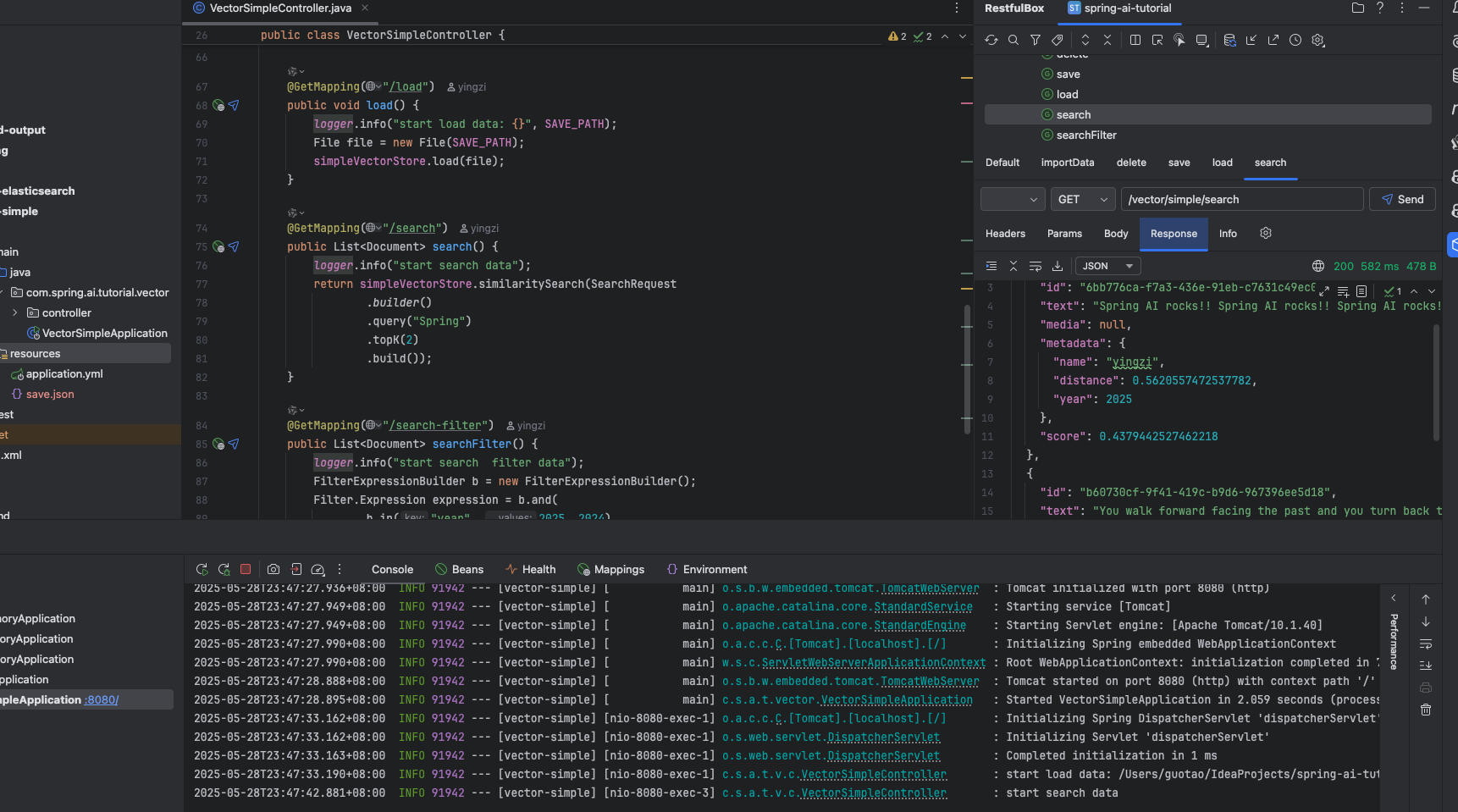
查询已经被过滤的数据
Redis
Redis 的向量存储模块源码解读可见下文
Redis 的向量查询需要用到 RediSearch,这里附上 Docker 镜像启动方式
docker run -d \ --name redis-redisearch \ -p 6379:6379 \ redislabs/redisearch:latestpom 依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-redis</artifactId> </dependency>application.yml
Redisserver: port: 8080
spring: application: name: vector-redis
ai: openai: api-key: ${DASHSCOPEAPIKEY} base-url: https://dashscope.aliyuncs.com/compatible-mode embedding: options: model: text-embedding-v1
vectorstore: redis: initialize-schema: true prefix: prefixyingzi index-name: indexyingzi
data: redis: host: localhost port: 6379 # Redis服务器连接端口RedisConfig
package com.spring.ai.tutorial.vector.config;
import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.embedding.TokenCountBatchingStrategy;import org.springframework.ai.vectorstore.redis.RedisVectorStore;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;import redis.clients.jedis.JedisPooled;
@Configurationpublic class RedisConfig {
private static final Logger logger = LoggerFactory.getLogger(RedisConfig.class);
@Value("${spring.data.redis.host}") private String host; @Value("${spring.data.redis.port}") private int port; @Value("${spring.ai.vectorstore.redis.prefix}") private String prefix; @Value("${spring.ai.vectorstore.redis.index-name}") private String indexName;
@Bean public JedisPooled jedisPooled() { logger.info("Redis host: {}, port: {}", host, port); return new JedisPooled(host, port); }
@Bean @Qualifier("redisVectorStoreCustom") public RedisVectorStore vectorStore(JedisPooled jedisPooled, EmbeddingModel embeddingModel) { logger.info("create redis vector store"); return RedisVectorStore.builder(jedisPooled, embeddingModel) .indexName(indexName) // Optional: defaults to "spring-ai-index" .prefix(prefix) // Optional: defaults to "embedding:" .metadataFields( // Optional: define metadata fields for filtering RedisVectorStore.MetadataField.tag("name"), RedisVectorStore.MetadataField.numeric("year")) .initializeSchema(true) // Optional: defaults to false .batchingStrategy(new TokenCountBatchingStrategy()) // Optional: defaults to TokenCountBatchingStrategy .build(); }
}RedisController
package com.spring.ai.tutorial.vector.controller;
import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;import org.springframework.ai.vectorstore.redis.RedisVectorStore;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;import java.util.List;import java.util.Map;
@RestController@RequestMapping("/redis")public class RedisController {
private static final Logger logger = LoggerFactory.getLogger(RedisController.class); private final RedisVectorStore redisVectorStore;
@Autowired public RedisController(@Qualifier("redisVectorStoreCustom") RedisVectorStore redisVectorStore) { this.redisVectorStore = redisVectorStore; }
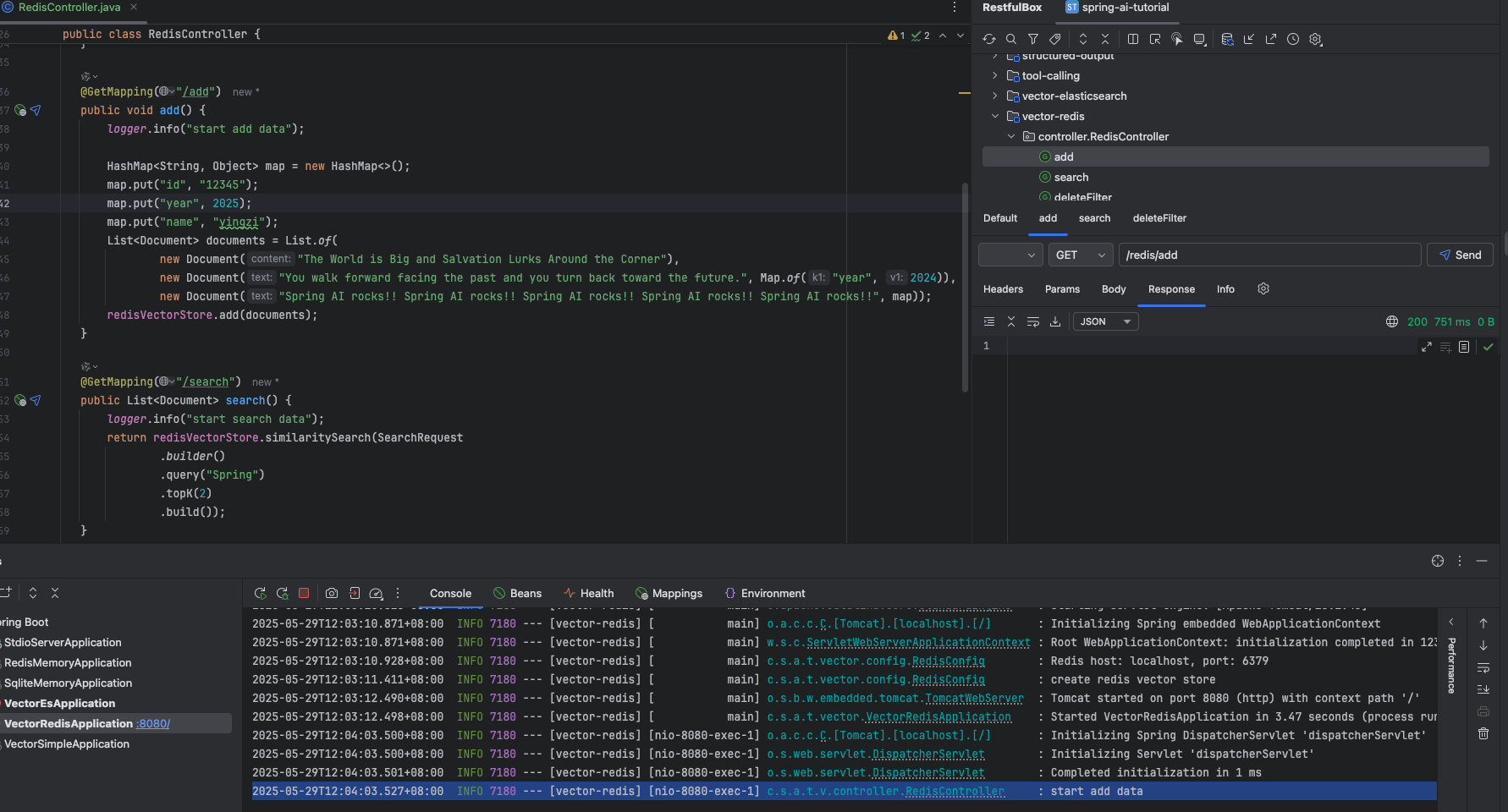
@GetMapping("/add") public void add() { logger.info("start add data");
HashMap<String, Object> map = new HashMap<>(); map.put("id", "12345"); map.put("year", 2025); map.put("name", "yingzi"); List<Document> documents = List.of( new Document("The World is Big and Salvation Lurks Around the Corner"), new Document("You walk forward facing the past and you turn back toward the future.", Map.of("year", 2024)), new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", map)); redisVectorStore.add(documents); }
@GetMapping("/search") public List<Document> search() { logger.info("start search data"); return redisVectorStore.similaritySearch(SearchRequest .builder() .query("Spring") .topK(2) .build()); }
@GetMapping("delete-filter") public void searchFilter() { logger.info("start delete data with filter"); FilterExpressionBuilder b = new FilterExpressionBuilder(); Filter.Expression expression = b.eq("name", "yingzi").build();
redisVectorStore.delete(expression); }}效果
向 Redis 中添加数据
在 Redis 中查看数据
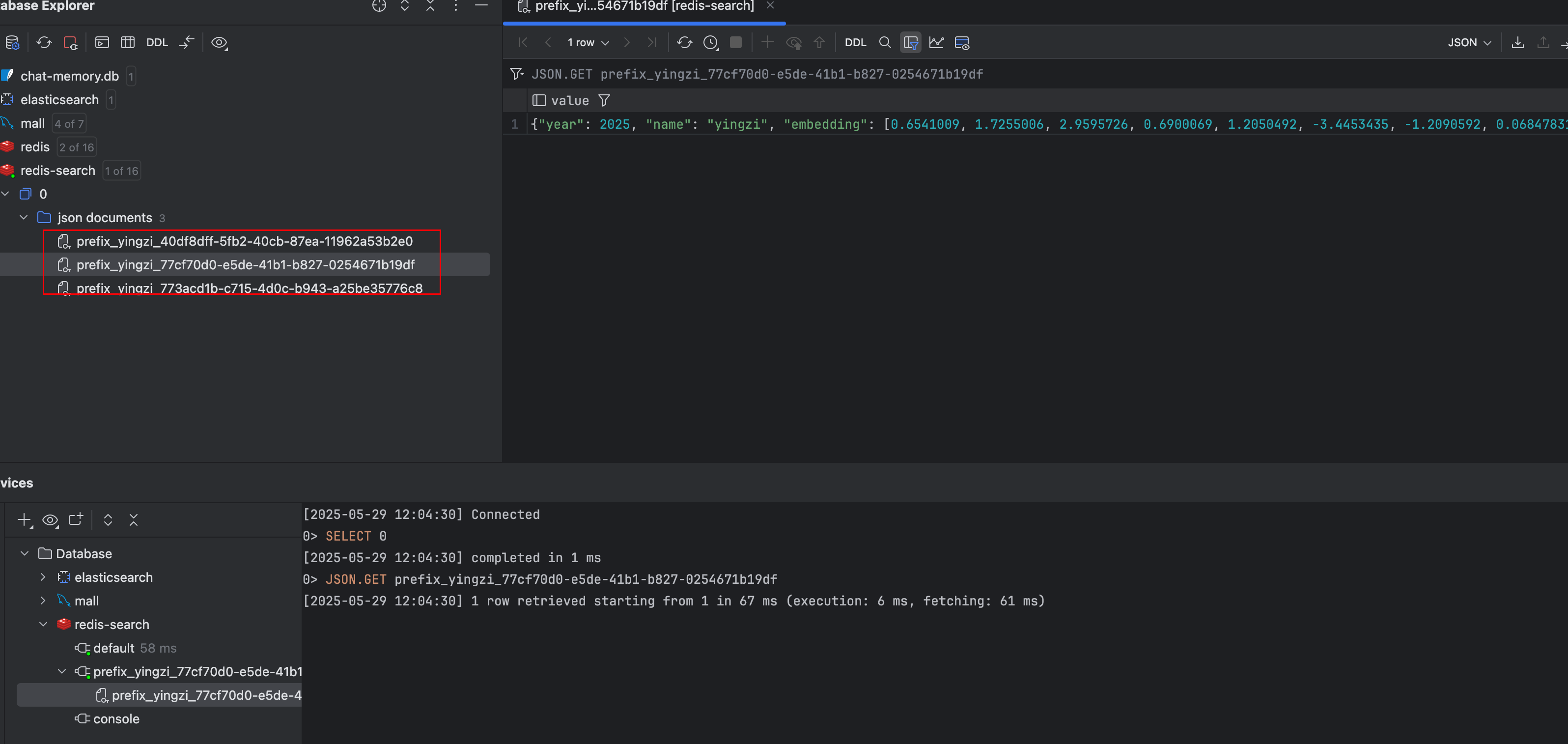
利用 Redis,进行向量查询
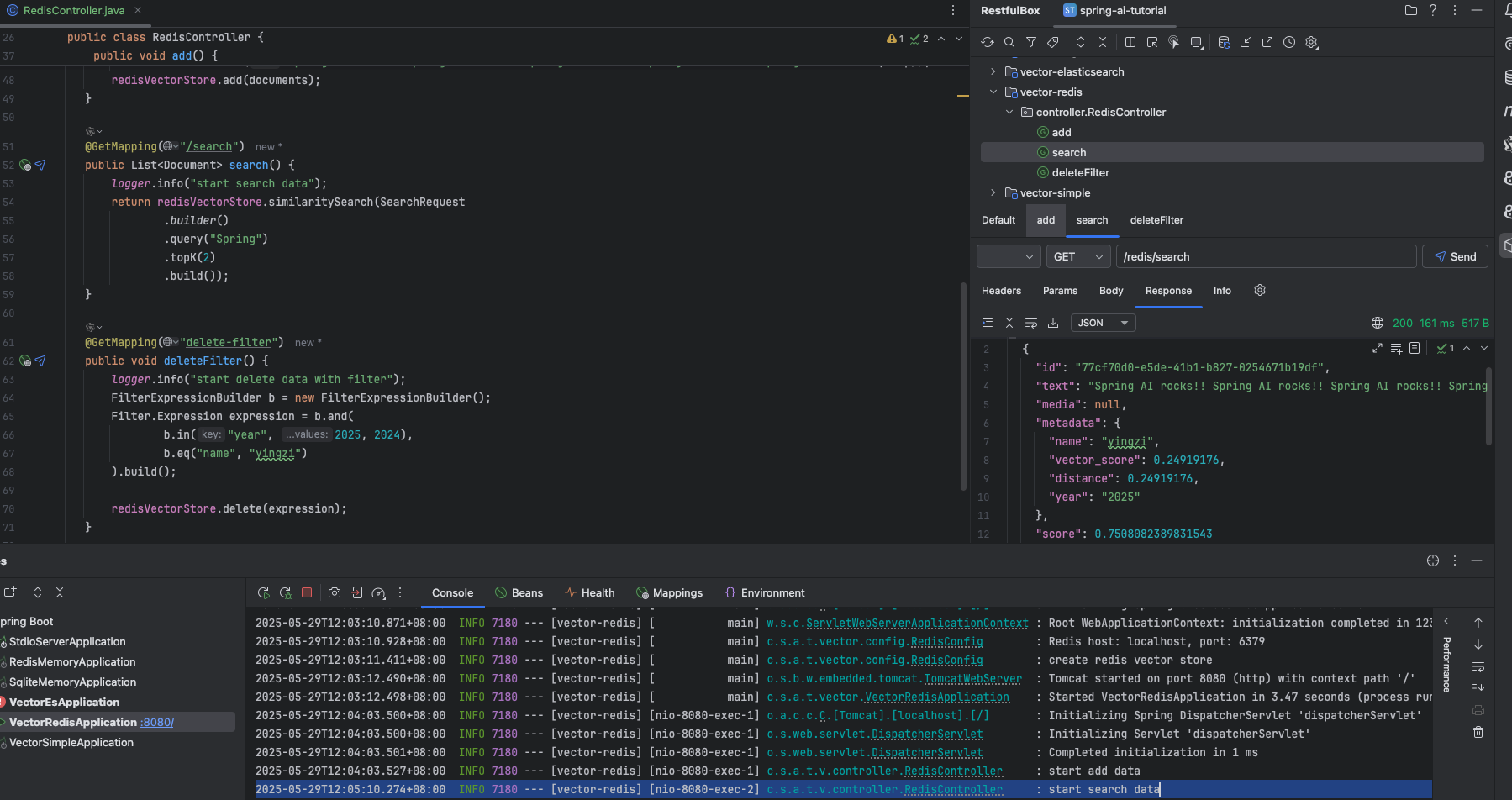
删除 year 大于等于 2024 && name 为”yinzgi”的数据
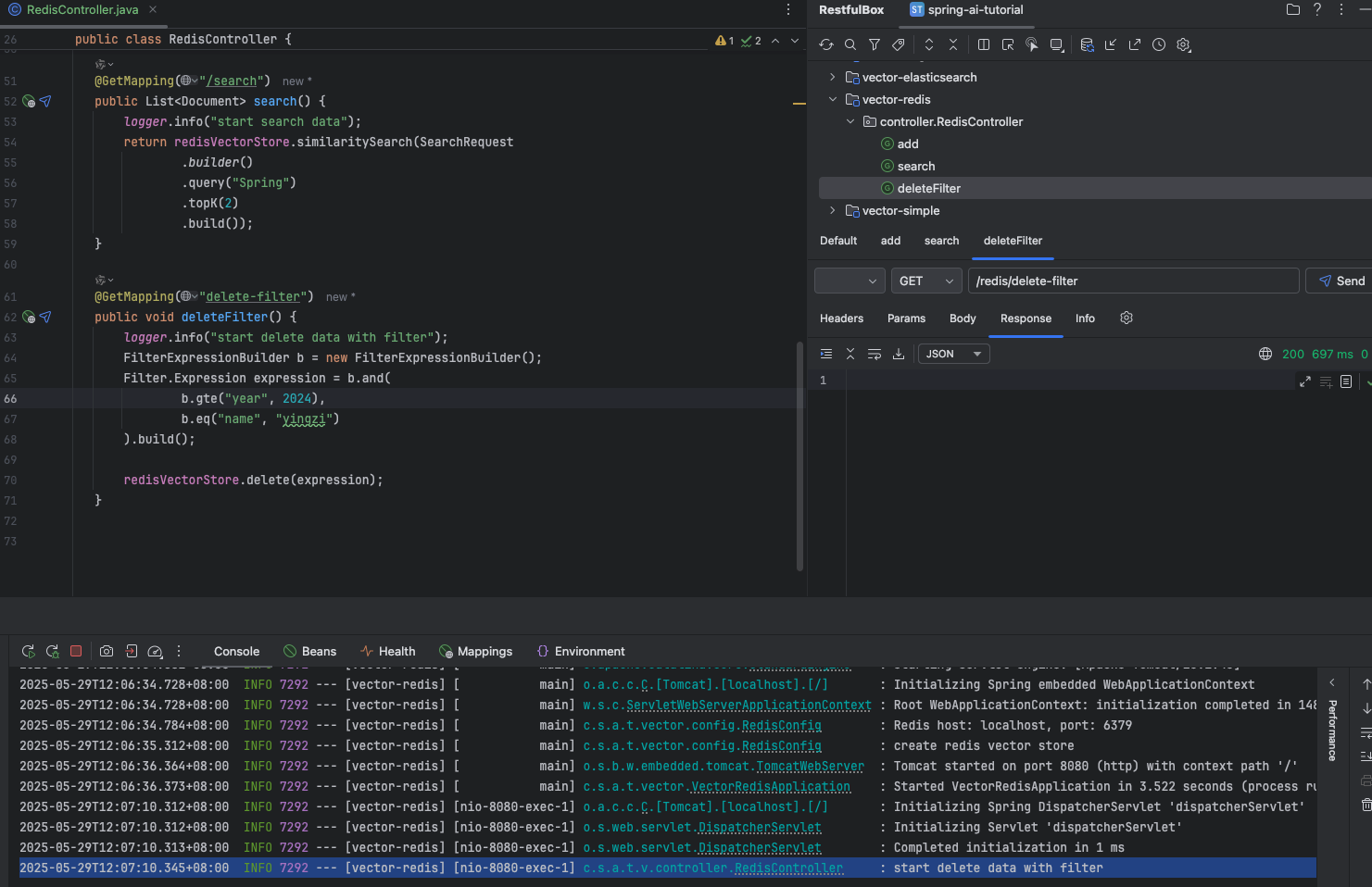
数据已被删除
Elasticsearch
Elasticsearch 的向量存储模块源码解读可见下文
pom 依赖
<properties> <es.version>8.17.4</es.version> </properties>
// 额外添加的es依赖 <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId> </dependency>
<dependency> <groupId>co.elastic.clients</groupId> <artifactId>elasticsearch-java</artifactId> <version>${es.version}</version> <scope>compile</scope> </dependency>application.yml
server: port: 8080
spring: application: name: vector-elasticsearch
ai: openai: api-key: ${DASHSCOPEAPIKEY} base-url: https://dashscope.aliyuncs.com/compatible-mode embedding: options: model: text-embedding-v1
vectorstore: elasticsearch: initialize-schema: true index-name: yingzi similarity: cosine dimensions: 1536
elasticsearch: uris: http://127.0.0.1:9200 username: elastic password: yingziElasticsearchConfig
package com.spring.ai.tutorial.vector.config;
import org.apache.http.HttpHost;import org.apache.http.auth.AuthScope;import org.apache.http.auth.UsernamePasswordCredentials;import org.apache.http.client.CredentialsProvider;import org.apache.http.impl.client.BasicCredentialsProvider;import org.elasticsearch.client.RestClient;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.embedding.TokenCountBatchingStrategy;import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore;import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStoreOptions;import org.springframework.ai.vectorstore.elasticsearch.SimilarityFunction;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.beans.factory.annotation.Value;import org.springframework.context.annotation.Bean;import org.springframework.context.annotation.Configuration;
@Configurationpublic class ElasticsearchConfig {
private static final Logger logger = LoggerFactory.getLogger(ElasticsearchConfig.class);
@Value("${spring.elasticsearch.uris}") private String url; @Value("${spring.elasticsearch.username}") private String username; @Value("${spring.elasticsearch.password}") private String password;
@Value("${spring.ai.vectorstore.elasticsearch.index-name}") private String indexName; @Value("${spring.ai.vectorstore.elasticsearch.similarity}") private SimilarityFunction similarityFunction; @Value("${spring.ai.vectorstore.elasticsearch.dimensions}") private int dimensions;
@Bean public RestClient restClient() { // 解析URL String[] urlParts = url.split("://"); String protocol = urlParts[0]; String hostAndPort = urlParts[1]; String[] hostPortParts = hostAndPort.split(":"); String host = hostPortParts[0]; int port = Integer.parseInt(hostPortParts[1]);
// 创建凭证提供者 CredentialsProvider credentialsProvider = new BasicCredentialsProvider(); credentialsProvider.setCredentials(AuthScope.ANY, new UsernamePasswordCredentials(username, password));
logger.info("create elasticsearch rest client"); // 构建RestClient return RestClient.builder(new HttpHost(host, port, protocol)) .setHttpClientConfigCallback(httpClientBuilder -> { httpClientBuilder.setDefaultCredentialsProvider(credentialsProvider); return httpClientBuilder; }) .build(); }
@Bean @Qualifier("elasticsearchVectorStore") public ElasticsearchVectorStore vectorStore(RestClient restClient, EmbeddingModel embeddingModel) { logger.info("create elasticsearch vector store");
ElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions(); options.setIndexName(indexName); // Optional: defaults to "spring-ai-document-index" options.setSimilarity(similarityFunction); // Optional: defaults to COSINE options.setDimensions(dimensions); // Optional: defaults to model dimensions or 1536
return ElasticsearchVectorStore.builder(restClient, embeddingModel) .options(options) // Optional: use custom options .initializeSchema(true) // Optional: defaults to false .batchingStrategy(new TokenCountBatchingStrategy())// Optional: defaults to TokenCountBatchingStrategy .build(); }
}VectorEsController
package com.spring.ai.tutorial.vector.controller;
import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.FilterExpressionBuilder;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.beans.factory.annotation.Qualifier;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;import java.util.List;import java.util.Map;
@RestController@RequestMapping("/vector/es")public class VectorEsController {
private static final Logger logger = LoggerFactory.getLogger(VectorEsController.class); private final ElasticsearchVectorStore elasticsearchVectorStore;
@Autowired public VectorEsController(@Qualifier("elasticsearchVectorStore") ElasticsearchVectorStore elasticsearchVectorStore) { this.elasticsearchVectorStore = elasticsearchVectorStore; }
@GetMapping("/add") public void add() { logger.info("start import data");
HashMap<String, Object> map = new HashMap<>(); map.put("id", "12345"); map.put("year", 2025); map.put("name", "yingzi"); List<Document> documents = List.of( new Document("The World is Big and Salvation Lurks Around the Corner"), new Document("You walk forward facing the past and you turn back toward the future.", Map.of("year", 2024)), new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", map)); elasticsearchVectorStore.add(documents); }
@GetMapping("/search") public List<Document> search() { logger.info("start search data"); return elasticsearchVectorStore.similaritySearch(SearchRequest .builder() .query("Spring") .topK(2) .build()); }
@GetMapping("delete-filter") public void searchFilter() { logger.info("start search data with filter"); FilterExpressionBuilder b = new FilterExpressionBuilder(); Filter.Expression expression = b.and( b.in("year", 2025, 2024), b.eq("name", "yingzi") ).build();
elasticsearchVectorStore.delete(expression); }}效果
导入数据到 ES 中
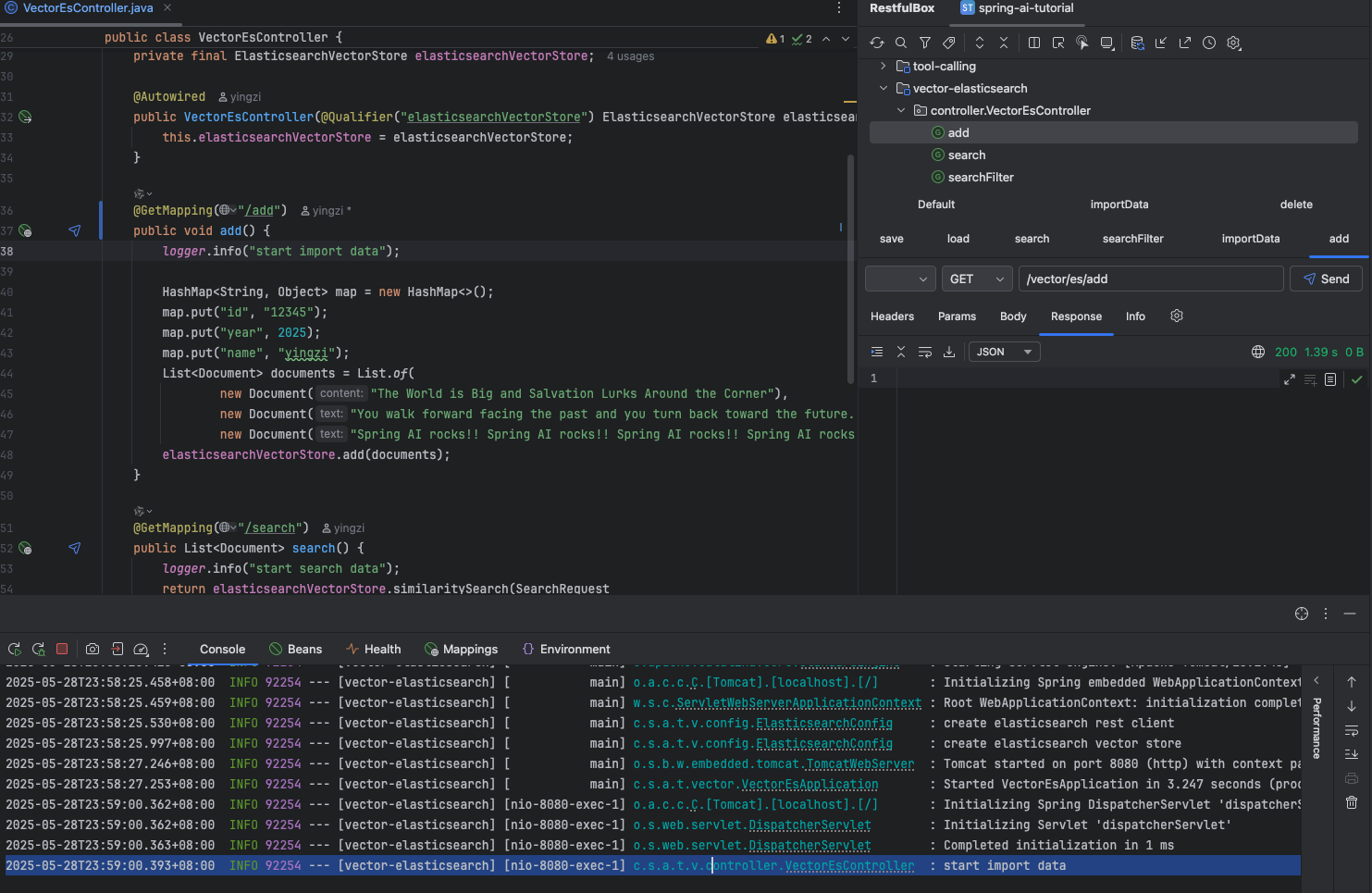
ES 中可查到对应的数据
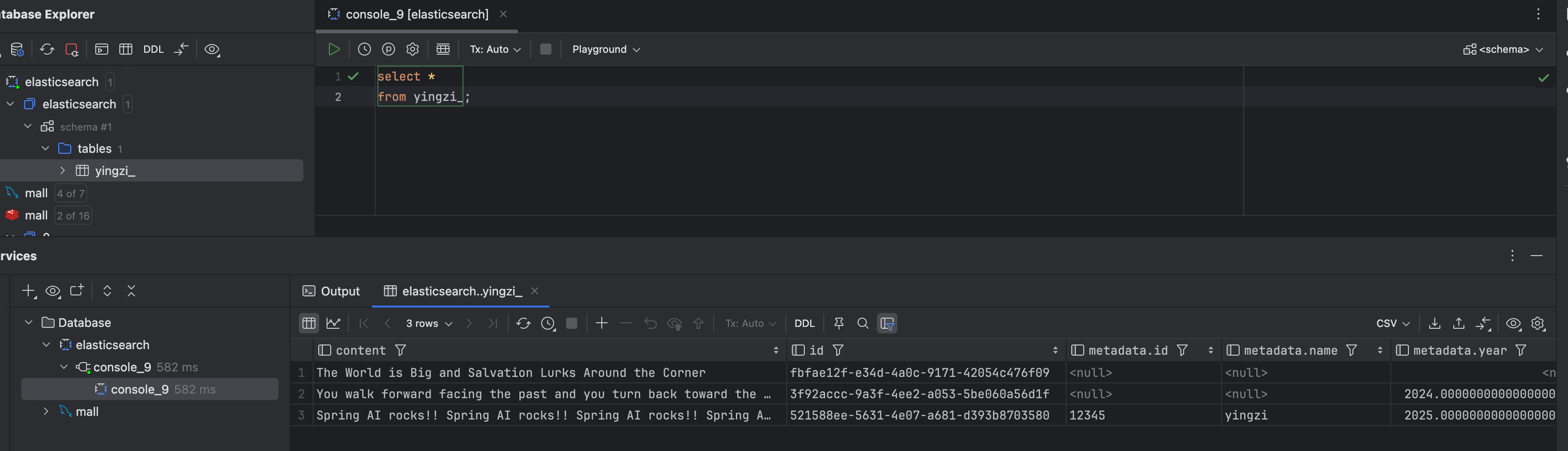
查询数据
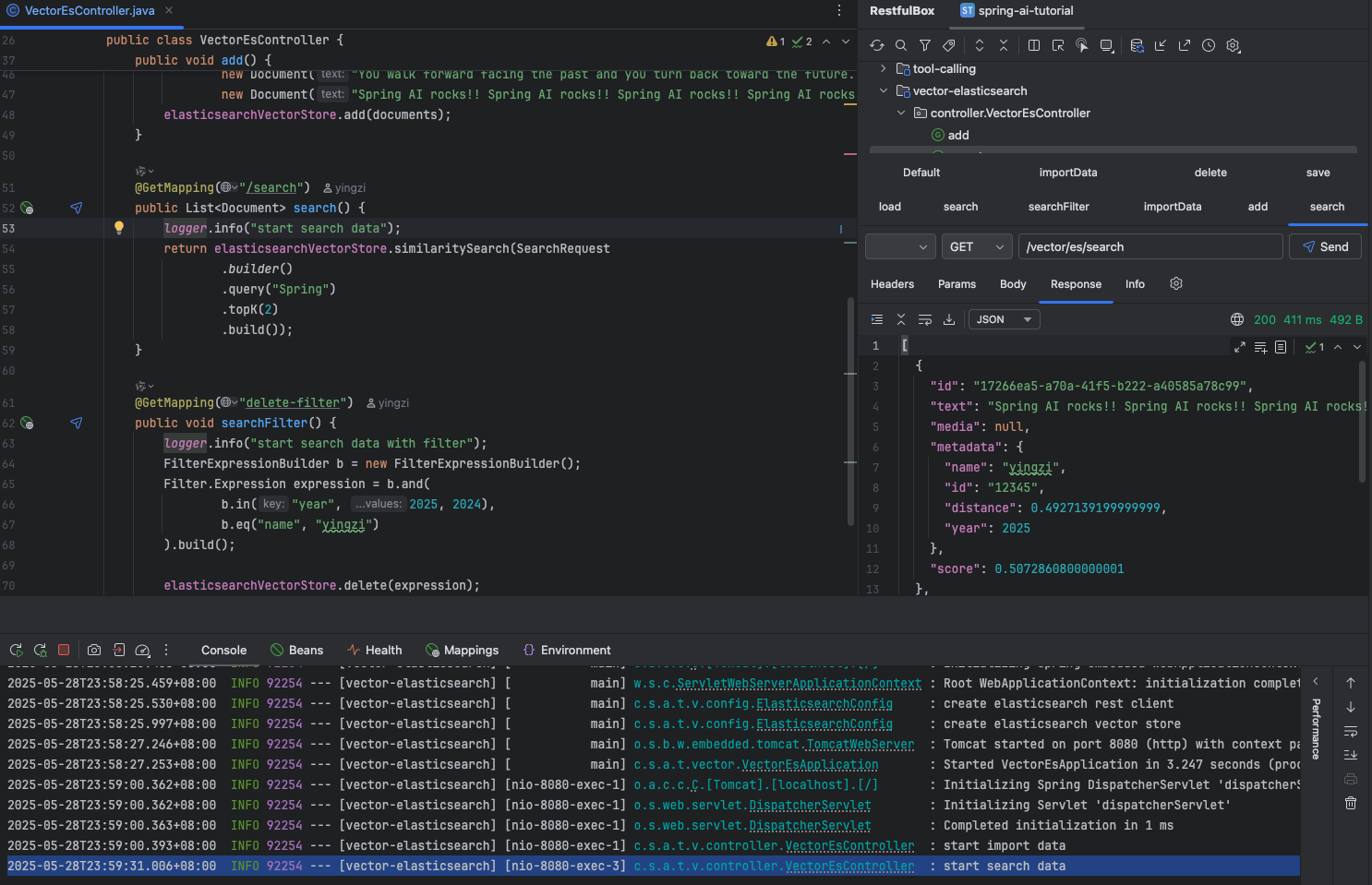
过滤删除
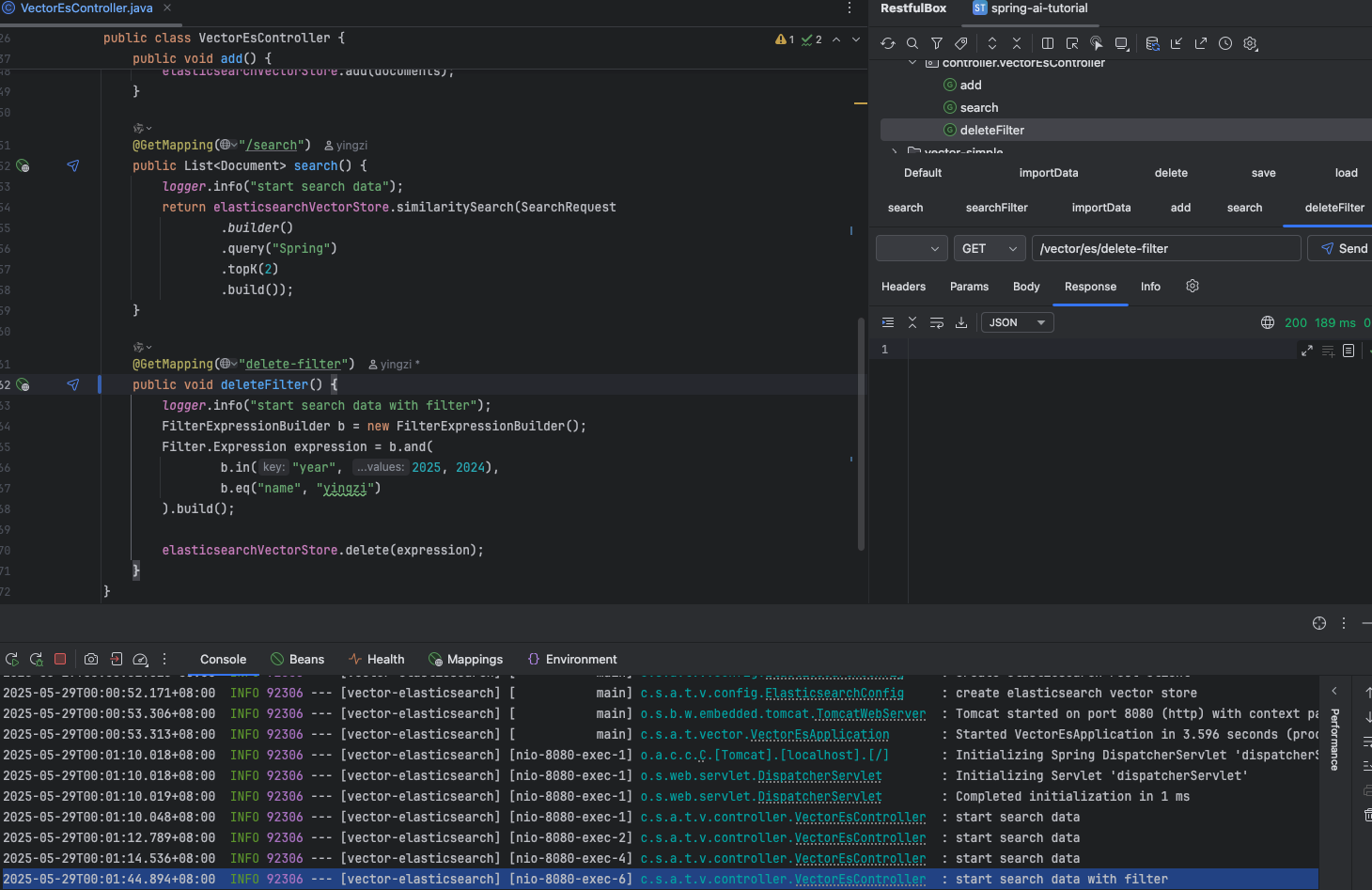
name 为 yingzi、year 为 2025 的数据被删除了
向量数据库源码解读
向量数据库,查询不同于传统的关系型数据库,执行相似性搜索而不是完全匹配。当给定一个向量作为查询时,向量数据库会返回与查询向量“相似”的向量。 Vector Databases 一般会配合 RAG 使用。本章讲解了向量数据库存储基本理论 + 基于内存实现的向量数据库
Document(文档内容)
文档内容核心类,主要用于管理和存储文档的文本或媒体内容及其元数据
作用:
- 内容管理:存储文本内容(text)或媒体内容(media),但不能同时存储两者,提供了对内容的访问和格式化功能
- 元数据管理:支持存储与文档相关的元数据,值限制为简单类型(如字符串、整数、浮点数、布尔值),以便与向量数据库兼容
- 唯一标识:每个文档的唯一 Id,当未指定时会随机生成 UUID.randomUUID().toString()
- 评分机制:为文档设置一个评分,用于表示文档的相似性
package org.springframework.ai.document;
import com.fasterxml.jackson.annotation.JsonCreator;import com.fasterxml.jackson.annotation.JsonIgnore;import com.fasterxml.jackson.annotation.JsonIgnoreProperties;import com.fasterxml.jackson.annotation.JsonProperty;import com.fasterxml.jackson.annotation.JsonCreator.Mode;import java.util.HashMap;import java.util.Map;import java.util.Objects;import org.springframework.ai.content.Media;import org.springframework.ai.document.id.IdGenerator;import org.springframework.ai.document.id.RandomIdGenerator;import org.springframework.lang.Nullable;import org.springframework.util.Assert;import org.springframework.util.StringUtils;
@JsonIgnoreProperties({"contentFormatter", "embedding"})public class Document { public static final ContentFormatter DEFAULTCONTENTFORMATTER = DefaultContentFormatter.defaultConfig(); private final String id;
private final String text; private final Media media; private final Map<String, Object> metadata; @Nullable private final Double score; @JsonIgnore private ContentFormatter contentFormatter;
@JsonCreator( mode = Mode.PROPERTIES ) public Document(@JsonProperty("content") String content) { this((String)content, new HashMap()); }
public Document(String text, Map<String, Object> metadata) { this((new RandomIdGenerator()).generateId(new Object[0]), text, (Media)null, metadata, (Double)null); }
public Document(String id, String text, Map<String, Object> metadata) { this(id, text, (Media)null, metadata, (Double)null); }
public Document(Media media, Map<String, Object> metadata) { this((new RandomIdGenerator()).generateId(new Object[0]), (String)null, media, metadata, (Double)null); }
public Document(String id, Media media, Map<String, Object> metadata) { this(id, (String)null, media, metadata, (Double)null); }
private Document(String id, String text, Media media, Map<String, Object> metadata, @Nullable Double score) { this.contentFormatter = DEFAULTCONTENTFORMATTER; Assert.hasText(id, "id cannot be null or empty"); Assert.notNull(metadata, "metadata cannot be null"); Assert.noNullElements(metadata.keySet(), "metadata cannot have null keys"); Assert.noNullElements(metadata.values(), "metadata cannot have null values"); Assert.isTrue(text != null ^ media != null, "exactly one of text or media must be specified"); this.id = id; this.text = text; this.media = media; this.metadata = new HashMap(metadata); this.score = score; }
public static Builder builder() { return new Builder(); }
public String getId() { return this.id; }
@Nullable public String getText() { return this.text; }
public boolean isText() { return this.text != null; }
@Nullable public Media getMedia() { return this.media; }
@JsonIgnore public String getFormattedContent() { return this.getFormattedContent(MetadataMode.ALL); }
public String getFormattedContent(MetadataMode metadataMode) { Assert.notNull(metadataMode, "Metadata mode must not be null"); return this.contentFormatter.format(this, metadataMode); }
public String getFormattedContent(ContentFormatter formatter, MetadataMode metadataMode) { Assert.notNull(formatter, "formatter must not be null"); Assert.notNull(metadataMode, "Metadata mode must not be null"); return formatter.format(this, metadataMode); }
public Map<String, Object> getMetadata() { return this.metadata; }
@Nullable public Double getScore() { return this.score; }
public ContentFormatter getContentFormatter() { return this.contentFormatter; }
public void setContentFormatter(ContentFormatter contentFormatter) { this.contentFormatter = contentFormatter; }
public Builder mutate() { return (new Builder()).id(this.id).text(this.text).media(this.media).metadata(this.metadata).score(this.score); }
public boolean equals(Object o) { if (o != null && this.getClass() == o.getClass()) { Document document = (Document)o; return Objects.equals(this.id, document.id) && Objects.equals(this.text, document.text) && Objects.equals(this.media, document.media) && Objects.equals(this.metadata, document.metadata) && Objects.equals(this.score, document.score); } else { return false; } }
public int hashCode() { return Objects.hash(new Object[]{this.id, this.text, this.media, this.metadata, this.score}); }
public String toString() { String var10000 = this.id; return "Document{id='" + var10000 + "', text='" + this.text + "', media='" + String.valueOf(this.media) + "', metadata=" + String.valueOf(this.metadata) + ", score=" + this.score + "}"; }
public static class Builder { private String id; private String text; private Media media; private Map<String, Object> metadata = new HashMap(); @Nullable private Double score; private IdGenerator idGenerator = new RandomIdGenerator();
public Builder idGenerator(IdGenerator idGenerator) { Assert.notNull(idGenerator, "idGenerator cannot be null"); this.idGenerator = idGenerator; return this; }
public Builder id(String id) { Assert.hasText(id, "id cannot be null or empty"); this.id = id; return this; }
public Builder text(@Nullable String text) { this.text = text; return this; }
public Builder media(@Nullable Media media) { this.media = media; return this; }
public Builder metadata(Map<String, Object> metadata) { Assert.notNull(metadata, "metadata cannot be null"); this.metadata = metadata; return this; }
public Builder metadata(String key, Object value) { Assert.notNull(key, "metadata key cannot be null"); Assert.notNull(value, "metadata value cannot be null"); this.metadata.put(key, value); return this; }
public Builder score(@Nullable Double score) { this.score = score; return this; }
public Document build() { if (!StringUtils.hasText(this.id)) { this.id = this.idGenerator.generateId(new Object[]{this.text, this.metadata}); }
return new Document(this.id, this.text, this.media, this.metadata, this.score); } }}DocumentWriter
该接口定义了一种写入 Document 列表的行为,
package org.springframework.ai.document;
import java.util.List;import java.util.function.Consumer;
public interface DocumentWriter extends Consumer<List<Document>> { default void write(List<Document> documents) { this.accept(documents); }}BatchingStrategy(文档堆处理策略接口类)
定义将 Document 列表拆分为几个批次
public interface BatchingStrategy { List<List<Document>> batch(List<Document> documents);}TokenCountBatchingStrategy
基于文档的 token 计数将 Document 列表对象分配处理,确保每个批次的 token 总数不超过指定的最大 token 数,对缓冲区进行管理,通过设置 reservePercentage 参数(默认为 0.1),为每个批次保留一定比例的 token 数量,以应对处理过程中可能出现的 token 数量增加
tokenCountEstimator: 用于估算文档内容的 token 数maxInputTokenCount: 实际允许的最大输入 token 数,默认为 8191contentFormatter: 格式化文档内容的工具metadataMode: 指定如何处理文档的元数据。
package org.springframework.ai.embedding;
import com.knuddels.jtokkit.api.EncodingType;import java.util.ArrayList;import java.util.LinkedHashMap;import java.util.List;import java.util.Map;import org.springframework.ai.document.ContentFormatter;import org.springframework.ai.document.Document;import org.springframework.ai.document.MetadataMode;import org.springframework.ai.tokenizer.JTokkitTokenCountEstimator;import org.springframework.ai.tokenizer.TokenCountEstimator;import org.springframework.util.Assert;
public class TokenCountBatchingStrategy implements BatchingStrategy { private static final int MAXINPUTTOKENCOUNT = 8191; private static final double DEFAULTTOKENCOUNTRESERVEPERCENTAGE = 0.1; private final TokenCountEstimator tokenCountEstimator; private final int maxInputTokenCount; private final ContentFormatter contentFormatter; private final MetadataMode metadataMode;
public TokenCountBatchingStrategy() { this(EncodingType.CL100KBASE, 8191, 0.1); }
public TokenCountBatchingStrategy(EncodingType encodingType, int maxInputTokenCount, double reservePercentage) { this(encodingType, maxInputTokenCount, reservePercentage, Document.DEFAULTCONTENTFORMATTER, MetadataMode.NONE); }
public TokenCountBatchingStrategy(EncodingType encodingType, int maxInputTokenCount, double reservePercentage, ContentFormatter contentFormatter, MetadataMode metadataMode) { Assert.notNull(encodingType, "EncodingType must not be null"); Assert.isTrue(maxInputTokenCount > 0, "MaxInputTokenCount must be greater than 0"); Assert.isTrue(reservePercentage >= (double)0.0F && reservePercentage < (double)1.0F, "ReservePercentage must be in range [0, 1)"); Assert.notNull(contentFormatter, "ContentFormatter must not be null"); Assert.notNull(metadataMode, "MetadataMode must not be null"); this.tokenCountEstimator = new JTokkitTokenCountEstimator(encodingType); this.maxInputTokenCount = (int)Math.round((double)maxInputTokenCount * ((double)1.0F - reservePercentage)); this.contentFormatter = contentFormatter; this.metadataMode = metadataMode; }
public TokenCountBatchingStrategy(TokenCountEstimator tokenCountEstimator, int maxInputTokenCount, double reservePercentage, ContentFormatter contentFormatter, MetadataMode metadataMode) { Assert.notNull(tokenCountEstimator, "TokenCountEstimator must not be null"); Assert.isTrue(maxInputTokenCount > 0, "MaxInputTokenCount must be greater than 0"); Assert.isTrue(reservePercentage >= (double)0.0F && reservePercentage < (double)1.0F, "ReservePercentage must be in range [0, 1)"); Assert.notNull(contentFormatter, "ContentFormatter must not be null"); Assert.notNull(metadataMode, "MetadataMode must not be null"); this.tokenCountEstimator = tokenCountEstimator; this.maxInputTokenCount = (int)Math.round((double)maxInputTokenCount * ((double)1.0F - reservePercentage)); this.contentFormatter = contentFormatter; this.metadataMode = metadataMode; }
public List<List<Document>> batch(List<Document> documents) { List<List<Document>> batches = new ArrayList(); int currentSize = 0; List<Document> currentBatch = new ArrayList(); Map<Document, Integer> documentTokens = new LinkedHashMap();
for(Document document : documents) { int tokenCount = this.tokenCountEstimator.estimate(document.getFormattedContent(this.contentFormatter, this.metadataMode)); if (tokenCount > this.maxInputTokenCount) { throw new IllegalArgumentException("Tokens in a single document exceeds the maximum number of allowed input tokens"); }
documentTokens.put(document, tokenCount); }
for(Document document : documentTokens.keySet()) { Integer tokenCount = (Integer)documentTokens.get(document); if (currentSize + tokenCount > this.maxInputTokenCount) { batches.add(currentBatch); currentBatch = new ArrayList(); currentSize = 0; }
currentBatch.add(document); currentSize += tokenCount; }
if (!currentBatch.isEmpty()) { batches.add(currentBatch); }
return batches; }}SearchRequest(相似性搜索请求)
主要用于向量存储中的相似性搜索
query:查询文本topK:返回结果数量similarityThreshold:相似性阈值filterExpression:过滤表达式
package org.springframework.ai.vectorstore;
import java.util.Objects;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.FilterExpressionTextParser;import org.springframework.lang.Nullable;import org.springframework.util.Assert;
public class SearchRequest { public static final double SIMILARITYTHRESHOLDACCEPTALL = (double)0.0F; public static final int DEFAULTTOPK = 4; private String query = ""; private int topK = 4; private double similarityThreshold = (double)0.0F; @Nullable private Filter.Expression filterExpression;
public static Builder from(SearchRequest originalSearchRequest) { return builder().query(originalSearchRequest.getQuery()).topK(originalSearchRequest.getTopK()).similarityThreshold(originalSearchRequest.getSimilarityThreshold()).filterExpression(originalSearchRequest.getFilterExpression()); }
public SearchRequest() { }
protected SearchRequest(SearchRequest original) { this.query = original.query; this.topK = original.topK; this.similarityThreshold = original.similarityThreshold; this.filterExpression = original.filterExpression; }
public String getQuery() { return this.query; }
public int getTopK() { return this.topK; }
public double getSimilarityThreshold() { return this.similarityThreshold; }
@Nullable public Filter.Expression getFilterExpression() { return this.filterExpression; }
public boolean hasFilterExpression() { return this.filterExpression != null; }
public String toString() { String var10000 = this.query; return "SearchRequest{query='" + var10000 + "', topK=" + this.topK + ", similarityThreshold=" + this.similarityThreshold + ", filterExpression=" + String.valueOf(this.filterExpression) + "}"; }
public boolean equals(Object o) { if (this == o) { return true; } else if (o != null && this.getClass() == o.getClass()) { SearchRequest that = (SearchRequest)o; return this.topK == that.topK && Double.compare(that.similarityThreshold, this.similarityThreshold) == 0 && Objects.equals(this.query, that.query) && Objects.equals(this.filterExpression, that.filterExpression); } else { return false; } }
public int hashCode() { return Objects.hash(new Object[]{this.query, this.topK, this.similarityThreshold, this.filterExpression}); }
public static Builder builder() { return new Builder(); }
public static class Builder { private final SearchRequest searchRequest = new SearchRequest();
public Builder query(String query) { Assert.notNull(query, "Query can not be null."); this.searchRequest.query = query; return this; }
public Builder topK(int topK) { Assert.isTrue(topK >= 0, "TopK should be positive."); this.searchRequest.topK = topK; return this; }
public Builder similarityThreshold(double threshold) { Assert.isTrue(threshold >= (double)0.0F && threshold <= (double)1.0F, "Similarity threshold must be in [0,1] range."); this.searchRequest.similarityThreshold = threshold; return this; }
public Builder similarityThresholdAll() { this.searchRequest.similarityThreshold = (double)0.0F; return this; }
public Builder filterExpression(@Nullable Filter.Expression expression) { this.searchRequest.filterExpression = expression; return this; }
public Builder filterExpression(@Nullable String textExpression) { this.searchRequest.filterExpression = textExpression != null ? (new FilterExpressionTextParser()).parse(textExpression) : null; return this; }
public SearchRequest build() { return this.searchRequest; } }}VectorStore
VectorStore 接口定义了用于管理和查询向量数据库中的文档的操作。向量数据库专为 AI 应用设计,支持基于数据的向量表示进行相似性搜索,而非精确匹配。
方法说明
| 方法名称 | 描述 |
| getName | 返回当前向量存储实现的类名 |
| getNativeClient | 返回向量存储实现的原生客户端(如果可用) |
| add | 添加一组文档到向量数据库 |
| delete | 根据文档Id、过滤条件等删除文档 |
| similaritySearch | 基于文本、查询嵌入、元数据过滤条件等进行相似性查询 |
package org.springframework.ai.vectorstore;
import io.micrometer.observation.ObservationRegistry;import java.util.List;import java.util.Optional;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentWriter;import org.springframework.ai.embedding.BatchingStrategy;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.observation.VectorStoreObservationConvention;import org.springframework.lang.Nullable;import org.springframework.util.Assert;
public interface VectorStore extends DocumentWriter { default String getName() { return this.getClass().getSimpleName(); }
void add(List<Document> documents);
default void accept(List<Document> documents) { this.add(documents); }
void delete(List<String> idList);
void delete(Filter.Expression filterExpression);
default void delete(String filterExpression) { SearchRequest searchRequest = SearchRequest.builder().filterExpression(filterExpression).build(); Filter.Expression textExpression = searchRequest.getFilterExpression(); Assert.notNull(textExpression, "Filter expression must not be null"); this.delete(textExpression); }
@Nullable List<Document> similaritySearch(SearchRequest request);
@Nullable default List<Document> similaritySearch(String query) { return this.similaritySearch(SearchRequest.builder().query(query).build()); }
default <T> Optional<T> getNativeClient() { return Optional.empty(); }
public interface Builder<T extends Builder<T>> { T observationRegistry(ObservationRegistry observationRegistry);
T customObservationConvention(VectorStoreObservationConvention convention);
T batchingStrategy(BatchingStrategy batchingStrategy);
VectorStore build(); }}AbstractObservationVectorStore
实现具有观测能力的 VectorStore,通过集成 ObservationRegistry 和 VectorStoreObservationConvention,提供了对向量存储操作的观测功能,便于监控和调试
ObservationRegistry observationRegistry:用于注册和管理观测事件,支持对向量存储操作的监控观测源码解读(待补充)VectorStoreObservationConvention customObservationConvention:自定义观测约定,允许开发者扩展或修改默认的观测行为EmbeddingModel embeddingModel:向量存储核心组件,用于生成文档的向量嵌入BatchingStrategy batchingStrategy:定义批量处理策略
package org.springframework.ai.vectorstore.observation;
import io.micrometer.observation.ObservationRegistry;import java.util.List;import org.springframework.ai.document.Document;import org.springframework.ai.embedding.BatchingStrategy;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.vectorstore.AbstractVectorStoreBuilder;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.observation.VectorStoreObservationContext.Operation;import org.springframework.lang.Nullable;
public abstract class AbstractObservationVectorStore implements VectorStore { private static final VectorStoreObservationConvention DEFAULTOBSERVATIONCONVENTION = new DefaultVectorStoreObservationConvention(); private final ObservationRegistry observationRegistry; @Nullable private final VectorStoreObservationConvention customObservationConvention; protected final EmbeddingModel embeddingModel; protected final BatchingStrategy batchingStrategy;
private AbstractObservationVectorStore(EmbeddingModel embeddingModel, ObservationRegistry observationRegistry, @Nullable VectorStoreObservationConvention customObservationConvention, BatchingStrategy batchingStrategy) { this.embeddingModel = embeddingModel; this.observationRegistry = observationRegistry; this.customObservationConvention = customObservationConvention; this.batchingStrategy = batchingStrategy; }
public AbstractObservationVectorStore(AbstractVectorStoreBuilder<?> builder) { this(builder.getEmbeddingModel(), builder.getObservationRegistry(), builder.getCustomObservationConvention(), builder.getBatchingStrategy()); }
public void add(List<Document> documents) { VectorStoreObservationContext observationContext = this.createObservationContextBuilder(Operation.ADD.value()).build(); VectorStoreObservationDocumentation.AIVECTORSTORE.observation(this.customObservationConvention, DEFAULTOBSERVATIONCONVENTION, () -> observationContext, this.observationRegistry).observe(() -> this.doAdd(documents)); }
public void delete(List<String> deleteDocIds) { VectorStoreObservationContext observationContext = this.createObservationContextBuilder(Operation.DELETE.value()).build(); VectorStoreObservationDocumentation.AIVECTORSTORE.observation(this.customObservationConvention, DEFAULTOBSERVATIONCONVENTION, () -> observationContext, this.observationRegistry).observe(() -> this.doDelete(deleteDocIds)); }
public void delete(Filter.Expression filterExpression) { VectorStoreObservationContext observationContext = this.createObservationContextBuilder(Operation.DELETE.value()).build(); VectorStoreObservationDocumentation.AIVECTORSTORE.observation(this.customObservationConvention, DEFAULTOBSERVATIONCONVENTION, () -> observationContext, this.observationRegistry).observe(() -> this.doDelete(filterExpression)); }
@Nullable public List<Document> similaritySearch(SearchRequest request) { VectorStoreObservationContext searchObservationContext = this.createObservationContextBuilder(Operation.QUERY.value()).queryRequest(request).build(); return (List)VectorStoreObservationDocumentation.AIVECTORSTORE.observation(this.customObservationConvention, DEFAULTOBSERVATIONCONVENTION, () -> searchObservationContext, this.observationRegistry).observe(() -> { List<Document> documents = this.doSimilaritySearch(request); searchObservationContext.setQueryResponse(documents); return documents; }); }
public abstract void doAdd(List<Document> documents);
public abstract void doDelete(List<String> idList);
protected void doDelete(Filter.Expression filterExpression) { throw new UnsupportedOperationException(); }
public abstract List<Document> doSimilaritySearch(SearchRequest request);
public abstract VectorStoreObservationContext.Builder createObservationContextBuilder(String operationName);}SimpleVectorStore(基于内存)
类的作用:基于内存的向量存储实现类,提供了将向量数据存储到内存中,并支持将数据序列化到文件或从文件反序列化的功能
ObjectMapper objectMapper:用于将向量存储内容进行 JSON 序列化/反序列化ExpressionParser expressionParser:解析过滤表达式,支持对向量存储内容进行条件过滤FilterExpressionConverter filterExpressionConverter:将过滤表达式转换为可执行的表达式,用于过滤向量存储内容Map<String, SimpleVectorStoreContent> store:存储向量数据的核心数据结构
对外暴露的方法
| 方法名 | 描述 |
| doAdd | 添加一组文档到向量存储,调用嵌入模型生成嵌入向量并存储在内存中 |
| doDelete | 根据文档 ID 删除存储中的文档 |
| doSimilaritySearch | 基于查询嵌入和过滤条件进行相似性搜索,返回匹配的文档列表 |
| save | 将向量存储内容序列化为 JSON 格式并保存到文件 |
| load | 从资源加载向量存储内容并反序列化到内存 |
| createObservationContextBuilder | 创建观察上下文构建器,用于记录操作信息 |
package org.springframework.ai.vectorstore;
import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jackson.core.type.TypeReference;import com.fasterxml.jackson.databind.ObjectMapper;import com.fasterxml.jackson.databind.ObjectWriter;import com.fasterxml.jackson.databind.json.JsonMapper;import java.io.File;import java.io.FileOutputStream;import java.io.IOException;import java.io.OutputStream;import java.io.OutputStreamWriter;import java.io.Writer;import java.nio.charset.StandardCharsets;import java.nio.file.FileAlreadyExistsException;import java.nio.file.Files;import java.util.Comparator;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Objects;import java.util.concurrent.ConcurrentHashMap;import java.util.function.Predicate;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.observation.conventions.VectorStoreProvider;import org.springframework.ai.observation.conventions.VectorStoreSimilarityMetric;import org.springframework.ai.util.JacksonUtils;import org.springframework.ai.vectorstore.filter.FilterExpressionConverter;import org.springframework.ai.vectorstore.filter.converter.SimpleVectorStoreFilterExpressionConverter;import org.springframework.ai.vectorstore.observation.AbstractObservationVectorStore;import org.springframework.ai.vectorstore.observation.VectorStoreObservationContext;import org.springframework.core.io.Resource;import org.springframework.expression.ExpressionParser;import org.springframework.expression.spel.standard.SpelExpressionParser;import org.springframework.expression.spel.support.StandardEvaluationContext;
public class SimpleVectorStore extends AbstractObservationVectorStore { private static final Logger logger = LoggerFactory.getLogger(SimpleVectorStore.class); private final ObjectMapper objectMapper = ((JsonMapper.Builder)JsonMapper.builder().addModules(JacksonUtils.instantiateAvailableModules())).build(); private final ExpressionParser expressionParser = new SpelExpressionParser(); private final FilterExpressionConverter filterExpressionConverter = new SimpleVectorStoreFilterExpressionConverter(); protected Map<String, SimpleVectorStoreContent> store = new ConcurrentHashMap();
protected SimpleVectorStore(SimpleVectorStoreBuilder builder) { super(builder); }
public static SimpleVectorStoreBuilder builder(EmbeddingModel embeddingModel) { return new SimpleVectorStoreBuilder(embeddingModel); }
public void doAdd(List<Document> documents) { Objects.requireNonNull(documents, "Documents list cannot be null"); if (documents.isEmpty()) { throw new IllegalArgumentException("Documents list cannot be empty"); } else { for(Document document : documents) { logger.info("Calling EmbeddingModel for document id = {}", document.getId()); float[] embedding = this.embeddingModel.embed(document); SimpleVectorStoreContent storeContent = new SimpleVectorStoreContent(document.getId(), document.getText(), document.getMetadata(), embedding); this.store.put(document.getId(), storeContent); }
} }
public void doDelete(List<String> idList) { for(String id : idList) { this.store.remove(id); }
}
public List<Document> doSimilaritySearch(SearchRequest request) { Predicate<SimpleVectorStoreContent> documentFilterPredicate = this.doFilterPredicate(request); float[] userQueryEmbedding = this.getUserQueryEmbedding(request.getQuery()); return this.store.values().stream().filter(documentFilterPredicate).map((content) -> content.toDocument(SimpleVectorStore.EmbeddingMath.cosineSimilarity(userQueryEmbedding, content.getEmbedding()))).filter((document) -> document.getScore() >= request.getSimilarityThreshold()).sorted(Comparator.comparing(Document::getScore).reversed()).limit((long)request.getTopK()).toList(); }
private Predicate<SimpleVectorStoreContent> doFilterPredicate(SearchRequest request) { return request.hasFilterExpression() ? (document) -> { StandardEvaluationContext context = new StandardEvaluationContext(); context.setVariable("metadata", document.getMetadata()); return (Boolean)this.expressionParser.parseExpression(this.filterExpressionConverter.convertExpression(request.getFilterExpression())).getValue(context, Boolean.class); } : (document) -> true; }
public void save(File file) { String json = this.getVectorDbAsJson();
try { if (!file.exists()) { logger.info("Creating new vector store file: {}", file);
try { Files.createFile(file.toPath()); } catch (FileAlreadyExistsException e) { throw new RuntimeException("File already exists: " + String.valueOf(file), e); } catch (IOException e) { throw new RuntimeException("Failed to create new file: " + String.valueOf(file) + ". Reason: " + e.getMessage(), e); } } else { logger.info("Overwriting existing vector store file: {}", file); }
try ( OutputStream stream = new FileOutputStream(file); Writer writer = new OutputStreamWriter(stream, StandardCharsets.UTF8); ) { writer.write(json); writer.flush(); }
} catch (IOException ex) { logger.error("IOException occurred while saving vector store file.", ex); throw new RuntimeException(ex); } catch (SecurityException ex) { logger.error("SecurityException occurred while saving vector store file.", ex); throw new RuntimeException(ex); } catch (NullPointerException ex) { logger.error("NullPointerException occurred while saving vector store file.", ex); throw new RuntimeException(ex); } }
public void load(File file) { TypeReference<HashMap<String, SimpleVectorStoreContent>> typeRef = new TypeReference<HashMap<String, SimpleVectorStoreContent>>() { };
try { this.store = (Map)this.objectMapper.readValue(file, typeRef); } catch (IOException ex) { throw new RuntimeException(ex); } }
public void load(Resource resource) { TypeReference<HashMap<String, SimpleVectorStoreContent>> typeRef = new TypeReference<HashMap<String, SimpleVectorStoreContent>>() { };
try { this.store = (Map)this.objectMapper.readValue(resource.getInputStream(), typeRef); } catch (IOException ex) { throw new RuntimeException(ex); } }
private String getVectorDbAsJson() { ObjectWriter objectWriter = this.objectMapper.writerWithDefaultPrettyPrinter();
try { return objectWriter.writeValueAsString(this.store); } catch (JsonProcessingException e) { throw new RuntimeException("Error serializing documentMap to JSON.", e); } }
private float[] getUserQueryEmbedding(String query) { return this.embeddingModel.embed(query); }
public VectorStoreObservationContext.Builder createObservationContextBuilder(String operationName) { return VectorStoreObservationContext.builder(VectorStoreProvider.SIMPLE.value(), operationName).dimensions(this.embeddingModel.dimensions()).collectionName("in-memory-map").similarityMetric(VectorStoreSimilarityMetric.COSINE.value()); }
public static final class EmbeddingMath { private EmbeddingMath() { throw new UnsupportedOperationException("This is a utility class and cannot be instantiated"); }
public static double cosineSimilarity(float[] vectorX, float[] vectorY) { if (vectorX != null && vectorY != null) { if (vectorX.length != vectorY.length) { throw new IllegalArgumentException("Vectors lengths must be equal"); } else { float dotProduct = dotProduct(vectorX, vectorY); float normX = norm(vectorX); float normY = norm(vectorY); if (normX != 0.0F && normY != 0.0F) { return (double)dotProduct / (Math.sqrt((double)normX) * Math.sqrt((double)normY)); } else { throw new IllegalArgumentException("Vectors cannot have zero norm"); } } } else { throw new RuntimeException("Vectors must not be null"); } }
public static float dotProduct(float[] vectorX, float[] vectorY) { if (vectorX.length != vectorY.length) { throw new IllegalArgumentException("Vectors lengths must be equal"); } else { float result = 0.0F;
for(int i = 0; i < vectorX.length; ++i) { result += vectorX[i] * vectorY[i]; }
return result; } }
public static float norm(float[] vector) { return dotProduct(vector, vector); } }
public static final class SimpleVectorStoreBuilder extends AbstractVectorStoreBuilder<SimpleVectorStoreBuilder> { private SimpleVectorStoreBuilder(EmbeddingModel embeddingModel) { super(embeddingModel); }
public SimpleVectorStore build() { return new SimpleVectorStore(this); } }}Elasticsearch 的向量解读
pom 文件
引入 elasticsearch 的向量数据库依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-elasticsearch</artifactId></dependency>该 pom 中包含以下两个 elasticsearch 相关模块:
- spring-ai-autoconfigure-vector-store-elasticsearch:自动注入 elasticsearch 的相关信息
- spring-ai-elasticsearch-store:elasticsearch 向量存储类
自动注入模块
ElasticsearchVectorStoreProperties
配置默认索引、向量纬度、相似性函数、嵌入字段名
package org.springframework.ai.vectorstore.elasticsearch.autoconfigure;
import org.springframework.ai.vectorstore.elasticsearch.SimilarityFunction;import org.springframework.ai.vectorstore.properties.CommonVectorStoreProperties;import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties( prefix = "spring.ai.vectorstore.elasticsearch")public class ElasticsearchVectorStoreProperties extends CommonVectorStoreProperties { private String indexName; private Integer dimensions; private SimilarityFunction similarity; private String embeddingFieldName = "embedding";
public String getIndexName() { return this.indexName; }
public void setIndexName(String indexName) { this.indexName = indexName; }
public Integer getDimensions() { return this.dimensions; }
public void setDimensions(Integer dimensions) { this.dimensions = dimensions; }
public SimilarityFunction getSimilarity() { return this.similarity; }
public void setSimilarity(SimilarityFunction similarity) { this.similarity = similarity; }
public String getEmbeddingFieldName() { return this.embeddingFieldName; }
public void setEmbeddingFieldName(String embeddingFieldName) { this.embeddingFieldName = embeddingFieldName; }}ElasticsearchVectorStoreAutoConfiguration
用于在项目中自动配置 Elasticsearch 向量存储(ElasticsearchVectorStore)相关的 Bean
- 自动装配条件:仅在类路径中存在 ElasticsearchVectorStore、EmbeddingModel 和 RestClient 时生效,且 spring.ai.vectorstore.type 属性判断是否启用 Elasticsearch 类型的向量存储(默认启用)
- 配置属性支持:启用 ElasticsearchVectorStoreProperties,允许通过配置文件自定义 Elasticsearch 向量存储的相关参数
- 批处理策略 Bean:如果没有自定义的 BatchingStrategy,则自动注入默认的 TokenCountBatchingStrategy
- ElasticsearchVectorStore Bean:自动创建并配置 ElasticsearchVectorStore,包括连接 设置索引、纬度、相似度、批处理策略、初始化 schema、观测注册等
package org.springframework.ai.vectorstore.elasticsearch.autoconfigure;
import io.micrometer.observation.ObservationRegistry;import java.util.Objects;import org.elasticsearch.client.RestClient;import org.springframework.ai.embedding.BatchingStrategy;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.embedding.TokenCountBatchingStrategy;import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStore;import org.springframework.ai.vectorstore.elasticsearch.ElasticsearchVectorStoreOptions;import org.springframework.ai.vectorstore.observation.VectorStoreObservationConvention;import org.springframework.beans.factory.ObjectProvider;import org.springframework.boot.autoconfigure.AutoConfiguration;import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;import org.springframework.boot.autoconfigure.elasticsearch.ElasticsearchRestClientAutoConfiguration;import org.springframework.boot.context.properties.EnableConfigurationProperties;import org.springframework.boot.context.properties.PropertyMapper;import org.springframework.context.annotation.Bean;
@AutoConfiguration( after = {ElasticsearchRestClientAutoConfiguration.class})@ConditionalOnClass({ElasticsearchVectorStore.class, EmbeddingModel.class, RestClient.class})@EnableConfigurationProperties({ElasticsearchVectorStoreProperties.class})@ConditionalOnProperty( name = {"spring.ai.vectorstore.type"}, havingValue = "elasticsearch", matchIfMissing = true)public class ElasticsearchVectorStoreAutoConfiguration { @Bean @ConditionalOnMissingBean({BatchingStrategy.class}) BatchingStrategy batchingStrategy() { return new TokenCountBatchingStrategy(); }
@Bean @ConditionalOnMissingBean ElasticsearchVectorStore vectorStore(ElasticsearchVectorStoreProperties properties, RestClient restClient, EmbeddingModel embeddingModel, ObjectProvider<ObservationRegistry> observationRegistry, ObjectProvider<VectorStoreObservationConvention> customObservationConvention, BatchingStrategy batchingStrategy) { ElasticsearchVectorStoreOptions elasticsearchVectorStoreOptions = new ElasticsearchVectorStoreOptions(); PropertyMapper mapper = PropertyMapper.get(); Objects.requireNonNull(properties); PropertyMapper.Source var10000 = mapper.from(properties::getIndexName).whenHasText(); Objects.requireNonNull(elasticsearchVectorStoreOptions); var10000.to(elasticsearchVectorStoreOptions::setIndexName); Objects.requireNonNull(properties); var10000 = mapper.from(properties::getDimensions).whenNonNull(); Objects.requireNonNull(elasticsearchVectorStoreOptions); var10000.to(elasticsearchVectorStoreOptions::setDimensions); Objects.requireNonNull(properties); var10000 = mapper.from(properties::getSimilarity).whenNonNull(); Objects.requireNonNull(elasticsearchVectorStoreOptions); var10000.to(elasticsearchVectorStoreOptions::setSimilarity); return ((ElasticsearchVectorStore.Builder)((ElasticsearchVectorStore.Builder)((ElasticsearchVectorStore.Builder)ElasticsearchVectorStore.builder(restClient, embeddingModel).options(elasticsearchVectorStoreOptions).initializeSchema(properties.isInitializeSchema()).observationRegistry((ObservationRegistry)observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP))).customObservationConvention((VectorStoreObservationConvention)customObservationConvention.getIfAvailable(() -> null))).batchingStrategy(batchingStrategy)).build(); }}spring-ai-elasticsearch-store 模块
ElasticsearchVectorStore
基于 ES 的向量存储实现类
ElasticsearchClient elasticsearchClient字段:用于连接 ES 地客户端ElasticsearchVectorStoreOptions option:ES 向量存储的基本配置,包含索引名称、向量维度、相似性计算规则FilterExpressionConverter filterExpressionConverter:过滤表达式转化器,主要用于删除、相似性匹配boolean initializeSchema字段:用于初始化创建索引(设置为 True)
对外暴露的方法
| 方法名 | 描述 |
| doAdd | 添加一组文档到向量存储,调用嵌入模型生成嵌入向量并存储在内存中 |
| doDelete | 根据文档 ID 删除存储中的文档 |
| doSimilaritySearch | 基于查询嵌入和过滤条件进行相似性搜索,返回匹配的文档列表 |
| createObservationContextBuilder | 创建观察上下文构建器,用于记录操作信息 |
| indexExists | 检查 Elasticsearch 索引是否存在 |
| getNativeClient | 返回 Elasticsearch 客户端实例 |
| afterPropertiesSet | 初始化 Elasticsearch 索引架构 |
package org.springframework.ai.vectorstore.elasticsearch;
import co.elastic.clients.elasticsearch.ElasticsearchClient;import co.elastic.clients.elasticsearch.core.BulkRequest;import co.elastic.clients.elasticsearch.core.BulkResponse;import co.elastic.clients.elasticsearch.core.SearchResponse;import co.elastic.clients.elasticsearch.core.bulk.BulkResponseItem;import co.elastic.clients.elasticsearch.core.bulk.DeleteOperation;import co.elastic.clients.elasticsearch.core.bulk.IndexOperation;import co.elastic.clients.elasticsearch.core.search.Hit;import co.elastic.clients.json.jackson.JacksonJsonpMapper;import co.elastic.clients.transport.Version;import co.elastic.clients.transport.restclient.RestClientTransport;import co.elastic.clients.util.ObjectBuilder;import com.fasterxml.jackson.databind.DeserializationFeature;import com.fasterxml.jackson.databind.ObjectMapper;import java.io.IOException;import java.util.List;import java.util.Map;import java.util.Objects;import java.util.Optional;import java.util.stream.Collectors;import org.elasticsearch.client.RestClient;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentMetadata;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.embedding.EmbeddingOptionsBuilder;import org.springframework.ai.model.EmbeddingUtils;import org.springframework.ai.observation.conventions.VectorStoreProvider;import org.springframework.ai.observation.conventions.VectorStoreSimilarityMetric;import org.springframework.ai.vectorstore.AbstractVectorStoreBuilder;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.FilterExpressionConverter;import org.springframework.ai.vectorstore.observation.AbstractObservationVectorStore;import org.springframework.ai.vectorstore.observation.VectorStoreObservationContext;import org.springframework.beans.factory.InitializingBean;import org.springframework.util.Assert;
public class ElasticsearchVectorStore extends AbstractObservationVectorStore implements InitializingBean { private static final Logger logger = LoggerFactory.getLogger(ElasticsearchVectorStore.class); private static final Map<SimilarityFunction, VectorStoreSimilarityMetric> SIMILARITYTYPEMAPPING; private final ElasticsearchClient elasticsearchClient; private final ElasticsearchVectorStoreOptions options; private final FilterExpressionConverter filterExpressionConverter; private final boolean initializeSchema;
protected ElasticsearchVectorStore(Builder builder) { super(builder); Assert.notNull(builder.restClient, "RestClient must not be null"); this.initializeSchema = builder.initializeSchema; this.options = builder.options; this.filterExpressionConverter = builder.filterExpressionConverter; String version = Version.VERSION == null ? "Unknown" : Version.VERSION.toString(); this.elasticsearchClient = (ElasticsearchClient)(new ElasticsearchClient(new RestClientTransport(builder.restClient, new JacksonJsonpMapper((new ObjectMapper()).configure(DeserializationFeature.FAILONUNKNOWNPROPERTIES, false))))).withTransportOptions((t) -> t.addHeader("user-agent", "spring-ai elastic-java/" + version)); }
public void doAdd(List<Document> documents) { if (!this.indexExists()) { throw new IllegalArgumentException("Index not found"); } else { BulkRequest.Builder bulkRequestBuilder = new BulkRequest.Builder(); List<float[]> embeddings = this.embeddingModel.embed(documents, EmbeddingOptionsBuilder.builder().build(), this.batchingStrategy);
for(int i = 0; i < embeddings.size(); ++i) { Document document = (Document)documents.get(i); float[] embedding = (float[])embeddings.get(i); bulkRequestBuilder.operations((op) -> op.index((idx) -> ((IndexOperation.Builder)((IndexOperation.Builder)idx.index(this.options.getIndexName())).id(document.getId())).document(this.getDocument(document, embedding, this.options.getEmbeddingFieldName())))); }
BulkResponse bulkRequest = this.bulkRequest(bulkRequestBuilder.build()); if (bulkRequest.errors()) { for(BulkResponseItem bulkResponseItem : bulkRequest.items()) { if (bulkResponseItem.error() != null) { throw new IllegalStateException(bulkResponseItem.error().reason()); } } }
} }
private Object getDocument(Document document, float[] embedding, String embeddingFieldName) { Assert.notNull(document.getText(), "document's text must not be null"); return Map.of("id", document.getId(), "content", document.getText(), "metadata", document.getMetadata(), embeddingFieldName, embedding); }
public void doDelete(List<String> idList) { BulkRequest.Builder bulkRequestBuilder = new BulkRequest.Builder(); if (!this.indexExists()) { throw new IllegalArgumentException("Index not found"); } else { for(String id : idList) { bulkRequestBuilder.operations((op) -> op.delete((idx) -> (ObjectBuilder)((DeleteOperation.Builder)idx.index(this.options.getIndexName())).id(id))); }
if (this.bulkRequest(bulkRequestBuilder.build()).errors()) { throw new IllegalStateException("Delete operation failed"); } } }
public void doDelete(Filter.Expression filterExpression) { if (!this.indexExists()) { throw new IllegalArgumentException("Index not found"); } else { try { this.elasticsearchClient.deleteByQuery((d) -> d.index(this.options.getIndexName(), new String[0]).query((q) -> q.queryString((qs) -> qs.query(this.getElasticsearchQueryString(filterExpression))))); } catch (Exception e) { throw new IllegalStateException("Failed to delete documents by filter", e); } } }
private BulkResponse bulkRequest(BulkRequest bulkRequest) { try { return this.elasticsearchClient.bulk(bulkRequest); } catch (IOException e) { throw new RuntimeException(e); } }
public List<Document> doSimilaritySearch(SearchRequest searchRequest) { Assert.notNull(searchRequest, "The search request must not be null.");
try { float threshold = (float)searchRequest.getSimilarityThreshold(); if (this.options.getSimilarity().equals(SimilarityFunction.l2norm)) { threshold = 1.0F - threshold; }
float[] vectors = this.embeddingModel.embed(searchRequest.getQuery()); SearchResponse<Document> res = this.elasticsearchClient.search((sr) -> sr.index(this.options.getIndexName(), new String[0]).knn((knn) -> knn.queryVector(EmbeddingUtils.toList(vectors)).similarity(threshold).k(searchRequest.getTopK()).field(this.options.getEmbeddingFieldName()).numCandidates((int)((double)1.5F * (double)searchRequest.getTopK())).filter((fl) -> fl.queryString((qs) -> qs.query(this.getElasticsearchQueryString(searchRequest.getFilterExpression()))))).size(searchRequest.getTopK()), Document.class); return (List)res.hits().hits().stream().map(this::toDocument).collect(Collectors.toList()); } catch (IOException e) { throw new RuntimeException(e); } }
private String getElasticsearchQueryString(Filter.Expression filterExpression) { return Objects.isNull(filterExpression) ? "*" : this.filterExpressionConverter.convertExpression(filterExpression); }
private Document toDocument(Hit<Document> hit) { Document document = (Document)hit.source(); Document.Builder documentBuilder = document.mutate(); if (hit.score() != null) { documentBuilder.metadata(DocumentMetadata.DISTANCE.value(), (double)1.0F - this.normalizeSimilarityScore(hit.score())); documentBuilder.score(this.normalizeSimilarityScore(hit.score())); }
return documentBuilder.build(); }
private double normalizeSimilarityScore(double score) { switch (this.options.getSimilarity()) { case l2norm -> { return (double)1.0F - Math.sqrt((double)1.0F / score - (double)1.0F); } default -> { return (double)2.0F * score - (double)1.0F; } } }
public boolean indexExists() { try { return this.elasticsearchClient.indices().exists((ex) -> ex.index(this.options.getIndexName(), new String[0])).value(); } catch (IOException e) { throw new RuntimeException(e); } }
private void createIndexMapping() { try { this.elasticsearchClient.indices().create((cr) -> cr.index(this.options.getIndexName()).mappings((map) -> map.properties(this.options.getEmbeddingFieldName(), (p) -> p.denseVector((dv) -> dv.similarity(this.options.getSimilarity().toString()).dims(this.options.getDimensions()))))); } catch (IOException e) { throw new RuntimeException(e); } }
public void afterPropertiesSet() { if (this.initializeSchema) { if (!this.indexExists()) { this.createIndexMapping(); }
} }
public VectorStoreObservationContext.Builder createObservationContextBuilder(String operationName) { return VectorStoreObservationContext.builder(VectorStoreProvider.ELASTICSEARCH.value(), operationName).collectionName(this.options.getIndexName()).dimensions(this.embeddingModel.dimensions()).similarityMetric(this.getSimilarityMetric()); }
private String getSimilarityMetric() { return !SIMILARITYTYPEMAPPING.containsKey(this.options.getSimilarity()) ? this.options.getSimilarity().name() : ((VectorStoreSimilarityMetric)SIMILARITYTYPEMAPPING.get(this.options.getSimilarity())).value(); }
public <T> Optional<T> getNativeClient() { T client = (T)this.elasticsearchClient; return Optional.of(client); }
public static Builder builder(RestClient restClient, EmbeddingModel embeddingModel) { return new Builder(restClient, embeddingModel); }
static { SIMILARITYTYPEMAPPING = Map.of(SimilarityFunction.cosine, VectorStoreSimilarityMetric.COSINE, SimilarityFunction.l2norm, VectorStoreSimilarityMetric.EUCLIDEAN, SimilarityFunction.dotproduct, VectorStoreSimilarityMetric.DOT); }
public static class Builder extends AbstractVectorStoreBuilder<Builder> { private final RestClient restClient; private ElasticsearchVectorStoreOptions options = new ElasticsearchVectorStoreOptions(); private boolean initializeSchema = false; private FilterExpressionConverter filterExpressionConverter = new ElasticsearchAiSearchFilterExpressionConverter();
public Builder(RestClient restClient, EmbeddingModel embeddingModel) { super(embeddingModel); Assert.notNull(restClient, "RestClient must not be null"); this.restClient = restClient; }
public Builder options(ElasticsearchVectorStoreOptions options) { Assert.notNull(options, "options must not be null"); this.options = options; return this; }
public Builder initializeSchema(boolean initializeSchema) { this.initializeSchema = initializeSchema; return this; }
public Builder filterExpressionConverter(FilterExpressionConverter converter) { Assert.notNull(converter, "filterExpressionConverter must not be null"); this.filterExpressionConverter = converter; return this; }
public ElasticsearchVectorStore build() { return new ElasticsearchVectorStore(this); } }}ElasticsearchAiSearchFilterExpressionConverter
用于将 Filter.Expression 对象转换为 Elasticsearch 查询字符串表示的类,用于支持基于 Elasticsearch 的过滤查询功能,将复杂的过滤条件转换为 Elasticsearch 可识别的查询表达式
SimpleDateFormat dateFormat:用于格式化和解析日期字符串,时区设置为 UTC
对外暴露的方法
| 方法名 | 描述 |
| doStartGroup | 在查询表达式中开始一个组,添加左括号 ( |
| doEndGroup | 在查询表达式中结束一个组,添加右括号 ) |
| doStartValueRange | 开始处理值范围 |
| doEndValueRange | 结束处理值范围 |
| doKey | 将过滤键转换为 Elasticsearch 查询格式,添加前缀 metadata |
| doExpression | 根据表达式类型(如 AND、OR、EQ 等)生成对应的 Redis 查询表达式 |
| withMetaPrefix | 为字段名称添加 metadata. 前缀 |
| doValue | 根据值类型(如列表、日期、字符串等)生成对应的 Elasticsearch 查询表达式 |
| doSingleValue | 处理单个值,支持日期格式化和字符串解析 |
package org.springframework.ai.vectorstore.elasticsearch;
import java.text.ParseException;import java.text.SimpleDateFormat;import java.util.Date;import java.util.List;import java.util.TimeZone;import java.util.regex.Pattern;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.Filter.ExpressionType;import org.springframework.ai.vectorstore.filter.converter.AbstractFilterExpressionConverter;
public class ElasticsearchAiSearchFilterExpressionConverter extends AbstractFilterExpressionConverter { private static final Pattern DATEFORMATPATTERN = Pattern.compile("\\d{4}-\\d{2}-\\d{2}T\\d{2}:\\d{2}:\\d{2}Z"); private final SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd'T'HH:mm:ss'Z'");
public ElasticsearchAiSearchFilterExpressionConverter() { this.dateFormat.setTimeZone(TimeZone.getTimeZone("UTC")); }
protected void doExpression(Filter.Expression expression, StringBuilder context) { if (expression.type() != ExpressionType.IN && expression.type() != ExpressionType.NIN) { this.convertOperand(expression.left(), context); context.append(this.getOperationSymbol(expression)); this.convertOperand(expression.right(), context); } else { context.append(this.getOperationSymbol(expression)); context.append("("); this.convertOperand(expression.left(), context); this.convertOperand(expression.right(), context); context.append(")"); }
}
protected void doStartValueRange(Filter.Value listValue, StringBuilder context) { }
protected void doEndValueRange(Filter.Value listValue, StringBuilder context) { }
protected void doAddValueRangeSpitter(Filter.Value listValue, StringBuilder context) { context.append(" OR "); }
private String getOperationSymbol(Filter.Expression exp) { String var10000; switch (exp.type()) { case AND: var10000 = " AND "; break; case OR: var10000 = " OR "; break; case EQ: case IN: var10000 = ""; break; case NE: var10000 = " NOT "; break; case LT: var10000 = "<"; break; case LTE: var10000 = "<="; break; case GT: var10000 = ">"; break; case GTE: var10000 = ">="; break; case NIN: var10000 = "NOT "; break; default: throw new RuntimeException("Not supported expression type: " + String.valueOf(exp.type())); }
return var10000; }
public void doKey(Filter.Key key, StringBuilder context) { String identifier = this.hasOuterQuotes(key.key()) ? this.removeOuterQuotes(key.key()) : key.key(); String prefixedIdentifier = this.withMetaPrefix(identifier); context.append(prefixedIdentifier.trim()).append(":"); }
public String withMetaPrefix(String identifier) { return "metadata." + identifier; }
protected void doValue(Filter.Value filterValue, StringBuilder context) { Object var4 = filterValue.value(); if (var4 instanceof List list) { int c = 0;
for(Object v : list) { context.append(v); if (c++ < list.size() - 1) { this.doAddValueRangeSpitter(filterValue, context); } } } else { this.doSingleValue(filterValue.value(), context); }
}
protected void doSingleValue(Object value, StringBuilder context) { if (value instanceof Date date) { context.append(this.dateFormat.format(date)); } else if (value instanceof String text) { if (DATEFORMATPATTERN.matcher(text).matches()) { try { Date date = this.dateFormat.parse(text); context.append(this.dateFormat.format(date)); } catch (ParseException e) { throw new IllegalArgumentException("Invalid date type:" + text, e); } } else { context.append(text); } } else { context.append(value); }
}
public void doStartGroup(Filter.Group group, StringBuilder context) { context.append("("); }
public void doEndGroup(Filter.Group group, StringBuilder context) { context.append(")"); }}ElasticsearchVectorStoreOptions
用于配置 Elasticsearch 向量存储的选项,包括索引名称、向量维度、相似性函数以及嵌入字段名称
package org.springframework.ai.vectorstore.elasticsearch;
public class ElasticsearchVectorStoreOptions { private String indexName = "spring-ai-document-index"; private int dimensions = 1536; private SimilarityFunction similarity; private String embeddingFieldName;
public ElasticsearchVectorStoreOptions() { this.similarity = SimilarityFunction.cosine; this.embeddingFieldName = "embedding"; }
public String getIndexName() { return this.indexName; }
public void setIndexName(String indexName) { this.indexName = indexName; }
public int getDimensions() { return this.dimensions; }
public void setDimensions(int dims) { this.dimensions = dims; }
public SimilarityFunction getSimilarity() { return this.similarity; }
public void setSimilarity(SimilarityFunction similarity) { this.similarity = similarity; }
public String getEmbeddingFieldName() { return this.embeddingFieldName; }
public void setEmbeddingFieldName(String embeddingFieldName) { this.embeddingFieldName = embeddingFieldName; }}SimilarityFunction
定义了三种常见的向量相似度计算方法
- l2norm:欧氏距离(L2 范数),用于衡量两个向量之间的直线距离
- dotproduct:点积,用于衡量两个向量的相似性,常用于向量空间模型
- cosine:余弦相似度,衡量两个向量夹角的余弦值,常用于文本和向量检索场景
package org.springframework.ai.vectorstore.elasticsearch;
public enum SimilarityFunction { l2norm, dotproduct, cosine;}Redis 的向量解读
pom 文件
引入 Redis 的向量数据库依赖
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-starter-vector-store-redis</artifactId></dependency>该 pom 中包含以下两个 Redis 相关模块:
- spring-ai-autoconfigure-vector-store-redis:自动注入 Redis 的相关信息
- spring-ai-redis-store:Redis 向量存储类
自动注入模块
RedisVectorStoreProperties
配置默认索引、redis 的前缀
package org.springframework.ai.vectorstore.redis.autoconfigure;
import org.springframework.ai.vectorstore.properties.CommonVectorStoreProperties;import org.springframework.boot.context.properties.ConfigurationProperties;
@ConfigurationProperties("spring.ai.vectorstore.redis")public class RedisVectorStoreProperties extends CommonVectorStoreProperties { public static final String CONFIGPREFIX = "spring.ai.vectorstore.redis"; private String indexName = "default-index"; private String prefix = "default:";
public String getIndexName() { return this.indexName; }
public void setIndexName(String indexName) { this.indexName = indexName; }
public String getPrefix() { return this.prefix; }
public void setPrefix(String prefix) { this.prefix = prefix; }}RedisVectorStoreAutoConfiguration
用于在项目中自动配置 Redis 向量存储(RedisVectorStore)相关的 Bean
- 自动装配条件:只有在类路径下存在 Jedis、RedisVectorStore、EmbeddingModel 等相关类,并且存在 JedisConnectionFactory Bean,且配置项 spring.ai.vectorstore.type 为 redis(或未设置)时才生效
- 配置属性支持:启用 RedisVectorStoreProperties,允许通过配置文件自定义 Redis 向量存储的相关参数(如索引名、前缀等)
- 批处理策略 Bean:如果没有自定义的 BatchingStrategy,则自动注入默认的 TokenCountBatchingStrategy
- RedisVectorStore Bean:自动创建并配置 RedisVectorStore,包括连接 Redis、设置索引、前缀、批处理策略、观测注册等
package org.springframework.ai.vectorstore.redis.autoconfigure;
import io.micrometer.observation.ObservationRegistry;import org.springframework.ai.embedding.BatchingStrategy;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.embedding.TokenCountBatchingStrategy;import org.springframework.ai.vectorstore.observation.VectorStoreObservationConvention;import org.springframework.ai.vectorstore.redis.RedisVectorStore;import org.springframework.beans.factory.ObjectProvider;import org.springframework.boot.autoconfigure.AutoConfiguration;import org.springframework.boot.autoconfigure.condition.ConditionalOnBean;import org.springframework.boot.autoconfigure.condition.ConditionalOnClass;import org.springframework.boot.autoconfigure.condition.ConditionalOnMissingBean;import org.springframework.boot.autoconfigure.condition.ConditionalOnProperty;import org.springframework.boot.autoconfigure.data.redis.RedisAutoConfiguration;import org.springframework.boot.context.properties.EnableConfigurationProperties;import org.springframework.context.annotation.Bean;import org.springframework.data.redis.connection.jedis.JedisConnectionFactory;import redis.clients.jedis.DefaultJedisClientConfig;import redis.clients.jedis.HostAndPort;import redis.clients.jedis.JedisClientConfig;import redis.clients.jedis.JedisPooled;
@AutoConfiguration( after = {RedisAutoConfiguration.class})@ConditionalOnClass({JedisPooled.class, JedisConnectionFactory.class, RedisVectorStore.class, EmbeddingModel.class})@ConditionalOnBean({JedisConnectionFactory.class})@EnableConfigurationProperties({RedisVectorStoreProperties.class})@ConditionalOnProperty( name = {"spring.ai.vectorstore.type"}, havingValue = "redis", matchIfMissing = true)public class RedisVectorStoreAutoConfiguration { @Bean @ConditionalOnMissingBean({BatchingStrategy.class}) BatchingStrategy batchingStrategy() { return new TokenCountBatchingStrategy(); }
@Bean @ConditionalOnMissingBean public RedisVectorStore vectorStore(EmbeddingModel embeddingModel, RedisVectorStoreProperties properties, JedisConnectionFactory jedisConnectionFactory, ObjectProvider<ObservationRegistry> observationRegistry, ObjectProvider<VectorStoreObservationConvention> customObservationConvention, BatchingStrategy batchingStrategy) { JedisPooled jedisPooled = this.jedisPooled(jedisConnectionFactory); return ((RedisVectorStore.Builder)((RedisVectorStore.Builder)((RedisVectorStore.Builder)RedisVectorStore.builder(jedisPooled, embeddingModel).initializeSchema(properties.isInitializeSchema()).observationRegistry((ObservationRegistry)observationRegistry.getIfUnique(() -> ObservationRegistry.NOOP))).customObservationConvention((VectorStoreObservationConvention)customObservationConvention.getIfAvailable(() -> null))).batchingStrategy(batchingStrategy)).indexName(properties.getIndexName()).prefix(properties.getPrefix()).build(); }
private JedisPooled jedisPooled(JedisConnectionFactory jedisConnectionFactory) { String host = jedisConnectionFactory.getHostName(); int port = jedisConnectionFactory.getPort(); JedisClientConfig clientConfig = DefaultJedisClientConfig.builder().ssl(jedisConnectionFactory.isUseSsl()).clientName(jedisConnectionFactory.getClientName()).timeoutMillis(jedisConnectionFactory.getTimeout()).password(jedisConnectionFactory.getPassword()).build(); return new JedisPooled(new HostAndPort(host, port), clientConfig); }}spring-ai-redis-store 模块
RedisVectorStore(核心类)
基于 Redis 的向量存储实现类
JedisPooled jedis:用于与 Redis 交互prefix:Redis 键的前缀,默认为”embedding:“indexName: Redis 的索引名称,默认为”spring-ai-index”,创建索引用到了 RediSearchAlgorithm vectorAlgorithm:向量算法,支持 HNSW、FLAT(默认为 HNSW)String contentFieldName:存储文档内容的字段名称,默认为”content”String embeddingFieldName:存储向量嵌入的字段名称,默认为 embeddingmetadataFields:元数据字段,支持 TEXT、TAG、NUMERIC 等类型FilterExpressionConverter filterExpressionConverter:过滤表达式转化器,主要用于删除、相似性匹配boolean initializeSchema字段:用于初始化创建索引(设置为 True)
对外暴露的方法
| 方法名 | 描述 |
| doAdd | 添加一组文档到向量存储,调用嵌入模型生成嵌入向量并存储在内存中 |
| doDelete | 根据文档 ID 删除存储中的文档 |
| doSimilaritySearch | 基于查询嵌入和过滤条件进行相似性搜索,返回匹配的文档列表 |
| createObservationContextBuilder | 创建观察上下文构建器,用于记录操作信息 |
| getNativeClient | 返回 Redis 客户端实例 |
| getJedis | 返回 Redis 客户端实例 |
| afterPropertiesSet | 初始化 Redis 索引架构 |
package org.springframework.ai.vectorstore.redis;
import java.text.MessageFormat;import java.util.ArrayList;import java.util.Arrays;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Objects;import java.util.Optional;import java.util.function.Function;import java.util.function.Predicate;import java.util.stream.Collectors;import java.util.stream.Stream;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentMetadata;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.embedding.EmbeddingOptionsBuilder;import org.springframework.ai.observation.conventions.VectorStoreProvider;import org.springframework.ai.observation.conventions.VectorStoreSimilarityMetric;import org.springframework.ai.vectorstore.AbstractVectorStoreBuilder;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.FilterExpressionConverter;import org.springframework.ai.vectorstore.observation.AbstractObservationVectorStore;import org.springframework.ai.vectorstore.observation.VectorStoreObservationContext;import org.springframework.beans.factory.InitializingBean;import org.springframework.lang.Nullable;import org.springframework.util.Assert;import org.springframework.util.CollectionUtils;import org.springframework.util.StringUtils;import redis.clients.jedis.JedisPooled;import redis.clients.jedis.Pipeline;import redis.clients.jedis.json.Path2;import redis.clients.jedis.search.FTCreateParams;import redis.clients.jedis.search.IndexDataType;import redis.clients.jedis.search.Query;import redis.clients.jedis.search.RediSearchUtil;import redis.clients.jedis.search.Schema;import redis.clients.jedis.search.SearchResult;import redis.clients.jedis.search.Schema.FieldType;import redis.clients.jedis.search.schemafields.NumericField;import redis.clients.jedis.search.schemafields.SchemaField;import redis.clients.jedis.search.schemafields.TagField;import redis.clients.jedis.search.schemafields.TextField;import redis.clients.jedis.search.schemafields.VectorField;import redis.clients.jedis.search.schemafields.VectorField.VectorAlgorithm;
public class RedisVectorStore extends AbstractObservationVectorStore implements InitializingBean { public static final String DEFAULTINDEXNAME = "spring-ai-index"; public static final String DEFAULTCONTENTFIELDNAME = "content"; public static final String DEFAULTEMBEDDINGFIELDNAME = "embedding"; public static final String DEFAULTPREFIX = "embedding:"; public static final Algorithm DEFAULTVECTORALGORITHM; public static final String DISTANCEFIELDNAME = "vectorscore"; private static final String QUERYFORMAT = "%s=>[KNN %s @%s $%s AS %s]"; private static final Path2 JSONSETPATH; private static final String JSONPATHPREFIX = "$."; private static final Logger logger; private static final Predicate<Object> RESPONSEOK; private static final Predicate<Object> RESPONSEDELOK; private static final String VECTORTYPEFLOAT32 = "FLOAT32"; private static final String EMBEDDINGPARAMNAME = "BLOB"; private static final String DEFAULTDISTANCEMETRIC = "COSINE"; private final JedisPooled jedis; private final boolean initializeSchema; private final String indexName; private final String prefix; private final String contentFieldName; private final String embeddingFieldName; private final Algorithm vectorAlgorithm; private final List<MetadataField> metadataFields; private final FilterExpressionConverter filterExpressionConverter;
protected RedisVectorStore(Builder builder) { super(builder); Assert.notNull(builder.jedis, "JedisPooled must not be null"); this.jedis = builder.jedis; this.indexName = builder.indexName; this.prefix = builder.prefix; this.contentFieldName = builder.contentFieldName; this.embeddingFieldName = builder.embeddingFieldName; this.vectorAlgorithm = builder.vectorAlgorithm; this.metadataFields = builder.metadataFields; this.initializeSchema = builder.initializeSchema; this.filterExpressionConverter = new RedisFilterExpressionConverter(this.metadataFields); }
public JedisPooled getJedis() { return this.jedis; }
public void doAdd(List<Document> documents) { try (Pipeline pipeline = this.jedis.pipelined()) { List<float[]> embeddings = this.embeddingModel.embed(documents, EmbeddingOptionsBuilder.builder().build(), this.batchingStrategy);
for(Document document : documents) { HashMap<String, Object> fields = new HashMap(); fields.put(this.embeddingFieldName, embeddings.get(documents.indexOf(document))); fields.put(this.contentFieldName, document.getText()); fields.putAll(document.getMetadata()); pipeline.jsonSetWithEscape(this.key(document.getId()), JSONSETPATH, fields); }
List<Object> responses = pipeline.syncAndReturnAll(); Optional<Object> errResponse = responses.stream().filter(Predicate.not(RESPONSEOK)).findAny(); if (errResponse.isPresent()) { String message = MessageFormat.format("Could not add document: {0}", errResponse.get()); if (logger.isErrorEnabled()) { logger.error(message); }
throw new RuntimeException(message); } }
}
private String key(String id) { return this.prefix + id; }
public void doDelete(List<String> idList) { try (Pipeline pipeline = this.jedis.pipelined()) { for(String id : idList) { pipeline.jsonDel(this.key(id)); }
List<Object> responses = pipeline.syncAndReturnAll(); Optional<Object> errResponse = responses.stream().filter(Predicate.not(RESPONSEDELOK)).findAny(); if (errResponse.isPresent() && logger.isErrorEnabled()) { logger.error("Could not delete document: {}", errResponse.get()); } }
}
protected void doDelete(Filter.Expression filterExpression) { Assert.notNull(filterExpression, "Filter expression must not be null");
try { String filterStr = this.filterExpressionConverter.convertExpression(filterExpression); List<String> matchingIds = new ArrayList(); SearchResult searchResult = this.jedis.ftSearch(this.indexName, filterStr);
for(redis.clients.jedis.search.Document doc : searchResult.getDocuments()) { String docId = doc.getId(); matchingIds.add(docId.replace(this.key(""), "")); }
if (!matchingIds.isEmpty()) { try (Pipeline pipeline = this.jedis.pipelined()) { for(String id : matchingIds) { pipeline.jsonDel(this.key(id)); }
List<Object> responses = pipeline.syncAndReturnAll(); Optional<Object> errResponse = responses.stream().filter(Predicate.not(RESPONSEDELOK)).findAny(); if (errResponse.isPresent()) { logger.error("Could not delete document: {}", errResponse.get()); throw new IllegalStateException("Failed to delete some documents"); } }
logger.debug("Deleted {} documents matching filter expression", matchingIds.size()); }
} catch (Exception e) { logger.error("Failed to delete documents by filter", e); throw new IllegalStateException("Failed to delete documents by filter", e); } }
public List<Document> doSimilaritySearch(SearchRequest request) { Assert.isTrue(request.getTopK() > 0, "The number of documents to be returned must be greater than zero"); Assert.isTrue(request.getSimilarityThreshold() >= (double)0.0F && request.getSimilarityThreshold() <= (double)1.0F, "The similarity score is bounded between 0 and 1; least to most similar respectively."); String filter = this.nativeExpressionFilter(request); String queryString = String.format("%s=>[KNN %s @%s $%s AS %s]", filter, request.getTopK(), this.embeddingFieldName, "BLOB", "vectorscore"); List<String> returnFields = new ArrayList(); Stream var10000 = this.metadataFields.stream().map(MetadataField::name); Objects.requireNonNull(returnFields); var10000.forEach(returnFields::add); returnFields.add(this.embeddingFieldName); returnFields.add(this.contentFieldName); returnFields.add("vectorscore"); float[] embedding = this.embeddingModel.embed(request.getQuery()); Query query = (new Query(queryString)).addParam("BLOB", RediSearchUtil.toByteArray(embedding)).returnFields((String[])returnFields.toArray(new String[0])).setSortBy("vectorscore", true).limit(0, request.getTopK()).dialect(2); SearchResult result = this.jedis.ftSearch(this.indexName, query); return result.getDocuments().stream().filter((d) -> (double)this.similarityScore(d) >= request.getSimilarityThreshold()).map(this::toDocument).toList(); }
private Document toDocument(redis.clients.jedis.search.Document doc) { String id = doc.getId().substring(this.prefix.length()); String content = doc.hasProperty(this.contentFieldName) ? doc.getString(this.contentFieldName) : ""; Stream var10000 = this.metadataFields.stream().map(MetadataField::name); Objects.requireNonNull(doc); var10000 = var10000.filter(doc::hasProperty); Function var10001 = Function.identity(); Objects.requireNonNull(doc); Map<String, Object> metadata = (Map)var10000.collect(Collectors.toMap(var10001, doc::getString)); metadata.put("vectorscore", 1.0F - this.similarityScore(doc)); metadata.put(DocumentMetadata.DISTANCE.value(), 1.0F - this.similarityScore(doc)); return Document.builder().id(id).text(content).metadata(metadata).score((double)this.similarityScore(doc)).build(); }
private float similarityScore(redis.clients.jedis.search.Document doc) { return (2.0F - Float.parseFloat(doc.getString("vectorscore"))) / 2.0F; }
private String nativeExpressionFilter(SearchRequest request) { if (request.getFilterExpression() == null) { return "*"; } else { FilterExpressionConverter var10000 = this.filterExpressionConverter; return "(" + var10000.convertExpression(request.getFilterExpression()) + ")"; } }
public void afterPropertiesSet() { if (this.initializeSchema) { if (!this.jedis.ftList().contains(this.indexName)) { String response = this.jedis.ftCreate(this.indexName, FTCreateParams.createParams().on(IndexDataType.JSON).addPrefix(this.prefix), this.schemaFields()); if (!RESPONSEOK.test(response)) { String message = MessageFormat.format("Could not create index: {0}", response); throw new RuntimeException(message); } } } }
private Iterable<SchemaField> schemaFields() { Map<String, Object> vectorAttrs = new HashMap(); vectorAttrs.put("DIM", this.embeddingModel.dimensions()); vectorAttrs.put("DISTANCEMETRIC", "COSINE"); vectorAttrs.put("TYPE", "FLOAT32"); List<SchemaField> fields = new ArrayList(); fields.add(TextField.of(this.jsonPath(this.contentFieldName)).as(this.contentFieldName).weight((double)1.0F)); fields.add(VectorField.builder().fieldName(this.jsonPath(this.embeddingFieldName)).algorithm(this.vectorAlgorithm()).attributes(vectorAttrs).as(this.embeddingFieldName).build()); if (!CollectionUtils.isEmpty(this.metadataFields)) { for(MetadataField field : this.metadataFields) { fields.add(this.schemaField(field)); } }
return fields; }
private SchemaField schemaField(MetadataField field) { String fieldName = this.jsonPath(field.name); Object var10000; switch (field.fieldType) { case NUMERIC -> var10000 = NumericField.of(fieldName).as(field.name); case TAG -> var10000 = TagField.of(fieldName).as(field.name); case TEXT -> var10000 = TextField.of(fieldName).as(field.name); default -> throw new IllegalArgumentException(MessageFormat.format("Field {0} has unsupported type {1}", field.name, field.fieldType)); }
return (SchemaField)var10000; }
private VectorField.VectorAlgorithm vectorAlgorithm() { return this.vectorAlgorithm == RedisVectorStore.Algorithm.HSNW ? VectorAlgorithm.HNSW : VectorAlgorithm.FLAT; }
private String jsonPath(String field) { return "$." + field; }
public VectorStoreObservationContext.Builder createObservationContextBuilder(String operationName) { return VectorStoreObservationContext.builder(VectorStoreProvider.REDIS.value(), operationName).collectionName(this.indexName).dimensions(this.embeddingModel.dimensions()).fieldName(this.embeddingFieldName).similarityMetric(VectorStoreSimilarityMetric.COSINE.value()); }
public <T> Optional<T> getNativeClient() { T client = (T)this.jedis; return Optional.of(client); }
public static Builder builder(JedisPooled jedis, EmbeddingModel embeddingModel) { return new Builder(jedis, embeddingModel); }
static { DEFAULTVECTORALGORITHM = RedisVectorStore.Algorithm.HSNW; JSONSETPATH = Path2.of("$"); logger = LoggerFactory.getLogger(RedisVectorStore.class); RESPONSEOK = Predicate.isEqual("OK"); RESPONSEDELOK = Predicate.isEqual(1L); }
public static enum Algorithm { FLAT, HSNW; }
public static record MetadataField(String name, Schema.FieldType fieldType) { public static MetadataField text(String name) { return new MetadataField(name, FieldType.TEXT); }
public static MetadataField numeric(String name) { return new MetadataField(name, FieldType.NUMERIC); }
public static MetadataField tag(String name) { return new MetadataField(name, FieldType.TAG); } }
public static class Builder extends AbstractVectorStoreBuilder<Builder> { private final JedisPooled jedis; private String indexName = "spring-ai-index"; private String prefix = "embedding:"; private String contentFieldName = "content"; private String embeddingFieldName = "embedding"; private Algorithm vectorAlgorithm; private List<MetadataField> metadataFields; private boolean initializeSchema;
private Builder(JedisPooled jedis, EmbeddingModel embeddingModel) { super(embeddingModel); this.vectorAlgorithm = RedisVectorStore.DEFAULTVECTORALGORITHM; this.metadataFields = new ArrayList(); this.initializeSchema = false; Assert.notNull(jedis, "JedisPooled must not be null"); this.jedis = jedis; }
public Builder indexName(String indexName) { if (StringUtils.hasText(indexName)) { this.indexName = indexName; }
return this; }
public Builder prefix(String prefix) { if (StringUtils.hasText(prefix)) { this.prefix = prefix; }
return this; }
public Builder contentFieldName(String fieldName) { if (StringUtils.hasText(fieldName)) { this.contentFieldName = fieldName; }
return this; }
public Builder embeddingFieldName(String fieldName) { if (StringUtils.hasText(fieldName)) { this.embeddingFieldName = fieldName; }
return this; }
public Builder vectorAlgorithm(@Nullable Algorithm algorithm) { if (algorithm != null) { this.vectorAlgorithm = algorithm; }
return this; }
public Builder metadataFields(MetadataField... fields) { return this.metadataFields(Arrays.asList(fields)); }
public Builder metadataFields(@Nullable List<MetadataField> fields) { if (fields != null && !fields.isEmpty()) { this.metadataFields = new ArrayList(fields); }
return this; }
public Builder initializeSchema(boolean initializeSchema) { this.initializeSchema = initializeSchema; return this; }
public RedisVectorStore build() { return new RedisVectorStore(this); } }}RedisFilterExpressionConverter
用于支持 Redis 的搜索和查询功能(如 RediSearch),将过滤条件转换为 Redis 可识别的表达式
POSITIVEINFINITY: 表示正无穷边界,用于数值范围查询。NEGATIVEINFINITY:表示负无穷边界,用于数值范围查询。metadataFields: 存储元数据字段的映射关系,键为字段名称,值为 MetadataField 对象,用于定义字段类型(如 TEXT、TAG、NUMERIC)
对外暴露的方法
| 方法名 | 描述 |
| doStartGroup | 在过滤表达式中开始一个组,添加左括号 ( |
| doEndGroup | 在过滤表达式中结束一个组,添加右括号 ) |
| doKey | 将过滤键转换为 Redis 查询格式,添加 @key: |
| doExpression | 根据表达式类型(如 AND、OR、EQ 等)生成对应的 Redis 查询表达式 |
package org.springframework.ai.vectorstore.redis;
import java.text.MessageFormat;import java.util.List;import java.util.Map;import java.util.function.Function;import java.util.stream.Collectors;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.Filter.ExpressionType;import org.springframework.ai.vectorstore.filter.converter.AbstractFilterExpressionConverter;import org.springframework.ai.vectorstore.redis.RedisVectorStore.MetadataField;
public class RedisFilterExpressionConverter extends AbstractFilterExpressionConverter { public static final NumericBoundary POSITIVEINFINITY = new NumericBoundary(Double.POSITIVEINFINITY, true); public static final NumericBoundary NEGATIVEINFINITY = new NumericBoundary(Double.NEGATIVEINFINITY, true); private Map<String, RedisVectorStore.MetadataField> metadataFields;
public RedisFilterExpressionConverter(List<RedisVectorStore.MetadataField> metadataFields) { this.metadataFields = (Map)metadataFields.stream().collect(Collectors.toMap(RedisVectorStore.MetadataField::name, Function.identity())); }
protected void doStartGroup(Filter.Group group, StringBuilder context) { context.append("("); }
protected void doEndGroup(Filter.Group group, StringBuilder context) { context.append(")"); }
protected void doKey(Filter.Key key, StringBuilder context) { context.append("@").append(key.key()).append(":"); }
protected void doExpression(Filter.Expression expression, StringBuilder context) { switch (expression.type()) { case NIN: this.doExpression(this.negate(ExpressionType.IN, expression), context); break; case NE: this.doExpression(this.negate(ExpressionType.EQ, expression), context); break; case AND: this.doBinaryOperation(" ", expression, context); break; case OR: this.doBinaryOperation(" | ", expression, context); break; case NOT: context.append("-"); this.convertOperand(expression.left(), context); break; default: this.doField(expression, context); }
}
private Filter.Expression negate(Filter.ExpressionType expressionType, Filter.Expression expression) { return new Filter.Expression(ExpressionType.NOT, new Filter.Expression(expressionType, expression.left(), expression.right()), (Filter.Operand)null); }
private void doBinaryOperation(String delimiter, Filter.Expression expression, StringBuilder context) { this.convertOperand(expression.left(), context); context.append(delimiter); this.convertOperand(expression.right(), context); }
private void doField(Filter.Expression expression, StringBuilder context) { Filter.Key key = (Filter.Key)expression.left(); this.doKey(key, context); RedisVectorStore.MetadataField field = (RedisVectorStore.MetadataField)this.metadataFields.getOrDefault(key.key(), MetadataField.tag(key.key())); Filter.Value value = (Filter.Value)expression.right(); switch (field.fieldType()) { case NUMERIC: Numeric numeric = this.numeric(expression, value); context.append("["); context.append(numeric.lower()); context.append(" "); context.append(numeric.upper()); context.append("]"); break; case TAG: context.append("{"); context.append(this.stringValue(expression, value)); context.append("}"); break; case TEXT: context.append("("); context.append(this.stringValue(expression, value)); context.append(")"); break; default: throw new UnsupportedOperationException(MessageFormat.format("Field type {0} not supported", field.fieldType())); }
}
private Object stringValue(Filter.Expression expression, Filter.Value value) { String delimiter = this.tagValueDelimiter(expression); Object var5 = value.value(); if (var5 instanceof List<?> list) { return String.join(delimiter, list.stream().map(String::valueOf).toList()); } else { return value.value(); } }
private String tagValueDelimiter(Filter.Expression expression) { String var10000; switch (expression.type()) { case IN -> var10000 = " | "; case EQ -> var10000 = " "; default -> throw new UnsupportedOperationException(MessageFormat.format("Tag operand {0} not supported", expression.type())); }
return var10000; }
private Numeric numeric(Filter.Expression expression, Filter.Value value) { Numeric var10000; switch (expression.type()) { case EQ -> var10000 = new Numeric(this.inclusive(value), this.inclusive(value)); case GT -> var10000 = new Numeric(this.exclusive(value), POSITIVEINFINITY); case GTE -> var10000 = new Numeric(this.inclusive(value), POSITIVEINFINITY); case LT -> var10000 = new Numeric(NEGATIVEINFINITY, this.exclusive(value)); case LTE -> var10000 = new Numeric(NEGATIVEINFINITY, this.inclusive(value)); default -> throw new UnsupportedOperationException(MessageFormat.format("Expression type {0} not supported for numeric fields", expression.type())); }
return var10000; }
private NumericBoundary inclusive(Filter.Value value) { return new NumericBoundary(value.value(), false); }
private NumericBoundary exclusive(Filter.Value value) { return new NumericBoundary(value.value(), true); }
static record Numeric(NumericBoundary lower, NumericBoundary upper) { }
static record NumericBoundary(Object value, boolean exclusive) { private static final String INFINITY = "inf"; private static final String MINUSINFINITY = "-inf"; private static final String INCLUSIVEFORMAT = "%s"; private static final String EXCLUSIVEFORMAT = "(%s";
public String toString() { if (this == RedisFilterExpressionConverter.NEGATIVEINFINITY) { return "-inf"; } else { return this == RedisFilterExpressionConverter.POSITIVEINFINITY ? "inf" : String.format(this.formatString(), this.value); } }
private String formatString() { return this.exclusive ? "(%s" : "%s"; } }}