

此页面或文档已过期,请点击链接跳转到新页面。
前往新页面 →第六章:Rag 增强问答质量
此页面或文档已过期,请点击链接跳转到新页面。
前往新页面 →- 作者:影子, Spring AI Alibaba Committer
- 本文档基于 Spring AI 1.0.0 版本,Spring AI Alibaba 1.0.0.2 版本
- 本章包含快速上手(Rag简单对比、模块化、ETL)+ 源码解读(模块化、ETL)
Rag 快速上手
RAG(Retrieval-Augmented Generation,检索增强生成) ,该技术通过从外部知识库中检索相关信息,并将其作为提示(Prompt)输入给大型语言模型(LLMs),以增强模型处理知识密集型任务的能力。以下结合内存向量数据库实现 RAG 的典型案例:Pre-Retrieval、Retrieval、Generation 等场景,实战代码可见:https://github.com/GTyingzi/spring-ai-tutorial 下的rag目录
pom.xml
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-autoconfigure-model-openai</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-autoconfigure-model-chat-client</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-rag</artifactId> </dependency>
</dependencies>application.yml
server: port: 8080
spring: application: name: rag-simple
ai: openai: api-key: ${DASHSCOPEAPIKEY} base-url: https://dashscope.aliyuncs.com/compatible-mode chat: options: model: qwen-max embedding: options: model: text-embedding-v1RAG 效果简单对比
RagSimpleController
package com.spring.ai.tutorial.rag.controller;
import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.document.Document;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;import org.springframework.ai.vectorstore.SimpleVectorStore;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;import java.util.List;import java.util.Map;
@RestController@RequestMapping("/rag/simple")public class RagSimpleController {
private static final Logger logger = LoggerFactory.getLogger(RagSimpleController.class); private final SimpleVectorStore simpleVectorStore; private final ChatClient chatClient;
public RagSimpleController(EmbeddingModel embeddingModel, ChatClient.Builder builder) { this.simpleVectorStore = SimpleVectorStore .builder(embeddingModel).build(); this.chatClient = builder.build(); }
@GetMapping("/add") public void add() { logger.info("start add data"); HashMap<String, Object> map = new HashMap<>(); map.put("year", 2025); map.put("name", "yingzi"); List<Document> documents = List.of( new Document("你的姓名是影子,湖南邵阳人,25年硕士毕业于北京科技大学,曾先后在百度、理想、快手实习,曾发表过一篇自然语言处理的sci,现在是一名AI研发工程师"), new Document("你的姓名是影子,专业领域包含的数学、前后端、大数据、自然语言处理", Map.of("year", 2024)), new Document("你姓名是影子,爱好是发呆、思考、运动", map)); simpleVectorStore.add(documents); }
@GetMapping("/chat") public String chat(@RequestParam(value = "query", defaultValue = "你好,请告诉我影子这个人的身份信息") String query) { logger.info("start chat"); return chatClient.prompt(query).call().content(); }
@GetMapping("/chat-rag-advisor") public String chatRagAdvisor(@RequestParam(value = "query", defaultValue = "你好,请告诉我影子这个人的身份信息") String query) { logger.info("start chat with rag-advisor"); RetrievalAugmentationAdvisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder() .documentRetriever(VectorStoreDocumentRetriever.builder() .vectorStore(simpleVectorStore) .build()) .build();
return chatClient.prompt(query) .advisors(retrievalAugmentationAdvisor) .call().content(); }}效果
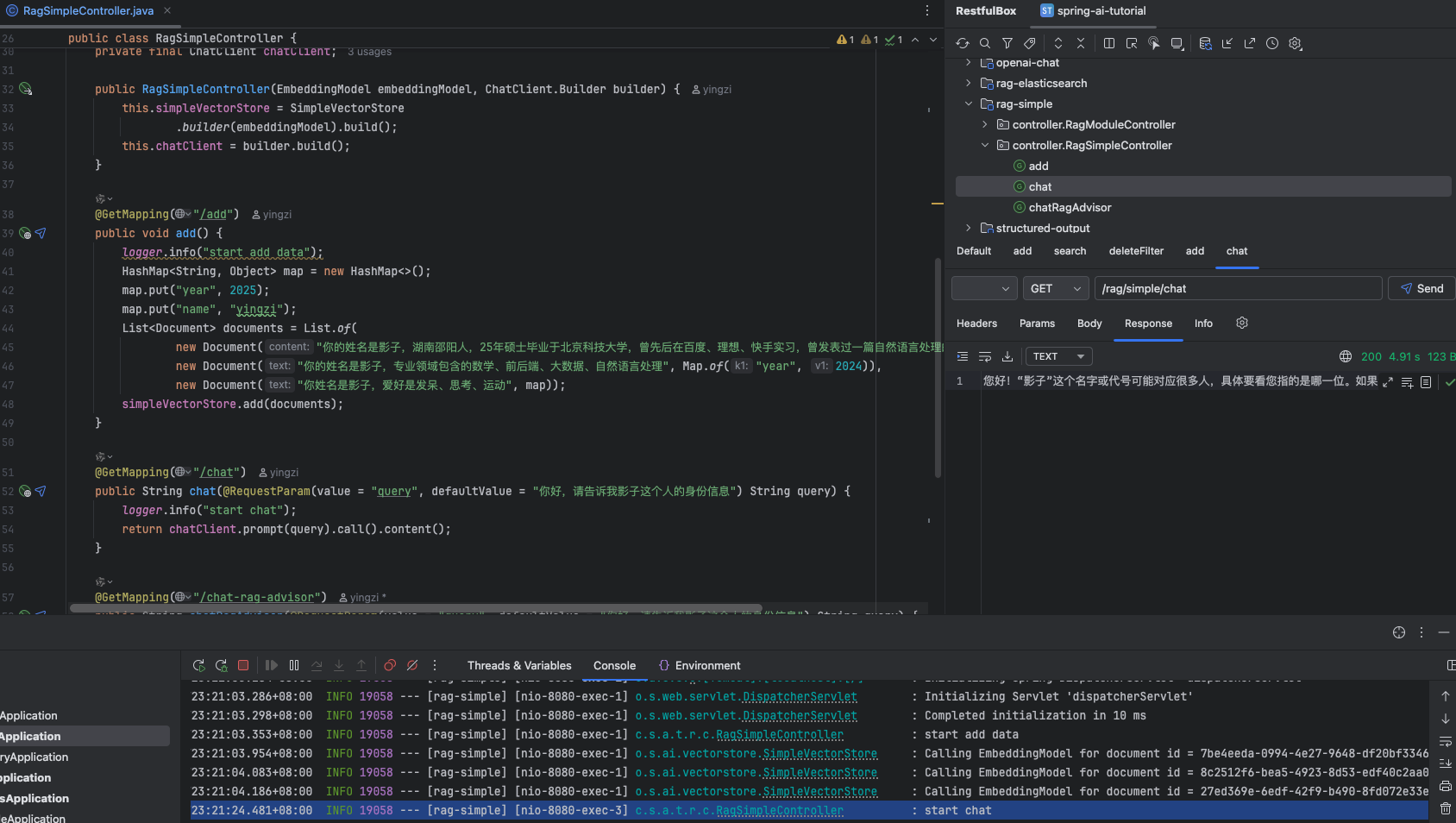
直接询问,并不知道“影子”是谁
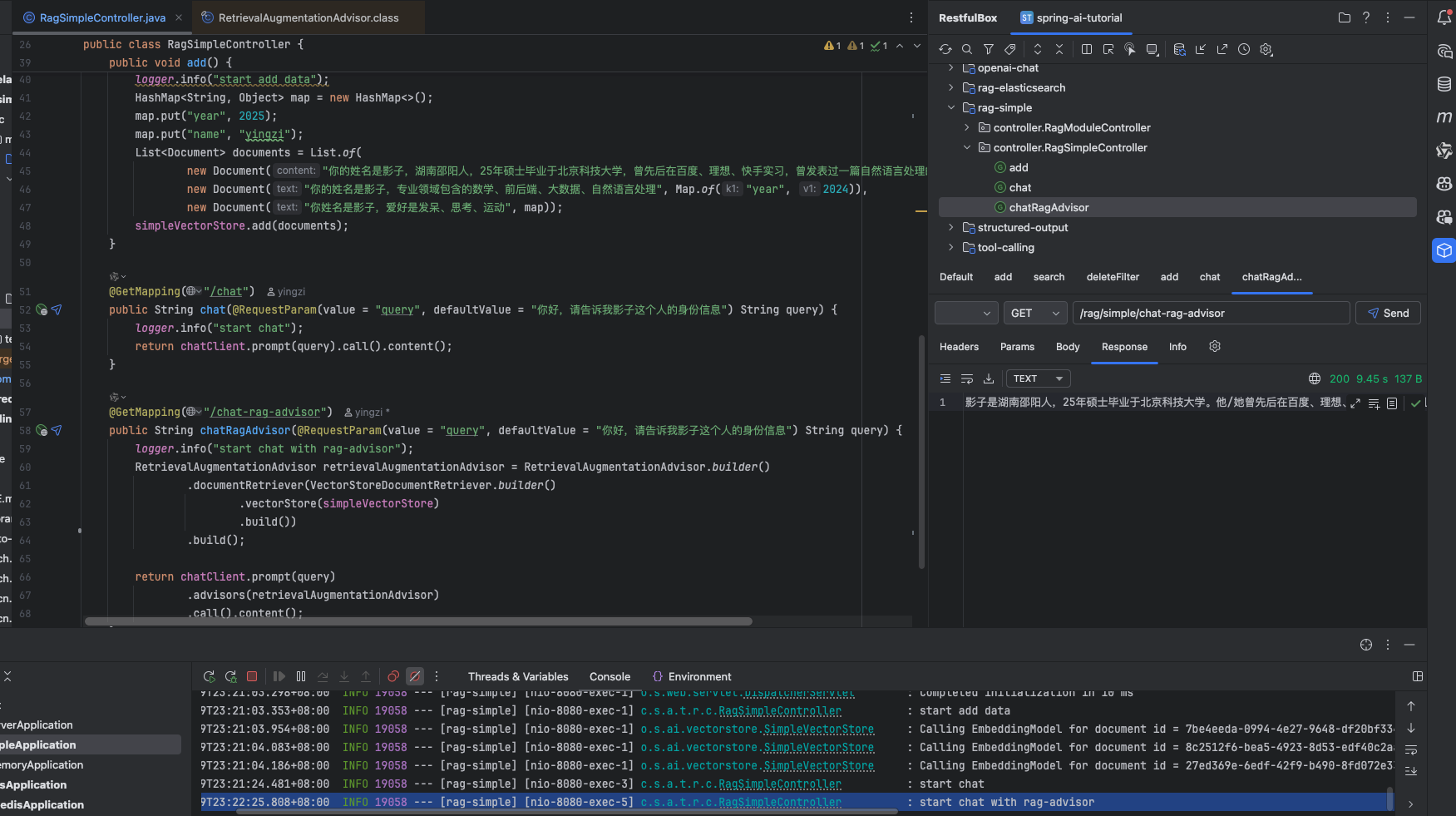
在 RAG 增强下,得知了“影子”
RAG 模块化案例
RAG 可以由一组模块化组件构成 《Rag 模块化》,结构化的工作流程保障 AI 模型生成质量
DocumentSelectFirst
package com.spring.ai.tutorial.rag.service;
import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;import org.springframework.ai.rag.postretrieval.document.DocumentPostProcessor;
import java.util.Collections;import java.util.List;
public class DocumentSelectFirst implements DocumentPostProcessor {
@Override public List<Document> process(Query query, List<Document> documents) { return Collections.singletonList(documents.get(0)); }}实现 DocumentPostProcessor 接口,从文档中挑选第一个
RagModuleController
package com.spring.ai.tutorial.rag.controller;
import com.spring.ai.tutorial.rag.service.DocumentSelectFirst;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.document.Document;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.rag.advisor.RetrievalAugmentationAdvisor;import org.springframework.ai.rag.generation.augmentation.ContextualQueryAugmenter;import org.springframework.ai.rag.preretrieval.query.expansion.MultiQueryExpander;import org.springframework.ai.rag.preretrieval.query.transformation.TranslationQueryTransformer;import org.springframework.ai.rag.retrieval.join.ConcatenationDocumentJoiner;import org.springframework.ai.rag.retrieval.search.VectorStoreDocumentRetriever;import org.springframework.ai.vectorstore.SimpleVectorStore;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RequestParam;import org.springframework.web.bind.annotation.RestController;
import java.util.HashMap;import java.util.List;import java.util.Map;
@RestController@RequestMapping("/rag/module")public class RagModuleController {
private static final Logger logger = LoggerFactory.getLogger(RagSimpleController.class); private final SimpleVectorStore simpleVectorStore; private final ChatClient.Builder chatClientBuilder;
public RagModuleController(EmbeddingModel embeddingModel, ChatClient.Builder builder) { this.simpleVectorStore = SimpleVectorStore .builder(embeddingModel).build(); this.chatClientBuilder = builder; }
@GetMapping("/add") public void add() { logger.info("start add data"); HashMap<String, Object> map = new HashMap<>(); map.put("year", 2025); map.put("name", "yingzi"); List<Document> documents = List.of( new Document("你的姓名是影子,湖南邵阳人,25年硕士毕业于北京科技大学,曾先后在百度、理想、快手实习,曾发表过一篇自然语言处理的sci,现在是一名AI研发工程师"), new Document("你的姓名是影子,专业领域包含的数学、前后端、大数据、自然语言处理", Map.of("year", 2024)), new Document("你姓名是影子,爱好是发呆、思考、运动", map)); simpleVectorStore.add(documents); }
@GetMapping("/chat-rag-advisor") public String chatRagAdvisor(@RequestParam(value = "query", defaultValue = "你好,请告诉我影子这个人的身份信息") String query) { logger.info("start chat with rag-advisor");
// 1. Pre-Retrieval // 1.1 MultiQueryExpander MultiQueryExpander multiQueryExpander = MultiQueryExpander.builder() .chatClientBuilder(this.chatClientBuilder) .build(); // 1.2 TranslationQueryTransformer TranslationQueryTransformer translationQueryTransformer = TranslationQueryTransformer.builder() .chatClientBuilder(this.chatClientBuilder) .targetLanguage("English") .build();
// 2. Retrieval // 2.1 VectorStoreDocumentRetriever VectorStoreDocumentRetriever vectorStoreDocumentRetriever = VectorStoreDocumentRetriever.builder() .vectorStore(simpleVectorStore) .build(); // 2.2 ConcatenationDocumentJoiner ConcatenationDocumentJoiner concatenationDocumentJoiner = new ConcatenationDocumentJoiner();
// 3. Post-Retrieval // 3.1 DocumentSelectFirst DocumentSelectFirst documentSelectFirst = new DocumentSelectFirst();
// 4. Generation // 4.1 ContextualQueryAugmenter ContextualQueryAugmenter contextualQueryAugmenter = ContextualQueryAugmenter.builder() .allowEmptyContext(true) .build();
RetrievalAugmentationAdvisor retrievalAugmentationAdvisor = RetrievalAugmentationAdvisor.builder() // 扩充为原来的3倍 .queryExpander(multiQueryExpander) // 转为英文 .queryTransformers(translationQueryTransformer) // 丛向向量存储中检索文档 .documentRetriever(vectorStoreDocumentRetriever) // 将检索到的文档进行拼接 .documentJoiner(concatenationDocumentJoiner) // 对检索到的文档进行处理,选择第一个 .documentPostProcessors(documentSelectFirst) // 对生成的查询进行上下文增强 .queryAugmenter(contextualQueryAugmenter) .build();
return this.chatClientBuilder.build().prompt(query) .advisors(retrievalAugmentationAdvisor) .call().content(); }}在这个例子中,我们使用了所有的 RAG 模块组件
Pre-Retrieval
- 扩充问题:MultiQueryExpander
- 翻译为英文:TranslationQueryTransformer
Retrieval
- 从向量存储中检索文档:VectorStoreDocumentRetriever
- 将检索到的文档进行拼接:ConcatenationDocumentJoiner
Post-Retrieval
- 选择第一个文档:DocumentSelectFirst
Generation
- 对生成的查询进行上下文增强:ContextualQueryAugmenter
效果
首先,进来的 originalQuery 的原始文本为“你好,请告诉我影子这个人的身份信息”
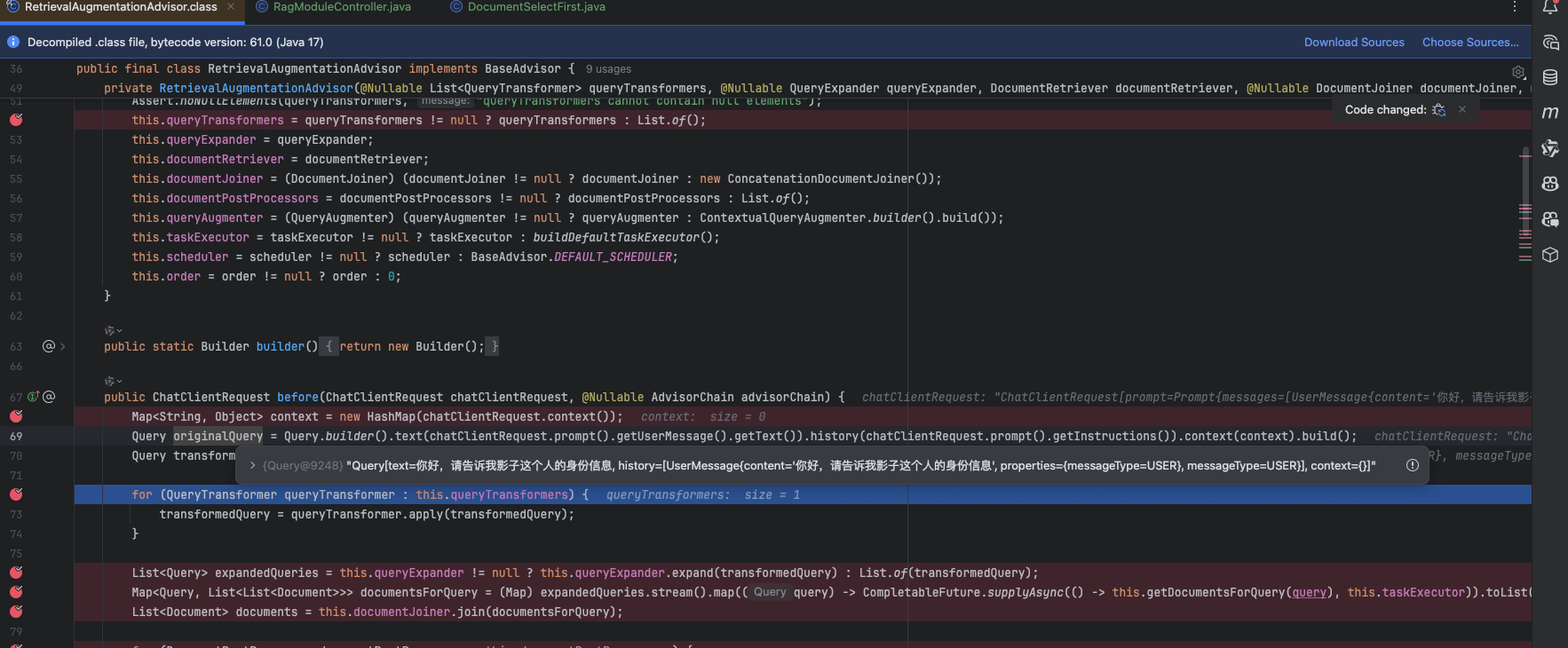
经过 TranslationQueryTransformer 翻译为英文
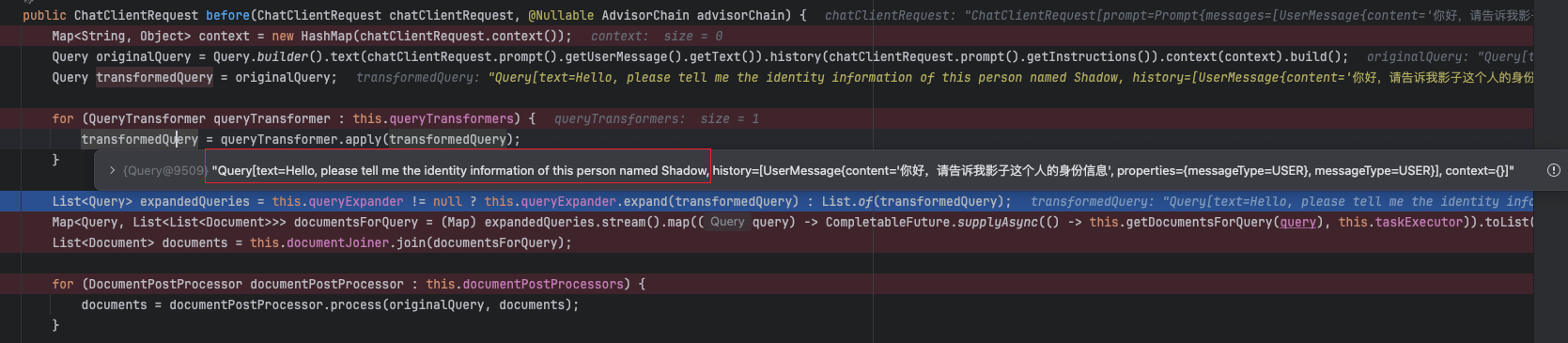
默认是增加 3 个,且保留原来的 1 个
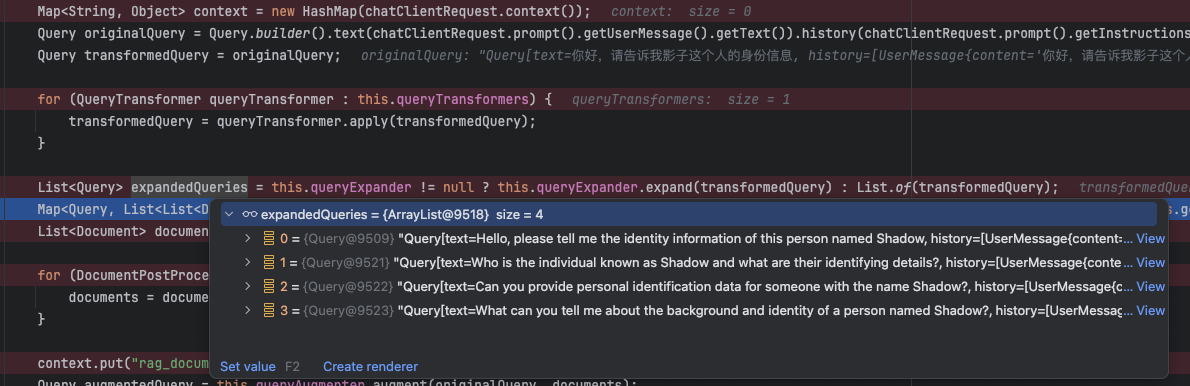
从向量存储中检索文档

将检索到的文档进行拼接

选择第一个
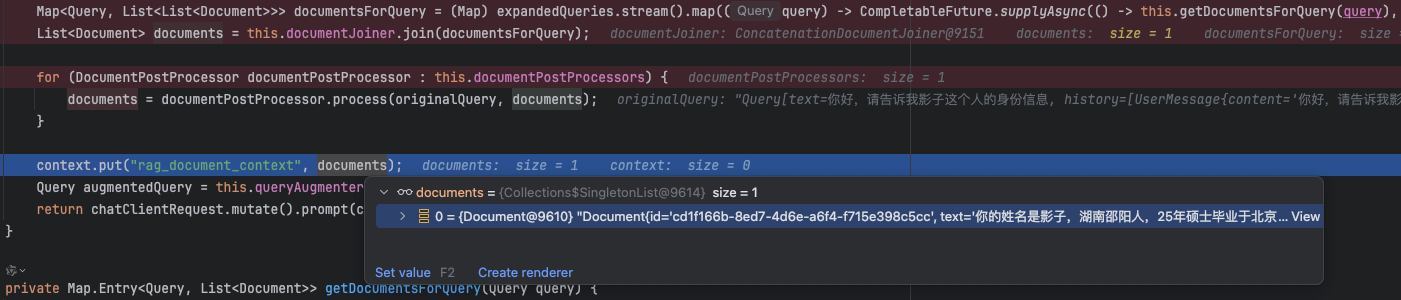
增加的上下文信息

RAG 的 ETL Pipeline 快速上手
提取(Extract)、转换(Transform)和加载(Load)框架是 Rag 中数据处理的链路,将原始数据源导入到向量化存储的流程,确保数据处于最佳格式,以便 AI 模型进行检索。实战代码可见:https://github.com/GTyingzi/spring-ai-tutorial 下的rag/rag-etl-pipeline
pom 文件
<dependencies>
<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-autoconfigure-model-openai</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-commons</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-rag</artifactId> </dependency>
<dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-jsoup-document-reader</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-markdown-document-reader</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-pdf-document-reader</artifactId> </dependency> <dependency> <groupId>org.springframework.ai</groupId> <artifactId>spring-ai-tika-document-reader</artifactId> </dependency>
</dependencies>application.yml
server: port: 8080
spring: application: name: rag-etl-pipeline
ai: openai: api-key: ${DASHSCOPEAPIKEY} base-url: https://dashscope.aliyuncs.com/compatible-mode chat: options: model: qwen-max embedding: options: model: text-embedding-v1提取文档
Constant
package com.spring.ai.tutorial.rag.model;
public class Constant {
public static final String PREFIX = "classpath:data/";
public static final String TEXTFILEPATH = PREFIX + "/text.txt";
public static final String JSONFILEPATH = PREFIX + "/text.json";
public static final String MARKDOWNFILEPATH = PREFIX + "/text.md";
public static final String PDFFILEPATH = PREFIX + "/google-ai-agents-whitepaper.pdf";;
public static final String HTMLFILEPATH = PREFIX + "/spring-ai.html";}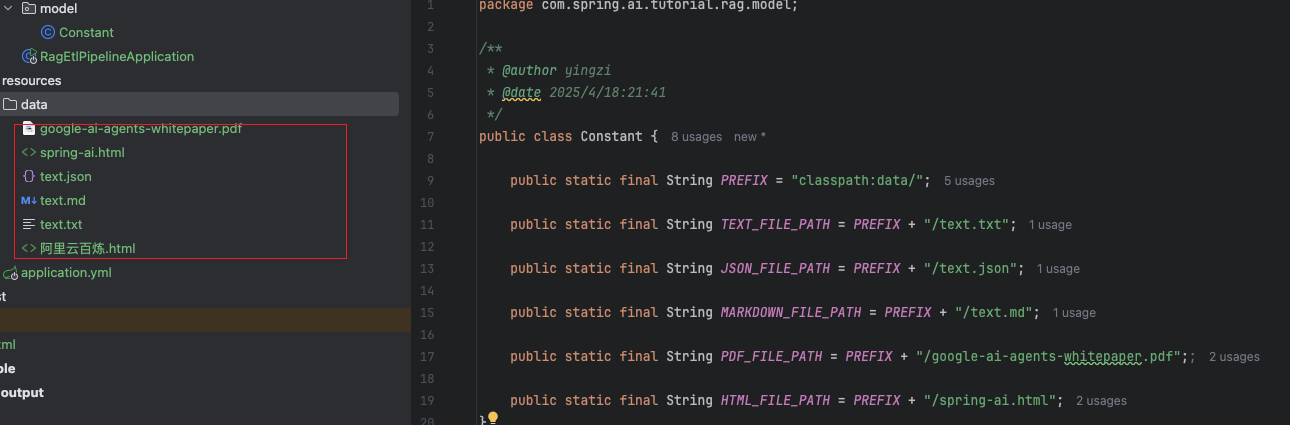
ReaderController
package com.spring.ai.tutorial.rag.controller;
import com.spring.ai.tutorial.rag.model.Constant;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.reader.JsonReader;import org.springframework.ai.reader.TextReader;import org.springframework.ai.reader.jsoup.JsoupDocumentReader;import org.springframework.ai.reader.markdown.MarkdownDocumentReader;import org.springframework.ai.reader.pdf.PagePdfDocumentReader;import org.springframework.ai.reader.pdf.ParagraphPdfDocumentReader;import org.springframework.ai.reader.tika.TikaDocumentReader;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController@RequestMapping("/reader")public class ReaderController {
private static final Logger logger = LoggerFactory.getLogger(ReaderController.class);
@GetMapping("/text") public List<Document> readText() { logger.info("start read text file"); Resource resource = new DefaultResourceLoader().getResource(Constant.TEXTFILEPATH); TextReader textReader = new TextReader(resource); // 适用于文本数据 return textReader.read(); }
@GetMapping("/json") public List<Document> readJson() { logger.info("start read json file"); Resource resource = new DefaultResourceLoader().getResource(Constant.JSONFILEPATH); JsonReader jsonReader = new JsonReader(resource); // 只可以传json格式文件 return jsonReader.read(); }
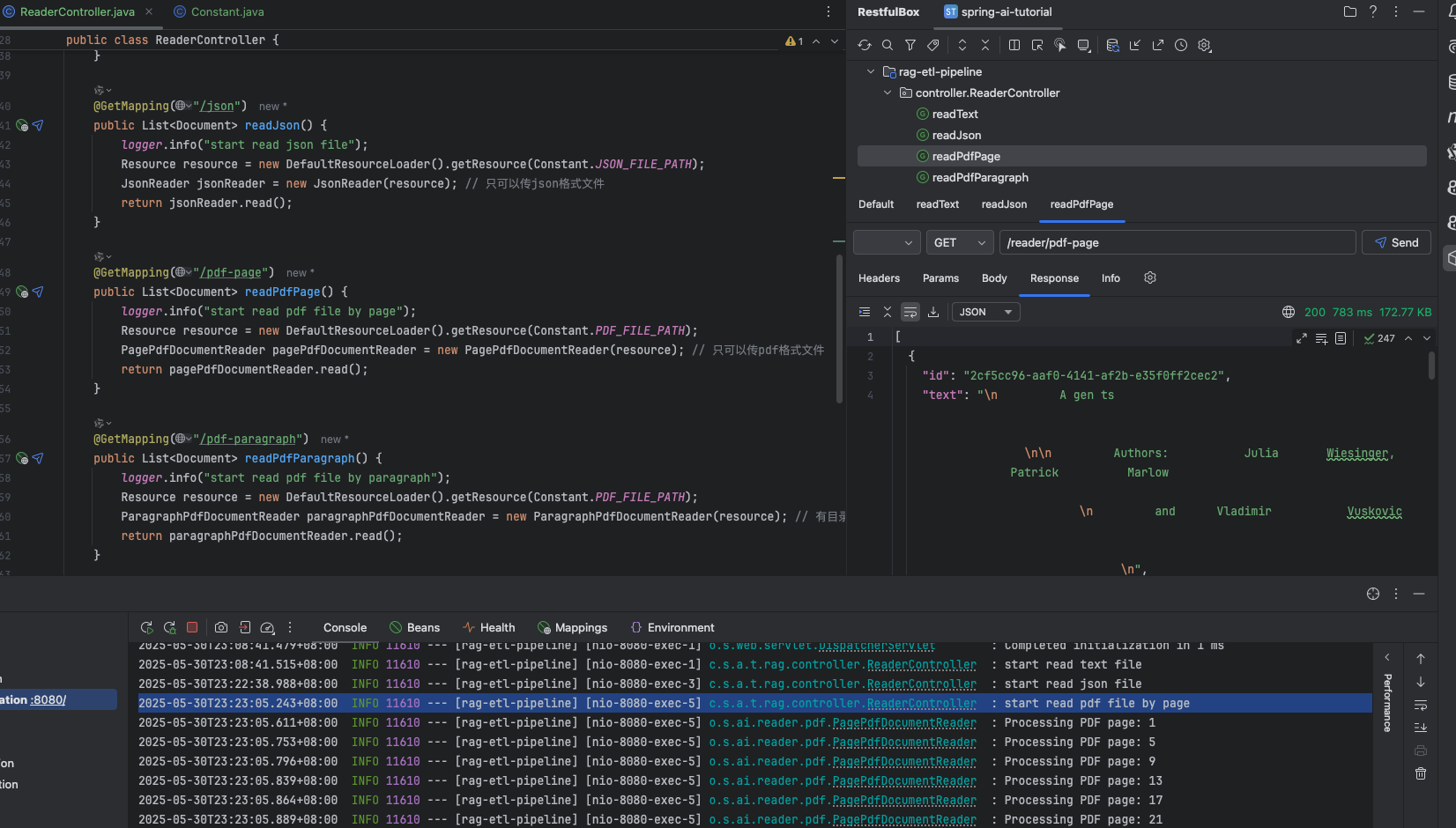
@GetMapping("/pdf-page") public List<Document> readPdfPage() { logger.info("start read pdf file by page"); Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH); PagePdfDocumentReader pagePdfDocumentReader = new PagePdfDocumentReader(resource); // 只可以传pdf格式文件 return pagePdfDocumentReader.read(); }
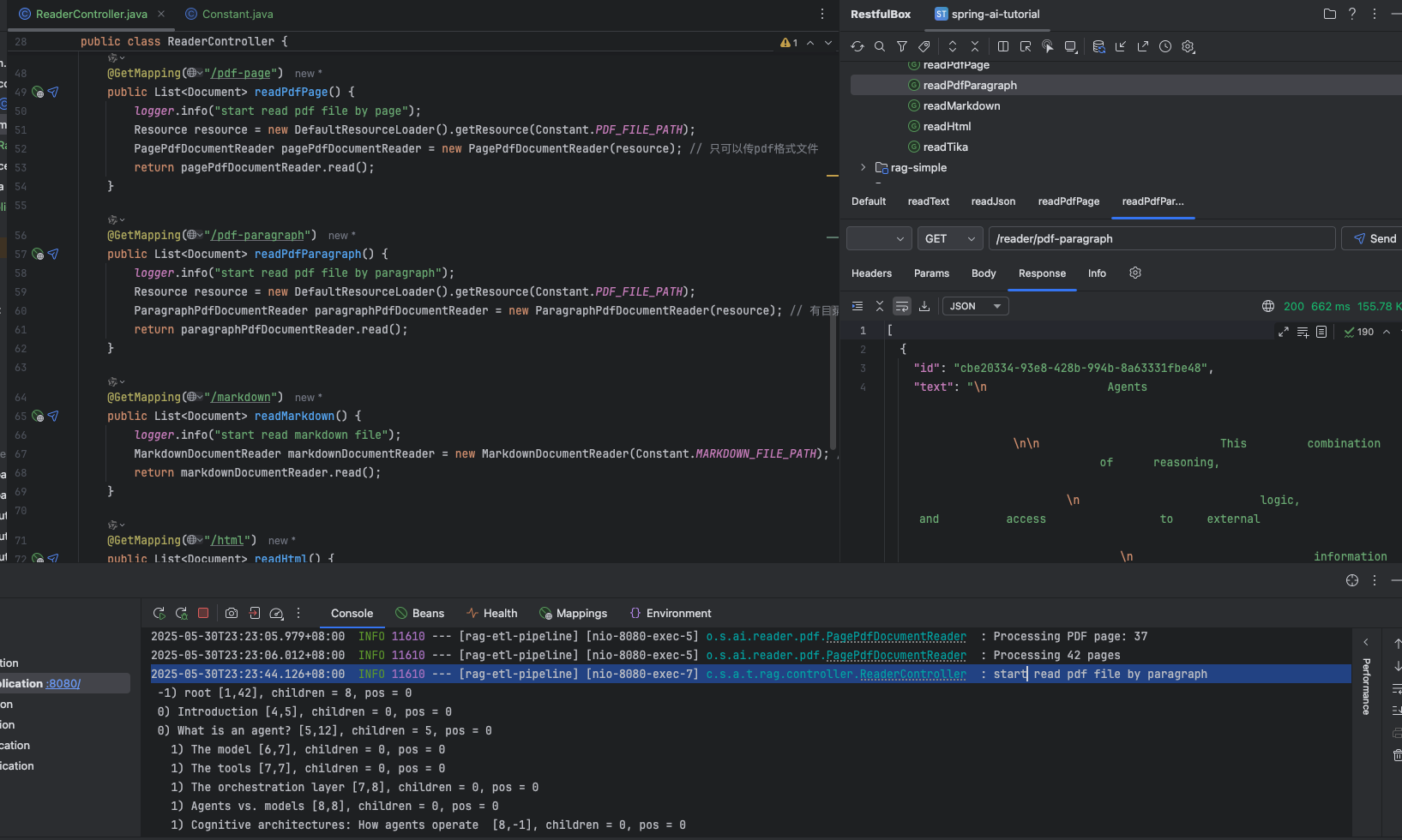
@GetMapping("/pdf-paragraph") public List<Document> readPdfParagraph() { logger.info("start read pdf file by paragraph"); Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH); ParagraphPdfDocumentReader paragraphPdfDocumentReader = new ParagraphPdfDocumentReader(resource); // 有目录的pdf文件 return paragraphPdfDocumentReader.read(); }
@GetMapping("/markdown") public List<Document> readMarkdown() { logger.info("start read markdown file"); MarkdownDocumentReader markdownDocumentReader = new MarkdownDocumentReader(Constant.MARKDOWNFILEPATH); // 只可以传markdown格式文件 return markdownDocumentReader.read(); }
@GetMapping("/html") public List<Document> readHtml() { logger.info("start read html file"); Resource resource = new DefaultResourceLoader().getResource(Constant.HTMLFILEPATH); JsoupDocumentReader jsoupDocumentReader = new JsoupDocumentReader(resource); // 只可以传html格式文件 return jsoupDocumentReader.read(); }
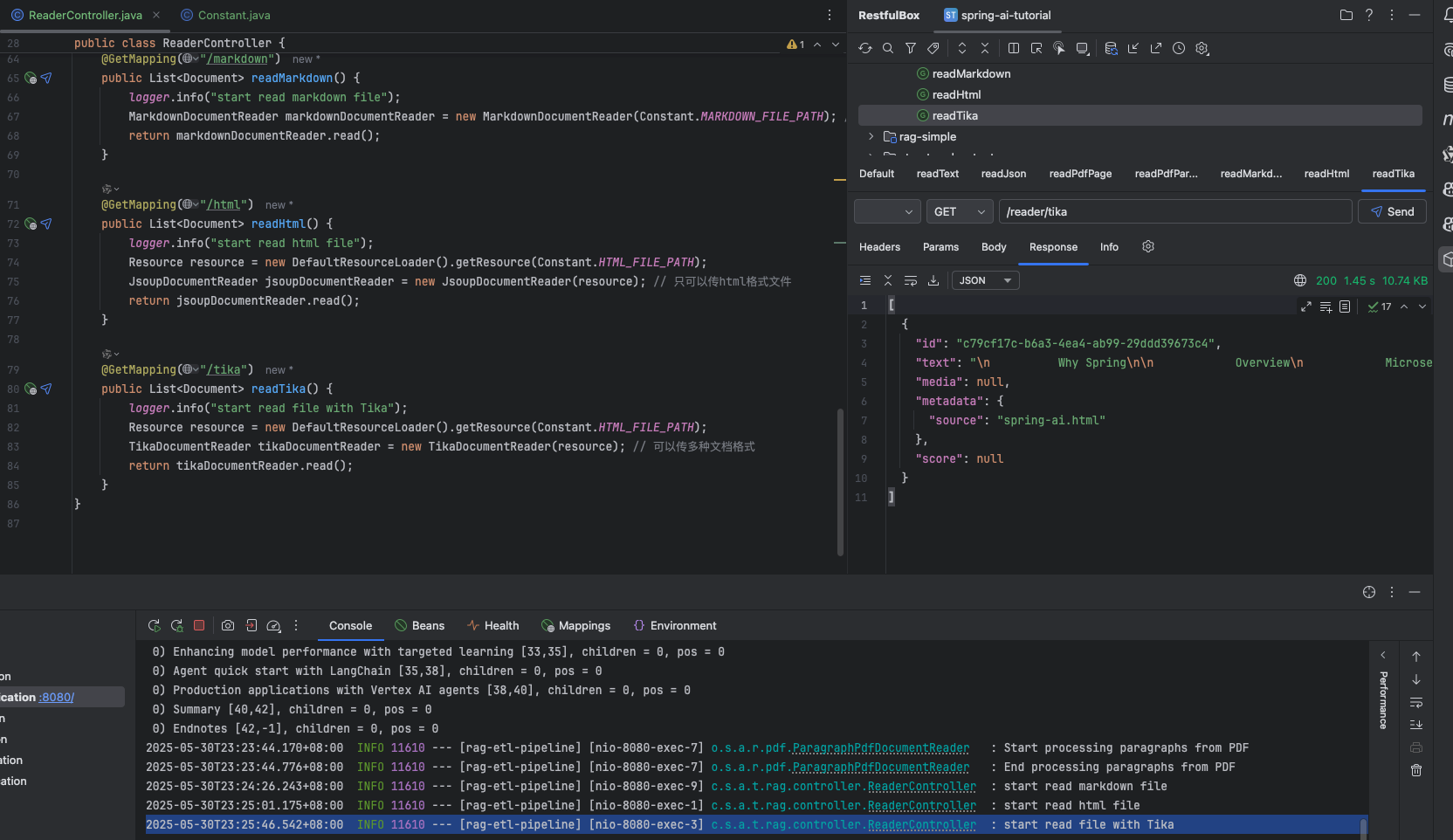
@GetMapping("/tika") public List<Document> readTika() { logger.info("start read file with Tika"); Resource resource = new DefaultResourceLoader().getResource(Constant.HTMLFILEPATH); TikaDocumentReader tikaDocumentReader = new TikaDocumentReader(resource); // 可以传多种文档格式 return tikaDocumentReader.read(); }}效果
读取文本文件
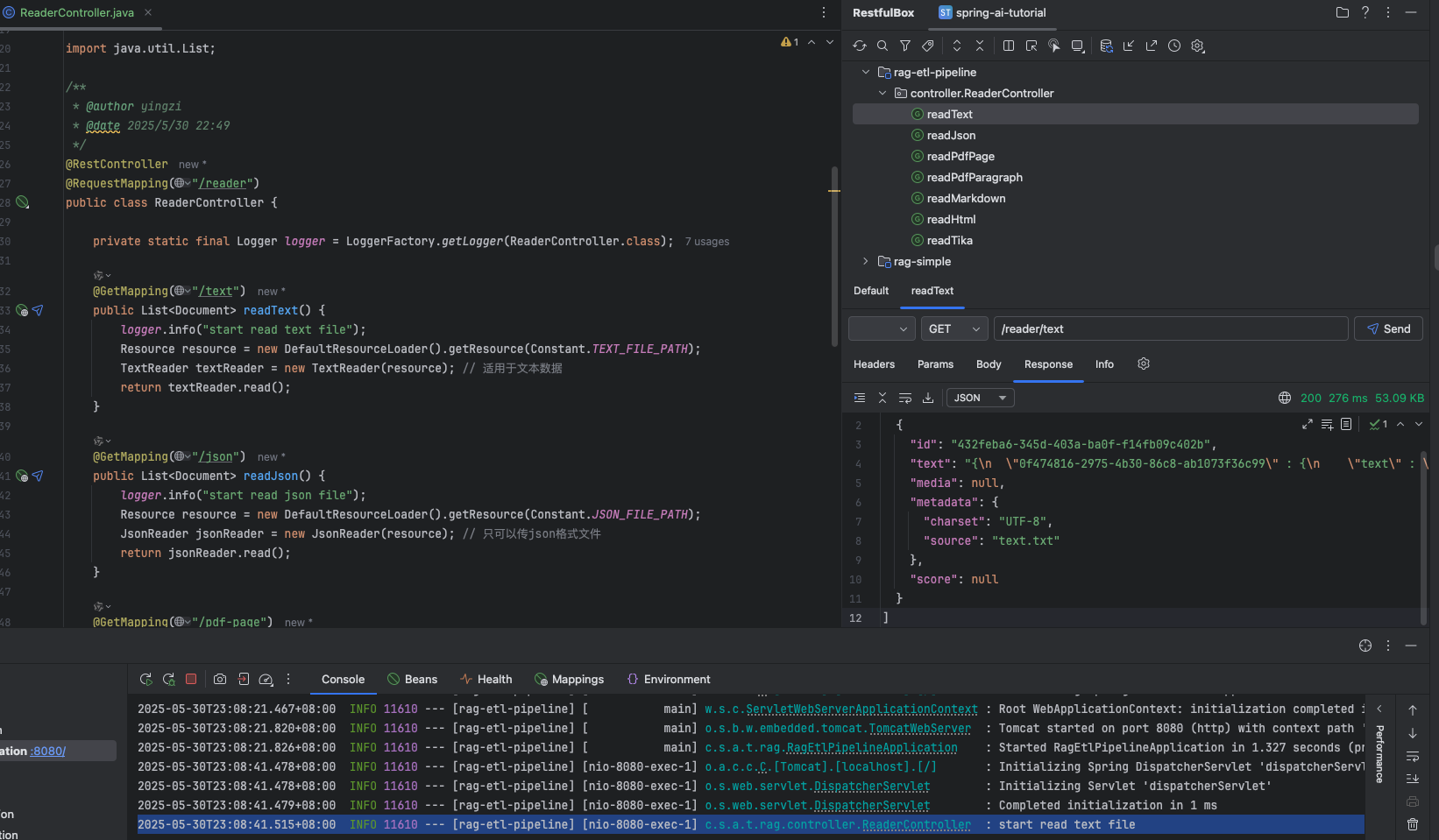
读取 json 文件
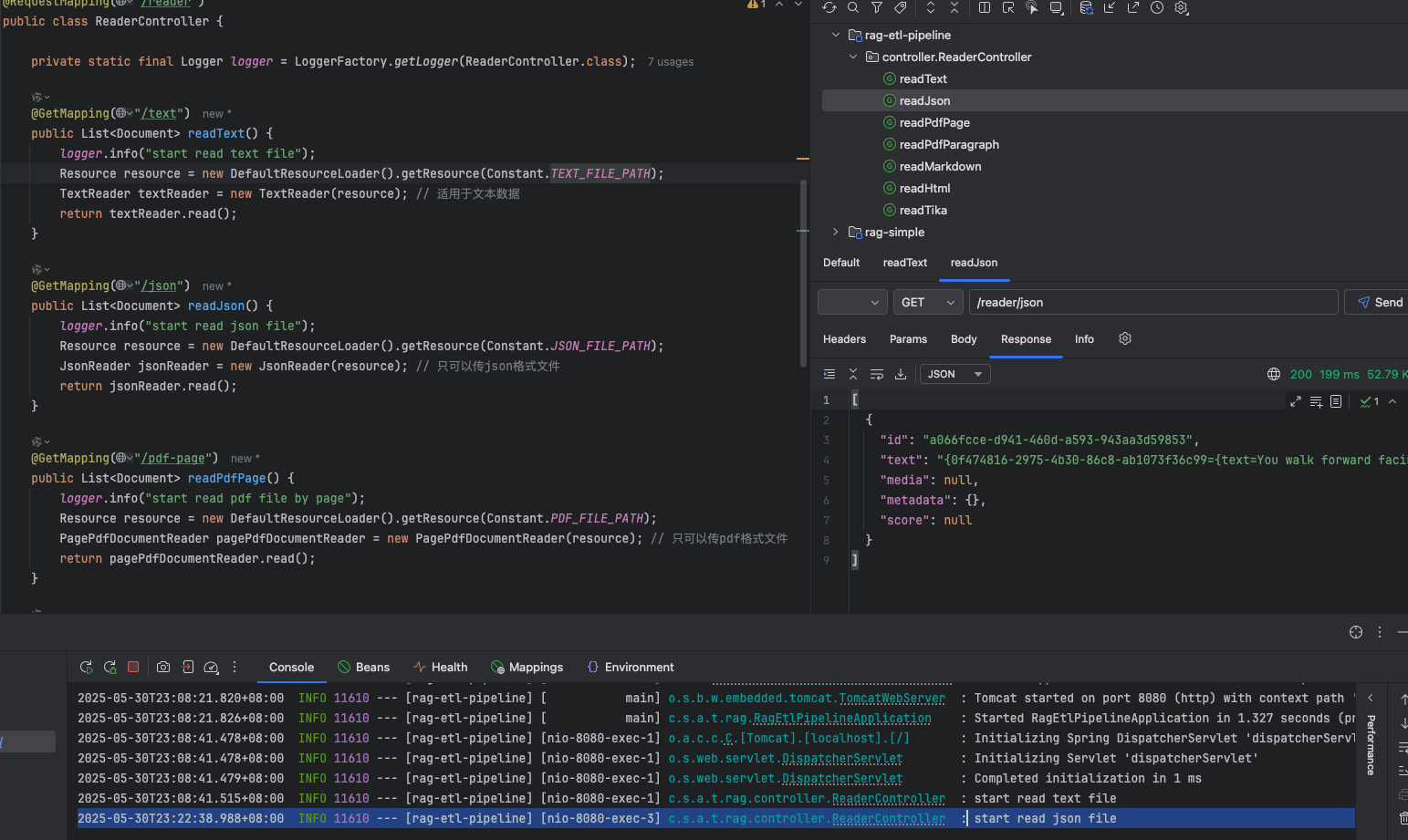
读取 pdf 文件
读取带目录的 pdf 文件
读取 markdown 文件
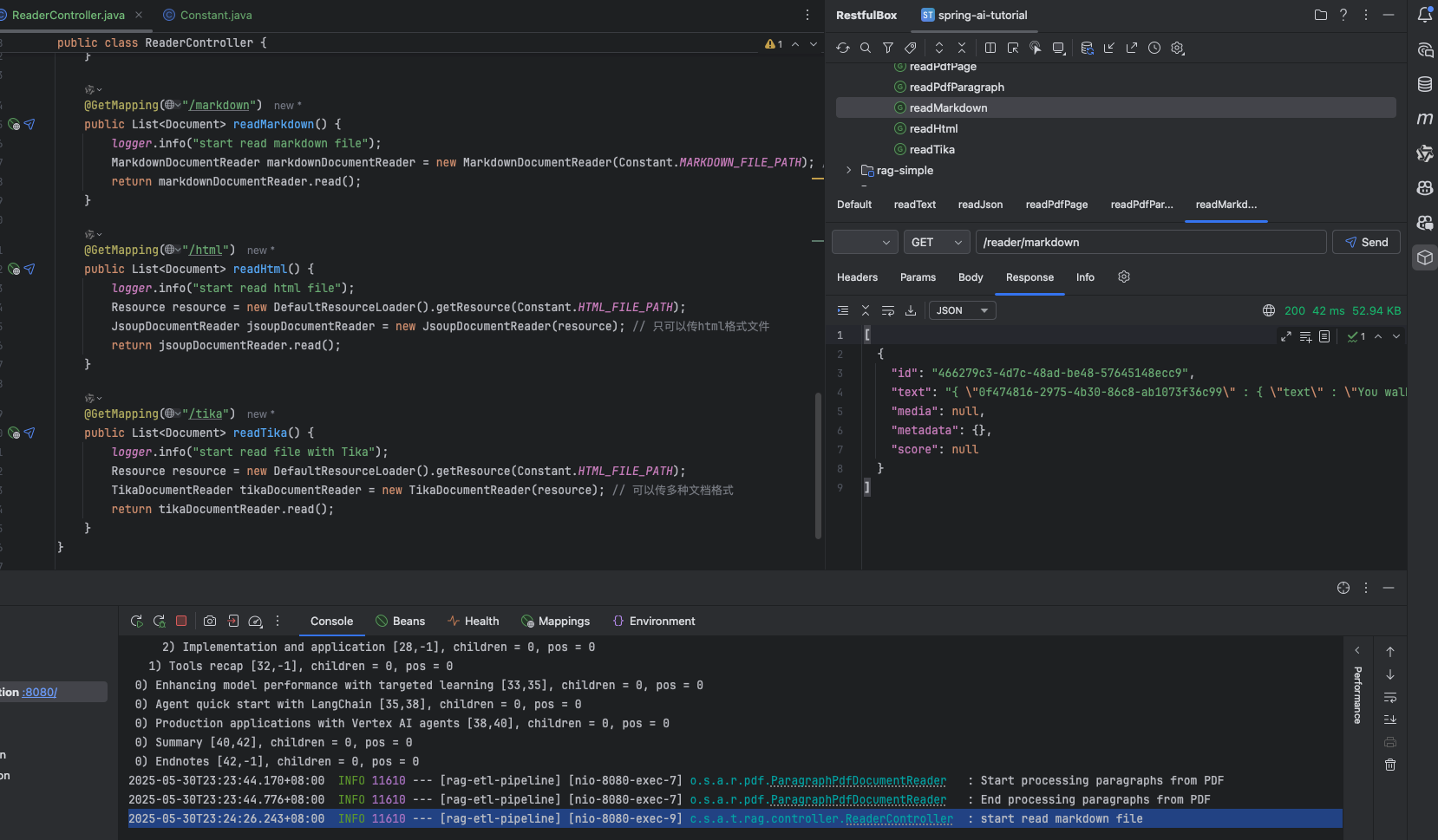
读取 html 文件
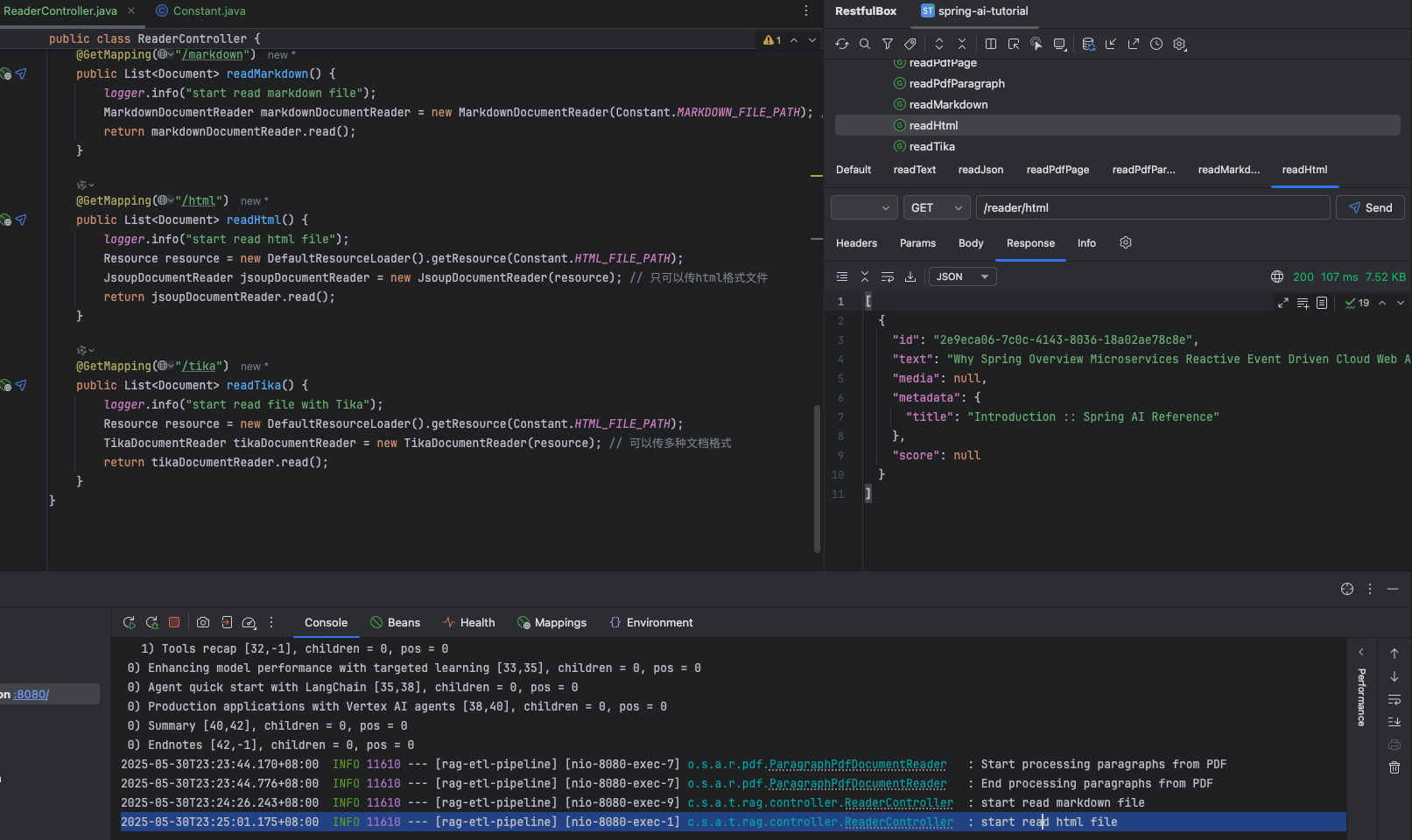
利用 tika 读取任意文档格式
转换文档
TransformerController
package com.spring.ai.tutorial.rag.controller;
import com.spring.ai.tutorial.rag.model.Constant;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.model.ChatModel;import org.springframework.ai.document.DefaultContentFormatter;import org.springframework.ai.document.Document;import org.springframework.ai.model.transformer.KeywordMetadataEnricher;import org.springframework.ai.model.transformer.SummaryMetadataEnricher;import org.springframework.ai.reader.pdf.PagePdfDocumentReader;import org.springframework.ai.transformer.ContentFormatTransformer;import org.springframework.ai.transformer.splitter.TokenTextSplitter;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;
import java.util.List;
@RestController@RequestMapping("/transformer")public class TransformerController {
private static final Logger logger = LoggerFactory.getLogger(TransformerController.class);
private final List<Document> documents; private final ChatModel chatModel;
public TransformerController(ChatModel chatModel) { logger.info("start read pdf file by page"); Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH); PagePdfDocumentReader pagePdfDocumentReader = new PagePdfDocumentReader(resource); // 只可以传pdf格式文件 this.documents = pagePdfDocumentReader.read();
this.chatModel = chatModel; }
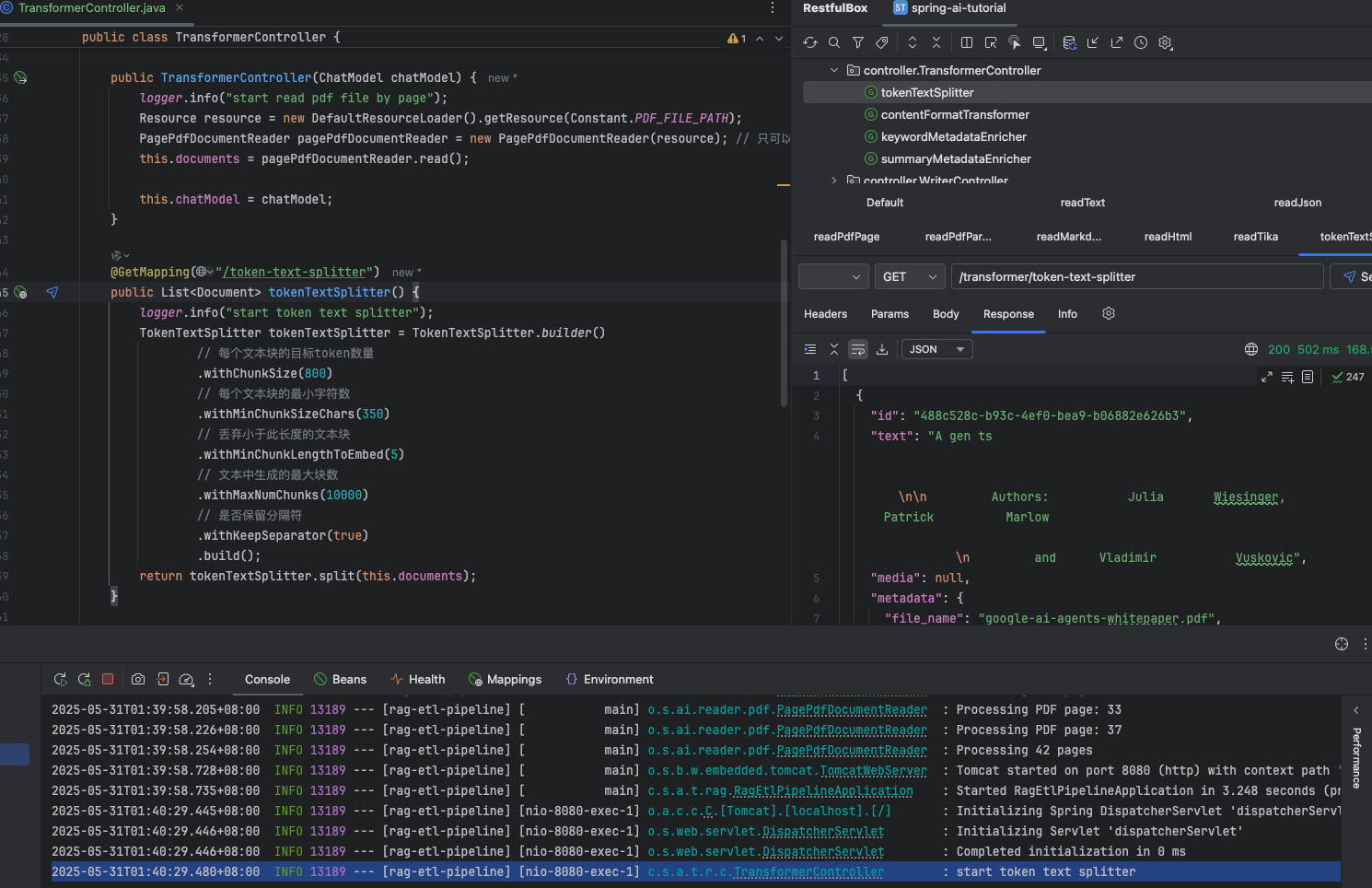
@GetMapping("/token-text-splitter") public List<Document> tokenTextSplitter() { logger.info("start token text splitter"); TokenTextSplitter tokenTextSplitter = TokenTextSplitter.builder() // 每个文本块的目标token数量 .withChunkSize(800) // 每个文本块的最小字符数 .withMinChunkSizeChars(350) // 丢弃小于此长度的文本块 .withMinChunkLengthToEmbed(5) // 文本中生成的最大块数 .withMaxNumChunks(10000) // 是否保留分隔符 .withKeepSeparator(true) .build(); return tokenTextSplitter.split(this.documents); }
@GetMapping("/content-format-transformer") public List<Document> contentFormatTransformer() { logger.info("start content format transformer"); DefaultContentFormatter defaultContentFormatter = DefaultContentFormatter.defaultConfig();
ContentFormatTransformer contentFormatTransformer = new ContentFormatTransformer(defaultContentFormatter);
return contentFormatTransformer.apply(this.documents); }
@GetMapping("/keyword-metadata-enricher") public List<Document> keywordMetadataEnricher() { logger.info("start keyword metadata enricher"); KeywordMetadataEnricher keywordMetadataEnricher = new KeywordMetadataEnricher(this.chatModel, 3); return keywordMetadataEnricher.apply(this.documents); }
@GetMapping("/summary-metadata-enricher") public List<Document> summaryMetadataEnricher() { logger.info("start summary metadata enricher"); List<SummaryMetadataEnricher.SummaryType> summaryTypes = List.of( SummaryMetadataEnricher.SummaryType.NEXT, SummaryMetadataEnricher.SummaryType.CURRENT, SummaryMetadataEnricher.SummaryType.PREVIOUS); SummaryMetadataEnricher summaryMetadataEnricher = new SummaryMetadataEnricher(this.chatModel, summaryTypes);
return summaryMetadataEnricher.apply(this.documents); }}效果
TokenTextSplitter 切分
DefaultContentFormatter 格式化
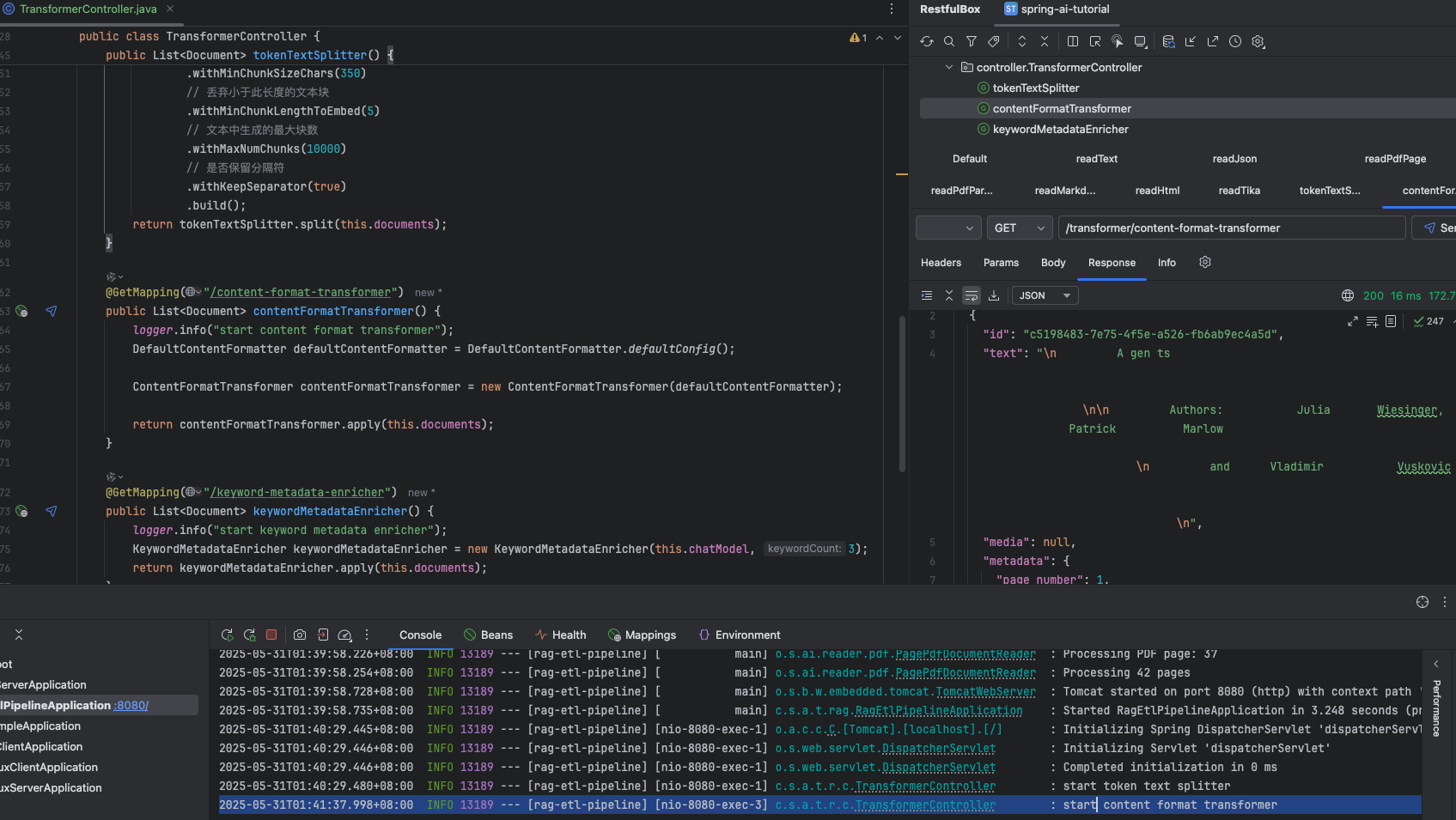
KeywordMetadataEnricher 提取关键字
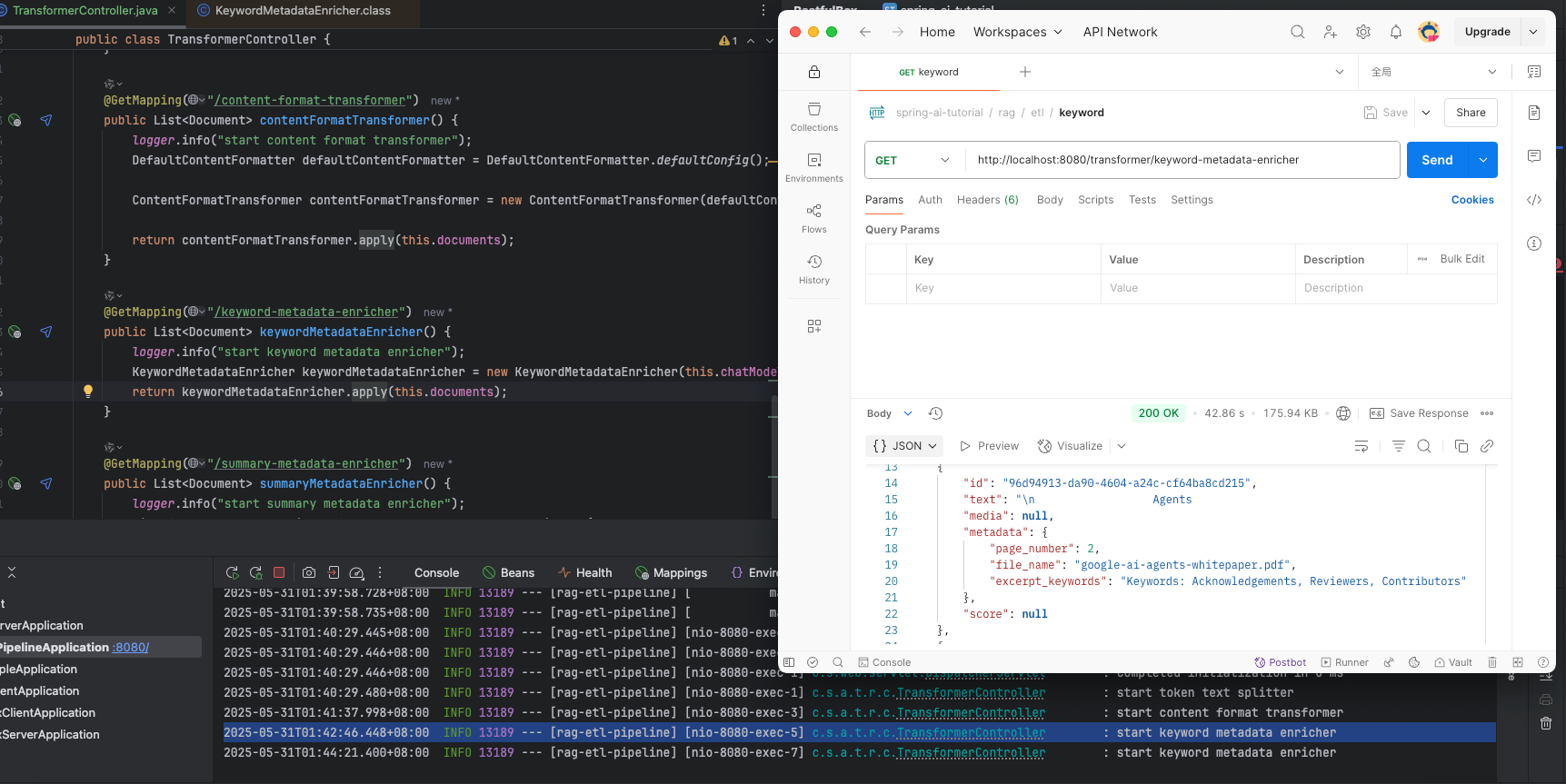
SummaryMetadataEnricher 提取摘要
写出文档
WriterController
package com.spring.ai.tutorial.rag.controller;
import com.spring.ai.tutorial.rag.model.Constant;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.embedding.EmbeddingModel;import org.springframework.ai.reader.pdf.PagePdfDocumentReader;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.SimpleVectorStore;import org.springframework.ai.writer.FileDocumentWriter;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.web.bind.annotation.GetMapping;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;
import java.util.List;
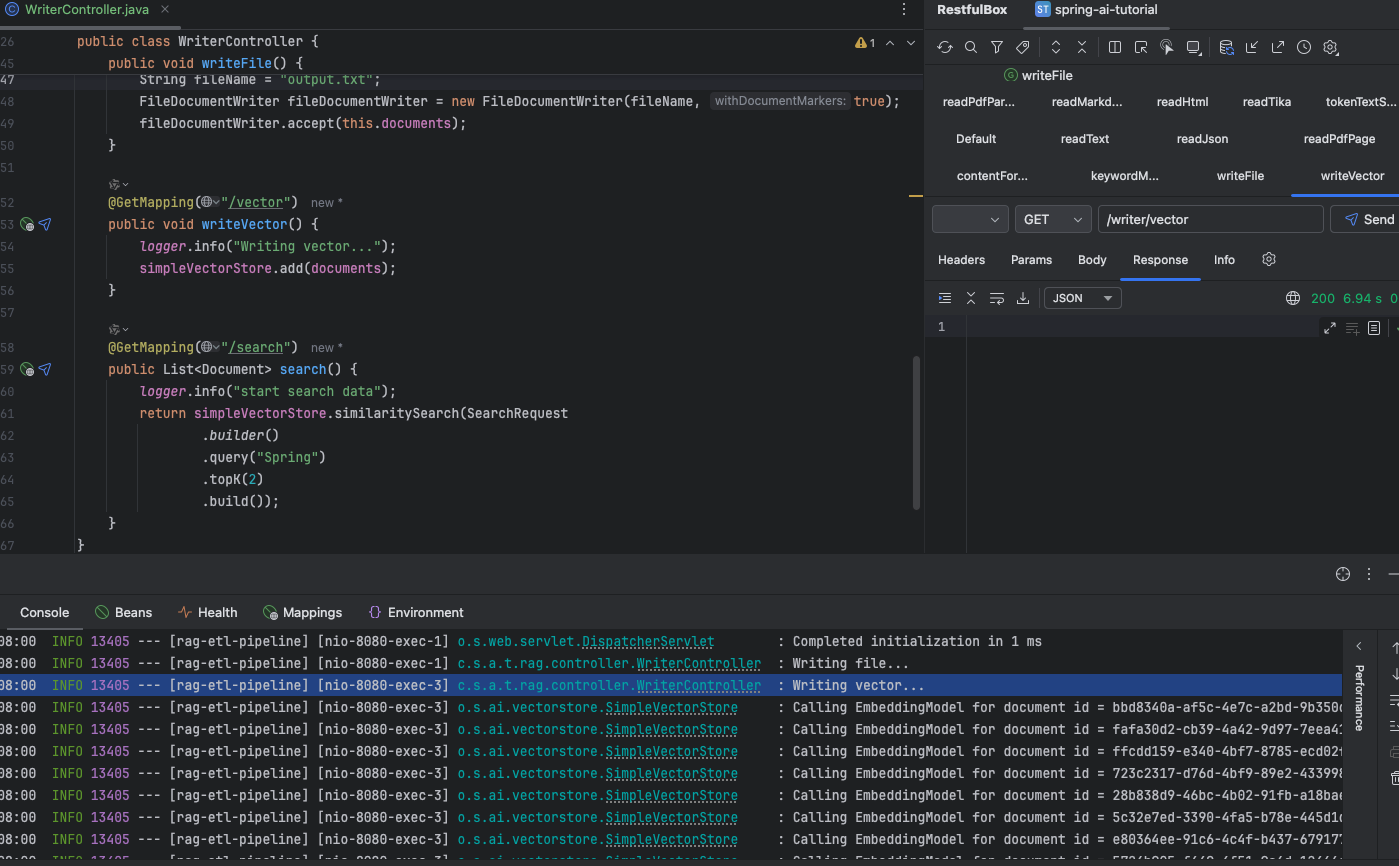
@RestController@RequestMapping("/writer")public class WriterController {
private static final Logger logger = LoggerFactory.getLogger(WriterController.class);
private final List<Document> documents;
private final SimpleVectorStore simpleVectorStore;
public WriterController(EmbeddingModel embeddingModel) { logger.info("start read pdf file by page"); Resource resource = new DefaultResourceLoader().getResource(Constant.PDFFILEPATH); PagePdfDocumentReader pagePdfDocumentReader = new PagePdfDocumentReader(resource); // 只可以传pdf格式文件 this.documents = pagePdfDocumentReader.read();
this.simpleVectorStore = SimpleVectorStore .builder(embeddingModel).build(); }
@GetMapping("/file") public void writeFile() { logger.info("Writing file..."); String fileName = "output.txt"; FileDocumentWriter fileDocumentWriter = new FileDocumentWriter(fileName, true); fileDocumentWriter.accept(this.documents); }
@GetMapping("/vector") public void writeVector() { logger.info("Writing vector..."); simpleVectorStore.add(documents); }
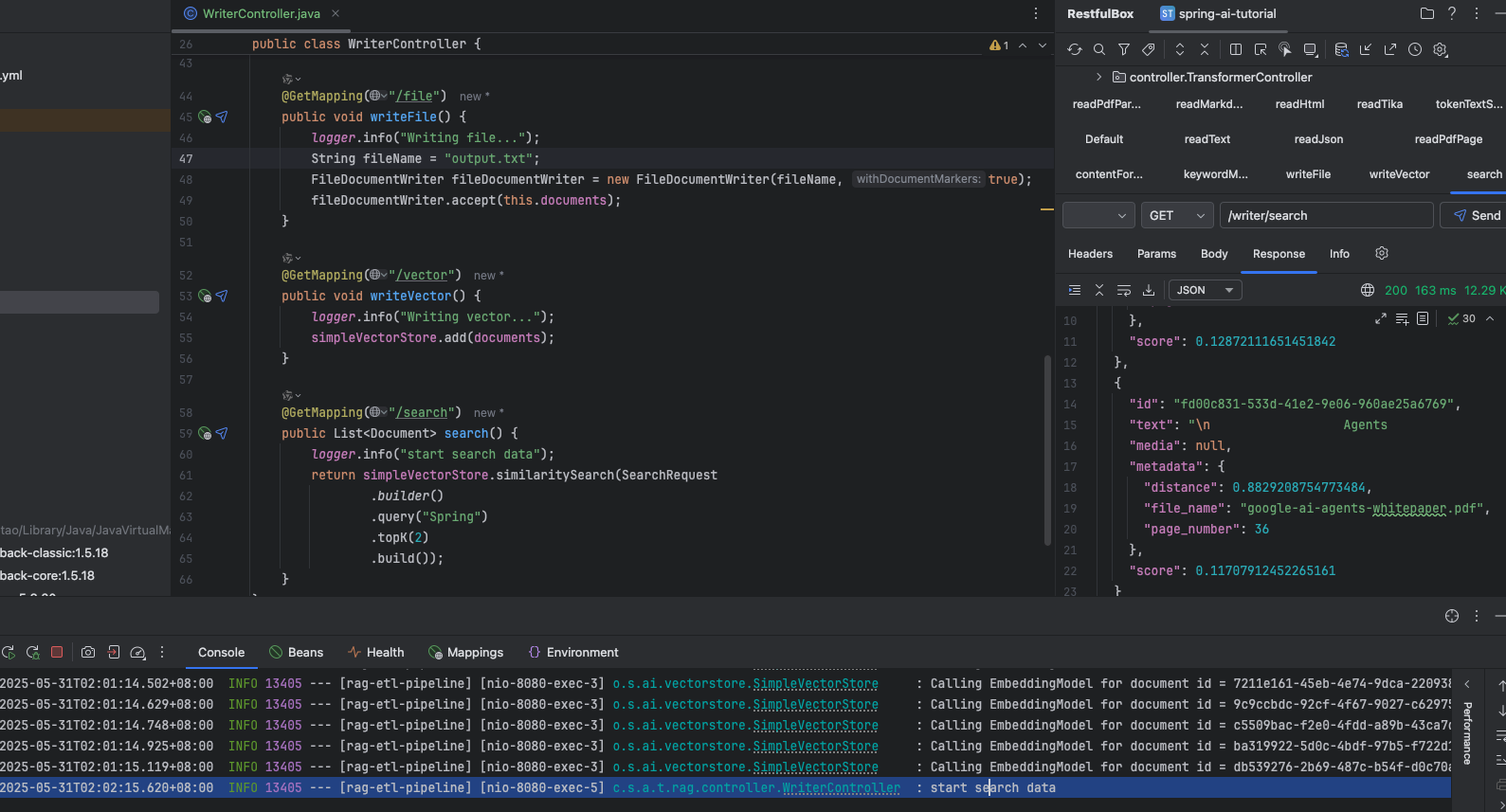
@GetMapping("/search") public List<Document> search() { logger.info("start search data"); return simpleVectorStore.similaritySearch(SearchRequest .builder() .query("Spring") .topK(2) .build()); }}效果
Document 写出文本文件
写入 vector
从 vector 中查找
Rag 模块化源码篇
Spring AI 实现了一个模块化的 RAG 架构,其灵感来自于论文:Modular RAG: Transforming RAG Systems into LEGO-like Reconfigurable Frameworks,本文是 RAG 模块化源码的讲解
RetrievalAugmentationAdvisor
RAG 增强器,利用模块化 RAG 组件(Query、Pre-Retrieval、Retrieval、Post-Retrieval、Generation)为用户文本添加额外信息
核心方法是 before、after
before:
- 创建原始查询(originalQuery):从用户输入的文本、参数和对话历史中构建一个 Query 对象,作为后续处理的基础
- 查询转换(transformedQuery):依次通过 queryTransformers 列表中的每个 QueryTransformer,对原始查询进行转换。每个转换器可以对查询内容进行修改(如规范化、重写等),形成最终的 transformedQuery
- 查询扩展(expandedQueries):若配置了 queryExpander,则用它将转换后的查询扩展为一个或多个查询(如同义词扩展、多轮问答等),否则只用转换后的查询本身
- 检索相关文档(documentsForQuery):对每个扩展后的查询,异步调用 getDocumentsForQuery 方法,通过 documentRetriever 检索与查询相关的文档。所有结果以 Map<Query, List<List
>> 形式收集 - 文档合并(documents):使用 documentJoiner 将所有查询检索到的文档合并成一个文档列表,便于后续处理
- 文档后处理(Post-process):依次通过 documentPostProcessors 列表中的每个处理器,对合并后的文档进行进一步处理(如去重、排序、摘要等)。处理结果存入上下文 context
- 查询增强(Augment):用 queryAugmenter 将原始查询和检索到的文档结合,生成带有文档上下文信息的增强查询(如将文档内容拼接到用户问题后)
- 更新请求(Update Request):用增强后的查询内容更新 ChatClientRequest,并将文档上下文写入请求上下文,返回新的请求对象用于后续流程
after:
- 将 RAG 过程中检索到的文档添加到元数据中,键为”ragdocumentcontext”
package org.springframework.ai.rag.advisor;
import java.util.Arrays;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.concurrent.CompletableFuture;import java.util.stream.Collectors;import org.springframework.ai.chat.client.ChatClientRequest;import org.springframework.ai.chat.client.ChatClientResponse;import org.springframework.ai.chat.client.advisor.api.AdvisorChain;import org.springframework.ai.chat.client.advisor.api.BaseAdvisor;import org.springframework.ai.chat.model.ChatResponse;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;import org.springframework.ai.rag.generation.augmentation.ContextualQueryAugmenter;import org.springframework.ai.rag.generation.augmentation.QueryAugmenter;import org.springframework.ai.rag.postretrieval.document.DocumentPostProcessor;import org.springframework.ai.rag.preretrieval.query.expansion.QueryExpander;import org.springframework.ai.rag.preretrieval.query.transformation.QueryTransformer;import org.springframework.ai.rag.retrieval.join.ConcatenationDocumentJoiner;import org.springframework.ai.rag.retrieval.join.DocumentJoiner;import org.springframework.ai.rag.retrieval.search.DocumentRetriever;import org.springframework.core.task.TaskExecutor;import org.springframework.core.task.support.ContextPropagatingTaskDecorator;import org.springframework.lang.Nullable;import org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor;import org.springframework.util.Assert;import reactor.core.scheduler.Scheduler;
public final class RetrievalAugmentationAdvisor implements BaseAdvisor { public static final String DOCUMENTCONTEXT = "ragdocumentcontext"; private final List<QueryTransformer> queryTransformers; @Nullable private final QueryExpander queryExpander; private final DocumentRetriever documentRetriever; private final DocumentJoiner documentJoiner; private final List<DocumentPostProcessor> documentPostProcessors; private final QueryAugmenter queryAugmenter; private final TaskExecutor taskExecutor; private final Scheduler scheduler; private final int order;
private RetrievalAugmentationAdvisor(@Nullable List<QueryTransformer> queryTransformers, @Nullable QueryExpander queryExpander, DocumentRetriever documentRetriever, @Nullable DocumentJoiner documentJoiner, @Nullable List<DocumentPostProcessor> documentPostProcessors, @Nullable QueryAugmenter queryAugmenter, @Nullable TaskExecutor taskExecutor, @Nullable Scheduler scheduler, @Nullable Integer order) { Assert.notNull(documentRetriever, "documentRetriever cannot be null"); Assert.noNullElements(queryTransformers, "queryTransformers cannot contain null elements"); this.queryTransformers = queryTransformers != null ? queryTransformers : List.of(); this.queryExpander = queryExpander; this.documentRetriever = documentRetriever; this.documentJoiner = (DocumentJoiner)(documentJoiner != null ? documentJoiner : new ConcatenationDocumentJoiner()); this.documentPostProcessors = documentPostProcessors != null ? documentPostProcessors : List.of(); this.queryAugmenter = (QueryAugmenter)(queryAugmenter != null ? queryAugmenter : ContextualQueryAugmenter.builder().build()); this.taskExecutor = taskExecutor != null ? taskExecutor : buildDefaultTaskExecutor(); this.scheduler = scheduler != null ? scheduler : BaseAdvisor.DEFAULTSCHEDULER; this.order = order != null ? order : 0; }
public static Builder builder() { return new Builder(); }
public ChatClientRequest before(ChatClientRequest chatClientRequest, @Nullable AdvisorChain advisorChain) { Map<String, Object> context = new HashMap(chatClientRequest.context()); Query originalQuery = Query.builder().text(chatClientRequest.prompt().getUserMessage().getText()).history(chatClientRequest.prompt().getInstructions()).context(context).build(); Query transformedQuery = originalQuery;
for(QueryTransformer queryTransformer : this.queryTransformers) { transformedQuery = queryTransformer.apply(transformedQuery); }
List<Query> expandedQueries = this.queryExpander != null ? this.queryExpander.expand(transformedQuery) : List.of(transformedQuery); Map<Query, List<List<Document>>> documentsForQuery = (Map)expandedQueries.stream().map((query) -> CompletableFuture.supplyAsync(() -> this.getDocumentsForQuery(query), this.taskExecutor)).toList().stream().map(CompletableFuture::join).collect(Collectors.toMap(Map.Entry::getKey, (entry) -> List.of((List)entry.getValue()))); List<Document> documents = this.documentJoiner.join(documentsForQuery);
for(DocumentPostProcessor documentPostProcessor : this.documentPostProcessors) { documents = documentPostProcessor.process(originalQuery, documents); }
context.put("ragdocumentcontext", documents); Query augmentedQuery = this.queryAugmenter.augment(originalQuery, documents); return chatClientRequest.mutate().prompt(chatClientRequest.prompt().augmentUserMessage(augmentedQuery.text())).context(context).build(); }
private Map.Entry<Query, List<Document>> getDocumentsForQuery(Query query) { List<Document> documents = this.documentRetriever.retrieve(query); return Map.entry(query, documents); }
public ChatClientResponse after(ChatClientResponse chatClientResponse, @Nullable AdvisorChain advisorChain) { ChatResponse.Builder chatResponseBuilder; if (chatClientResponse.chatResponse() == null) { chatResponseBuilder = ChatResponse.builder(); } else { chatResponseBuilder = ChatResponse.builder().from(chatClientResponse.chatResponse()); }
chatResponseBuilder.metadata("ragdocumentcontext", chatClientResponse.context().get("ragdocumentcontext")); return ChatClientResponse.builder().chatResponse(chatResponseBuilder.build()).context(chatClientResponse.context()).build(); }
public Scheduler getScheduler() { return this.scheduler; }
public int getOrder() { return this.order; }
private static TaskExecutor buildDefaultTaskExecutor() { ThreadPoolTaskExecutor taskExecutor = new ThreadPoolTaskExecutor(); taskExecutor.setThreadNamePrefix("ai-advisor-"); taskExecutor.setCorePoolSize(4); taskExecutor.setMaxPoolSize(16); taskExecutor.setTaskDecorator(new ContextPropagatingTaskDecorator()); taskExecutor.initialize(); return taskExecutor; }
public static final class Builder { private List<QueryTransformer> queryTransformers; private QueryExpander queryExpander; private DocumentRetriever documentRetriever; private DocumentJoiner documentJoiner; private List<DocumentPostProcessor> documentPostProcessors; private QueryAugmenter queryAugmenter; private TaskExecutor taskExecutor; private Scheduler scheduler; private Integer order;
private Builder() { }
public Builder queryTransformers(List<QueryTransformer> queryTransformers) { Assert.noNullElements(queryTransformers, "queryTransformers cannot contain null elements"); this.queryTransformers = queryTransformers; return this; }
public Builder queryTransformers(QueryTransformer... queryTransformers) { Assert.notNull(queryTransformers, "queryTransformers cannot be null"); Assert.noNullElements(queryTransformers, "queryTransformers cannot contain null elements"); this.queryTransformers = Arrays.asList(queryTransformers); return this; }
public Builder queryExpander(QueryExpander queryExpander) { this.queryExpander = queryExpander; return this; }
public Builder documentRetriever(DocumentRetriever documentRetriever) { this.documentRetriever = documentRetriever; return this; }
public Builder documentJoiner(DocumentJoiner documentJoiner) { this.documentJoiner = documentJoiner; return this; }
public Builder documentPostProcessors(List<DocumentPostProcessor> documentPostProcessors) { Assert.noNullElements(documentPostProcessors, "documentPostProcessors cannot contain null elements"); this.documentPostProcessors = documentPostProcessors; return this; }
public Builder documentPostProcessors(DocumentPostProcessor... documentPostProcessors) { Assert.notNull(documentPostProcessors, "documentPostProcessors cannot be null"); Assert.noNullElements(documentPostProcessors, "documentPostProcessors cannot contain null elements"); this.documentPostProcessors = Arrays.asList(documentPostProcessors); return this; }
public Builder queryAugmenter(QueryAugmenter queryAugmenter) { this.queryAugmenter = queryAugmenter; return this; }
public Builder taskExecutor(TaskExecutor taskExecutor) { this.taskExecutor = taskExecutor; return this; }
public Builder scheduler(Scheduler scheduler) { this.scheduler = scheduler; return this; }
public Builder order(Integer order) { this.order = order; return this; }
public RetrievalAugmentationAdvisor build() { return new RetrievalAugmentationAdvisor(this.queryTransformers, this.queryExpander, this.documentRetriever, this.documentJoiner, this.documentPostProcessors, this.queryAugmenter, this.taskExecutor, this.scheduler, this.order); } }}Query
用于在 RAG 流程中表示查询的类
String text:查询的文本内容,用户输入的核心查询语句List<Message> history:当前查询相关的对话历史记录Map<String, Object> context:查询的上下文信息,键值对集合,用于存储与查询相关的额外数据
package org.springframework.ai.rag;
import java.util.List;import java.util.Map;import org.springframework.ai.chat.messages.Message;import org.springframework.util.Assert;
public record Query(String text, List<Message> history, Map<String, Object> context) { public Query { Assert.hasText(text, "text cannot be null or empty"); Assert.notNull(history, "history cannot be null"); Assert.noNullElements(history, "history elements cannot be null"); Assert.notNull(context, "context cannot be null"); Assert.noNullElements(context.keySet(), "context keys cannot be null"); }
public Query(String text) { this(text, List.of(), Map.of()); }
public Builder mutate() { return (new Builder()).text(this.text).history(this.history).context(this.context); }
public static Builder builder() { return new Builder(); }
public static final class Builder { private String text; private List<Message> history = List.of(); private Map<String, Object> context = Map.of();
private Builder() { }
public Builder text(String text) { this.text = text; return this; }
public Builder history(List<Message> history) { this.history = history; return this; }
public Builder history(Message... history) { this.history = List.of(history); return this; }
public Builder context(Map<String, Object> context) { this.context = context; return this; }
public Query build() { return new Query(this.text, this.history, this.context); } }}Pre-Retrieval
QueryExpander(查询扩展接口类)
作用:
- 处理不规范的查询:通过提供替代的查询表达式,帮助改善查询质量
- 分解复杂问题:将复杂的查询拆分为更简单的子查询,便于后续处理
package org.springframework.ai.rag.preretrieval.query.expansion;
import java.util.List;import java.util.function.Function;import org.springframework.ai.rag.Query;
public interface QueryExpander extends Function<Query, List<Query>> { List<Query> expand(Query query);
default List<Query> apply(Query query) { return this.expand(query); }}MultiQueryExpander
扩展查询的类,通过使用 LLM 将单个查询扩展为多个语义上多样化的变体,这些变体能从不同角度或方面覆盖原始查询的主题,从而增加检索到相关结果的机会
字段的含义
ChatClient chatClient:用于与大语言模型进行交互,生成查询的变体PromptTemplate promptTemplate:定义生成查询变体的提示模版。默认模板要求生成指定数量的查询变体,每个变体需覆盖不同的视角或方面。boolean includeOriginal:是否在生成的查询列表中包含原始查询,默认为 trueint numberOfQueries:指定生成的查询变体的数量
package org.springframework.ai.rag.preretrieval.query.expansion;
import java.util.Arrays;import java.util.List;import java.util.stream.Collectors;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.rag.Query;import org.springframework.ai.rag.util.PromptAssert;import org.springframework.lang.Nullable;import org.springframework.util.Assert;import org.springframework.util.CollectionUtils;import org.springframework.util.StringUtils;
public final class MultiQueryExpander implements QueryExpander { private static final Logger logger = LoggerFactory.getLogger(MultiQueryExpander.class); private static final PromptTemplate DEFAULTPROMPTTEMPLATE = new PromptTemplate("You are an expert at information retrieval and search optimization.\nYour task is to generate {number} different versions of the given query.\n\nEach variant must cover different perspectives or aspects of the topic,\nwhile maintaining the core intent of the original query. The goal is to\nexpand the search space and improve the chances of finding relevant information.\n\nDo not explain your choices or add any other text.\nProvide the query variants separated by newlines.\n\nOriginal query: {query}\n\nQuery variants:\n"); private static final Boolean DEFAULTINCLUDEORIGINAL = true; private static final Integer DEFAULTNUMBEROFQUERIES = 3; private final ChatClient chatClient; private final PromptTemplate promptTemplate; private final boolean includeOriginal; private final int numberOfQueries;
public MultiQueryExpander(ChatClient.Builder chatClientBuilder, @Nullable PromptTemplate promptTemplate, @Nullable Boolean includeOriginal, @Nullable Integer numberOfQueries) { Assert.notNull(chatClientBuilder, "chatClientBuilder cannot be null"); this.chatClient = chatClientBuilder.build(); this.promptTemplate = promptTemplate != null ? promptTemplate : DEFAULTPROMPTTEMPLATE; this.includeOriginal = includeOriginal != null ? includeOriginal : DEFAULTINCLUDEORIGINAL; this.numberOfQueries = numberOfQueries != null ? numberOfQueries : DEFAULTNUMBEROFQUERIES; PromptAssert.templateHasRequiredPlaceholders(this.promptTemplate, new String[]{"number", "query"}); }
public List<Query> expand(Query query) { Assert.notNull(query, "query cannot be null"); logger.debug("Generating {} query variants", this.numberOfQueries); String response = this.chatClient.prompt().user((user) -> user.text(this.promptTemplate.getTemplate()).param("number", this.numberOfQueries).param("query", query.text())).call().content(); if (response == null) { logger.warn("Query expansion result is null. Returning the input query unchanged."); return List.of(query); } else { List<String> queryVariants = Arrays.asList(response.split("\n")); if (!CollectionUtils.isEmpty(queryVariants) && this.numberOfQueries == queryVariants.size()) { List<Query> queries = (List)queryVariants.stream().filter(StringUtils::hasText).map((queryText) -> query.mutate().text(queryText).build()).collect(Collectors.toList()); if (this.includeOriginal) { logger.debug("Including the original query in the result"); queries.add(0, query); }
return queries; } else { logger.warn("Query expansion result does not contain the requested {} variants. Returning the input query unchanged.", this.numberOfQueries); return List.of(query); } } }
public static Builder builder() { return new Builder(); }
public static final class Builder { private ChatClient.Builder chatClientBuilder; private PromptTemplate promptTemplate; private Boolean includeOriginal; private Integer numberOfQueries;
private Builder() { }
public Builder chatClientBuilder(ChatClient.Builder chatClientBuilder) { this.chatClientBuilder = chatClientBuilder; return this; }
public Builder promptTemplate(PromptTemplate promptTemplate) { this.promptTemplate = promptTemplate; return this; }
public Builder includeOriginal(Boolean includeOriginal) { this.includeOriginal = includeOriginal; return this; }
public Builder numberOfQueries(Integer numberOfQueries) { this.numberOfQueries = numberOfQueries; return this; }
public MultiQueryExpander build() { return new MultiQueryExpander(this.chatClientBuilder, this.promptTemplate, this.includeOriginal, this.numberOfQueries); } }}QueryTransformer(查询转换接口类)
作用:
- 查询结构不完整或格式不佳
- 查询中的术语存在歧义
- 查询中使用了复杂或难以理解的词汇
- 查询使用了不受支持的语言
package org.springframework.ai.rag.preretrieval.query.transformation;
import java.util.function.Function;import org.springframework.ai.rag.Query;
public interface QueryTransformer extends Function<Query, Query> { Query transform(Query query);
default Query apply(Query query) { return this.transform(query); }}CompressionQueryTransformer
用于压缩对话历史和后续查询的类
作用:将对话上下文和后续查询合并为一个独立的查询,以捕获对话的核心内容。
适用场景:对话历史较长、后续查询与对话上下文相关
各字段含义:
ChatClient chatClient:用于与 LLM 交互,生成压缩后的查询PromptTemplate promptTemplate:自定义用于生产压缩查询的提示文本
package org.springframework.ai.rag.preretrieval.query.transformation;
import java.util.List;import java.util.stream.Collectors;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.chat.messages.Message;import org.springframework.ai.chat.messages.MessageType;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.rag.Query;import org.springframework.ai.rag.util.PromptAssert;import org.springframework.lang.Nullable;import org.springframework.util.Assert;import org.springframework.util.StringUtils;
public class CompressionQueryTransformer implements QueryTransformer { private static final Logger logger = LoggerFactory.getLogger(CompressionQueryTransformer.class); private static final PromptTemplate DEFAULTPROMPTTEMPLATE = new PromptTemplate("Given the following conversation history and a follow-up query, your task is to synthesize\na concise, standalone query that incorporates the context from the history.\nEnsure the standalone query is clear, specific, and maintains the user's intent.\n\nConversation history:\n{history}\n\nFollow-up query:\n{query}\n\nStandalone query:\n"); private final ChatClient chatClient; private final PromptTemplate promptTemplate;
public CompressionQueryTransformer(ChatClient.Builder chatClientBuilder, @Nullable PromptTemplate promptTemplate) { Assert.notNull(chatClientBuilder, "chatClientBuilder cannot be null"); this.chatClient = chatClientBuilder.build(); this.promptTemplate = promptTemplate != null ? promptTemplate : DEFAULTPROMPTTEMPLATE; PromptAssert.templateHasRequiredPlaceholders(this.promptTemplate, new String[]{"history", "query"}); }
public Query transform(Query query) { Assert.notNull(query, "query cannot be null"); logger.debug("Compressing conversation history and follow-up query into a standalone query"); String compressedQueryText = this.chatClient.prompt().user((user) -> user.text(this.promptTemplate.getTemplate()).param("history", this.formatConversationHistory(query.history())).param("query", query.text())).call().content(); if (!StringUtils.hasText(compressedQueryText)) { logger.warn("Query compression result is null/empty. Returning the input query unchanged."); return query; } else { return query.mutate().text(compressedQueryText).build(); } }
private String formatConversationHistory(List<Message> history) { return history.isEmpty() ? "" : (String)history.stream().filter((message) -> message.getMessageType().equals(MessageType.USER) || message.getMessageType().equals(MessageType.ASSISTANT)).map((message) -> "%s: %s".formatted(message.getMessageType(), message.getText())).collect(Collectors.joining("\n")); }
public static Builder builder() { return new Builder(); }
public static final class Builder { private ChatClient.Builder chatClientBuilder; @Nullable private PromptTemplate promptTemplate;
private Builder() { }
public Builder chatClientBuilder(ChatClient.Builder chatClientBuilder) { this.chatClientBuilder = chatClientBuilder; return this; }
public Builder promptTemplate(PromptTemplate promptTemplate) { this.promptTemplate = promptTemplate; return this; }
public CompressionQueryTransformer build() { return new CompressionQueryTransformer(this.chatClientBuilder, this.promptTemplate); } }}RewriteQueryTransformer
重写用户查询的类
作用:通过 LLM 优化查询,以便在查询目标系统时获得更好的结果
适用场景:用户查询冗长、模糊、不包含相关信息
各字段含义
PromptTemplate promptTemplate:自定义重写模版ChatClient chatClient:用于与 LLM 进行交互,重写查询String targetSearchSystem:目标系统的名称,用于在提示模板中指定查询的目标系统,默认为“vector store”
package org.springframework.ai.rag.preretrieval.query.transformation;
import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.rag.Query;import org.springframework.ai.rag.util.PromptAssert;import org.springframework.lang.Nullable;import org.springframework.util.Assert;import org.springframework.util.StringUtils;
public class RewriteQueryTransformer implements QueryTransformer { private static final Logger logger = LoggerFactory.getLogger(RewriteQueryTransformer.class); private static final PromptTemplate DEFAULTPROMPTTEMPLATE = new PromptTemplate("Given a user query, rewrite it to provide better results when querying a {target}.\nRemove any irrelevant information, and ensure the query is concise and specific.\n\nOriginal query:\n{query}\n\nRewritten query:\n"); private static final String DEFAULTTARGET = "vector store"; private final ChatClient chatClient; private final PromptTemplate promptTemplate; private final String targetSearchSystem;
public RewriteQueryTransformer(ChatClient.Builder chatClientBuilder, @Nullable PromptTemplate promptTemplate, @Nullable String targetSearchSystem) { Assert.notNull(chatClientBuilder, "chatClientBuilder cannot be null"); this.chatClient = chatClientBuilder.build(); this.promptTemplate = promptTemplate != null ? promptTemplate : DEFAULTPROMPTTEMPLATE; this.targetSearchSystem = targetSearchSystem != null ? targetSearchSystem : "vector store"; PromptAssert.templateHasRequiredPlaceholders(this.promptTemplate, new String[]{"target", "query"}); }
public Query transform(Query query) { Assert.notNull(query, "query cannot be null"); logger.debug("Rewriting query to optimize for querying a {}.", this.targetSearchSystem); String rewrittenQueryText = this.chatClient.prompt().user((user) -> user.text(this.promptTemplate.getTemplate()).param("target", this.targetSearchSystem).param("query", query.text())).call().content(); if (!StringUtils.hasText(rewrittenQueryText)) { logger.warn("Query rewrite result is null/empty. Returning the input query unchanged."); return query; } else { return query.mutate().text(rewrittenQueryText).build(); } }
public static Builder builder() { return new Builder(); }
public static final class Builder { private ChatClient.Builder chatClientBuilder; @Nullable private PromptTemplate promptTemplate; @Nullable private String targetSearchSystem;
private Builder() { }
public Builder chatClientBuilder(ChatClient.Builder chatClientBuilder) { this.chatClientBuilder = chatClientBuilder; return this; }
public Builder promptTemplate(PromptTemplate promptTemplate) { this.promptTemplate = promptTemplate; return this; }
public Builder targetSearchSystem(String targetSearchSystem) { this.targetSearchSystem = targetSearchSystem; return this; }
public RewriteQueryTransformer build() { return new RewriteQueryTransformer(this.chatClientBuilder, this.promptTemplate, this.targetSearchSystem); } }}TranslationQueryTransformer
将用户查询翻译为目标语言的工具类
作用:使用 LLM 将用户查询翻译为目标语言
适用场景:当嵌入模型仅支持特定语言,而用户查询使用不同语言时
各字段含义
ChatClient chatClient:与 LLM 交互,翻译为目标语言PromptTemplate promptTemplate:自定义翻译请求的提示模版String targetLanguage:目标语言
package org.springframework.ai.rag.preretrieval.query.transformation;
import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.client.ChatClient;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.rag.Query;import org.springframework.ai.rag.util.PromptAssert;import org.springframework.lang.Nullable;import org.springframework.util.Assert;import org.springframework.util.StringUtils;
public final class TranslationQueryTransformer implements QueryTransformer { private static final Logger logger = LoggerFactory.getLogger(TranslationQueryTransformer.class); private static final PromptTemplate DEFAULTPROMPTTEMPLATE = new PromptTemplate("Given a user query, translate it to {targetLanguage}.\nIf the query is already in {targetLanguage}, return it unchanged.\nIf you don't know the language of the query, return it unchanged.\nDo not add explanations nor any other text.\n\nOriginal query: {query}\n\nTranslated query:\n"); private final ChatClient chatClient; private final PromptTemplate promptTemplate; private final String targetLanguage;
public TranslationQueryTransformer(ChatClient.Builder chatClientBuilder, @Nullable PromptTemplate promptTemplate, String targetLanguage) { Assert.notNull(chatClientBuilder, "chatClientBuilder cannot be null"); Assert.hasText(targetLanguage, "targetLanguage cannot be null or empty"); this.chatClient = chatClientBuilder.build(); this.promptTemplate = promptTemplate != null ? promptTemplate : DEFAULTPROMPTTEMPLATE; this.targetLanguage = targetLanguage; PromptAssert.templateHasRequiredPlaceholders(this.promptTemplate, new String[]{"targetLanguage", "query"}); }
public Query transform(Query query) { Assert.notNull(query, "query cannot be null"); logger.debug("Translating query to target language: {}", this.targetLanguage); String translatedQueryText = this.chatClient.prompt().user((user) -> user.text(this.promptTemplate.getTemplate()).param("targetLanguage", this.targetLanguage).param("query", query.text())).call().content(); if (!StringUtils.hasText(translatedQueryText)) { logger.warn("Query translation result is null/empty. Returning the input query unchanged."); return query; } else { return query.mutate().text(translatedQueryText).build(); } }
public static Builder builder() { return new Builder(); }
public static final class Builder { private ChatClient.Builder chatClientBuilder; @Nullable private PromptTemplate promptTemplate; private String targetLanguage;
private Builder() { }
public Builder chatClientBuilder(ChatClient.Builder chatClientBuilder) { this.chatClientBuilder = chatClientBuilder; return this; }
public Builder promptTemplate(PromptTemplate promptTemplate) { this.promptTemplate = promptTemplate; return this; }
public Builder targetLanguage(String targetLanguage) { this.targetLanguage = targetLanguage; return this; }
public TranslationQueryTransformer build() { return new TranslationQueryTransformer(this.chatClientBuilder, this.promptTemplate, this.targetLanguage); } }}Retrieval
DocumentRetriever(文档检索通用接口)
package org.springframework.ai.rag.retrieval.search;
import java.util.List;import java.util.function.Function;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;
public interface DocumentRetriever extends Function<Query, List<Document>> { List<Document> retrieve(Query query);
default List<Document> apply(Query query) { return this.retrieve(query); }}VectorStoreDocumentRetriever
用于从 VectorStore 中检索与输入查询语义相似的文档
各字段含义
VectorStore vectorStore:存储和检索文档的向量存储实例Double similarityThreshold:相似度阈值,过滤相似度低于该值的文档Integer topK:返回文档的上限Supplier<Filter.Expression> filterExpression:运行时根据上下文动态生成过滤条件
package org.springframework.ai.rag.retrieval.search;
import java.util.List;import java.util.function.Supplier;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;import org.springframework.ai.vectorstore.SearchRequest;import org.springframework.ai.vectorstore.VectorStore;import org.springframework.ai.vectorstore.filter.Filter;import org.springframework.ai.vectorstore.filter.FilterExpressionTextParser;import org.springframework.lang.Nullable;import org.springframework.util.Assert;import org.springframework.util.StringUtils;
public final class VectorStoreDocumentRetriever implements DocumentRetriever { public static final String FILTEREXPRESSION = "vectorstorefilterexpression"; private final VectorStore vectorStore; private final Double similarityThreshold; private final Integer topK; private final Supplier<Filter.Expression> filterExpression;
public VectorStoreDocumentRetriever(VectorStore vectorStore, @Nullable Double similarityThreshold, @Nullable Integer topK, @Nullable Supplier<Filter.Expression> filterExpression) { Assert.notNull(vectorStore, "vectorStore cannot be null"); Assert.isTrue(similarityThreshold == null || similarityThreshold >= (double)0.0F, "similarityThreshold must be equal to or greater than 0.0"); Assert.isTrue(topK == null || topK > 0, "topK must be greater than 0"); this.vectorStore = vectorStore; this.similarityThreshold = similarityThreshold != null ? similarityThreshold : (double)0.0F; this.topK = topK != null ? topK : 4; this.filterExpression = filterExpression != null ? filterExpression : () -> null; }
public List<Document> retrieve(Query query) { Assert.notNull(query, "query cannot be null"); Filter.Expression requestFilterExpression = this.computeRequestFilterExpression(query); SearchRequest searchRequest = SearchRequest.builder().query(query.text()).filterExpression(requestFilterExpression).similarityThreshold(this.similarityThreshold).topK(this.topK).build(); return this.vectorStore.similaritySearch(searchRequest); }
private Filter.Expression computeRequestFilterExpression(Query query) { Object contextFilterExpression = query.context().get("vectorstorefilterexpression"); if (contextFilterExpression != null) { if (contextFilterExpression instanceof Filter.Expression) { return (Filter.Expression)contextFilterExpression; }
if (StringUtils.hasText(contextFilterExpression.toString())) { return (new FilterExpressionTextParser()).parse(contextFilterExpression.toString()); } }
return (Filter.Expression)this.filterExpression.get(); }
public static Builder builder() { return new Builder(); }
public static final class Builder { private VectorStore vectorStore; private Double similarityThreshold; private Integer topK; private Supplier<Filter.Expression> filterExpression;
private Builder() { }
public Builder vectorStore(VectorStore vectorStore) { this.vectorStore = vectorStore; return this; }
public Builder similarityThreshold(Double similarityThreshold) { this.similarityThreshold = similarityThreshold; return this; }
public Builder topK(Integer topK) { this.topK = topK; return this; }
public Builder filterExpression(Filter.Expression filterExpression) { this.filterExpression = () -> filterExpression; return this; }
public Builder filterExpression(Supplier<Filter.Expression> filterExpression) { this.filterExpression = filterExpression; return this; }
public VectorStoreDocumentRetriever build() { return new VectorStoreDocumentRetriever(this.vectorStore, this.similarityThreshold, this.topK, this.filterExpression); } }}DocumentJoiner(文档统一接口类)
将基于多个查询和多个数据源检索的文档合并为一个单一的文档集合
作用:文档合并(将不同数据源检索的文档合并为一个);去重处理(合并过程中,处理重复文档);排名策略(支持对合并后的文档进行排名处理)
适用场景:从多个查询或多个数据源检索文档,并将结果合并为一个统一集合的场景
package org.springframework.ai.rag.retrieval.join;
import java.util.List;import java.util.Map;import java.util.function.Function;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;
public interface DocumentJoiner extends Function<Map<Query, List<List<Document>>>, List<Document>> { List<Document> join(Map<Query, List<List<Document>>> documentsForQuery);
default List<Document> apply(Map<Query, List<List<Document>>> documentsForQuery) { return this.join(documentsForQuery); }}ConcatenationDocumentJoiner
合并基于多个查询和多个数据源检索到的文档
package org.springframework.ai.rag.retrieval.join;
import java.util.ArrayList;import java.util.Collection;import java.util.Comparator;import java.util.List;import java.util.Map;import java.util.function.Function;import java.util.stream.Collectors;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;import org.springframework.util.Assert;
public class ConcatenationDocumentJoiner implements DocumentJoiner { private static final Logger logger = LoggerFactory.getLogger(ConcatenationDocumentJoiner.class);
public List<Document> join(Map<Query, List<List<Document>>> documentsForQuery) { Assert.notNull(documentsForQuery, "documentsForQuery cannot be null"); Assert.noNullElements(documentsForQuery.keySet(), "documentsForQuery cannot contain null keys"); Assert.noNullElements(documentsForQuery.values(), "documentsForQuery cannot contain null values"); logger.debug("Joining documents by concatenation"); return new ArrayList(((Map)documentsForQuery.values().stream().flatMap(Collection::stream).flatMap(Collection::stream).collect(Collectors.toMap(Document::getId, Function.identity(), (existing, duplicate) -> existing))).values().stream().sorted(Comparator.comparingDouble((doc) -> doc.getScore() != null ? doc.getScore() : (double)0.0F).reversed()).toList()); }}Post-Retrieval
DocumentPostProcessor
检索后,对文档进行逻辑出现,如压缩、排名、选择部分等,通过实现该接口
package org.springframework.ai.rag.postretrieval.document;
import java.util.List;import java.util.function.BiFunction;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;
public interface DocumentPostProcessor extends BiFunction<Query, List<Document>, List<Document>> { List<Document> process(Query query, List<Document> documents);
default List<Document> apply(Query query, List<Document> documents) { return this.process(query, documents); }}Generation
QueryAugmenter(查询增强接口类)
通过将用户查询与额外的上下文数据结合,从而为 LLM 提供更丰富的背景信息
package org.springframework.ai.rag.generation.augmentation;
import java.util.List;import java.util.function.BiFunction;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;
public interface QueryAugmenter extends BiFunction<Query, List<Document>, Query> { Query augment(Query query, List<Document> documents);
default Query apply(Query query, List<Document> documents) { return this.augment(query, documents); }}ContextualQueryAugmenter
增强用户查询的类,通过将用户查询与提供的文档内容结合,生成一个增强后的查询,为后续的 RAG 流程提供更丰富的背景信息
各字段的含义
PromptTemplate promptTemplate:用户自定义提示模版,用于生成增强查询PromptTemplate emptyContextPromptTemplate:用户自定义为空时的上下文提示模版boolean allowEmptyContext:是否允许空上下文Function<List<Document>, String> documentFormatter:用户自定义的文档格式化函数
package org.springframework.ai.rag.generation.augmentation;
import java.util.List;import java.util.Map;import java.util.function.Function;import java.util.stream.Collectors;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.document.Document;import org.springframework.ai.rag.Query;import org.springframework.ai.rag.util.PromptAssert;import org.springframework.lang.Nullable;import org.springframework.util.Assert;
public final class ContextualQueryAugmenter implements QueryAugmenter { private static final Logger logger = LoggerFactory.getLogger(ContextualQueryAugmenter.class); private static final PromptTemplate DEFAULTPROMPTTEMPLATE = new PromptTemplate("Context information is below.\n\n---------------------\n{context}\n---------------------\n\nGiven the context information and no prior knowledge, answer the query.\n\nFollow these rules:\n\n1. If the answer is not in the context, just say that you don't know.\n2. Avoid statements like \"Based on the context...\" or \"The provided information...\".\n\nQuery: {query}\n\nAnswer:\n"); private static final PromptTemplate DEFAULTEMPTYCONTEXTPROMPTTEMPLATE = new PromptTemplate("The user query is outside your knowledge base.\nPolitely inform the user that you can't answer it.\n"); private static final boolean DEFAULTALLOWEMPTYCONTEXT = false; private static final Function<List<Document>, String> DEFAULTDOCUMENTFORMATTER = (documents) -> (String)documents.stream().map(Document::getText).collect(Collectors.joining(System.lineSeparator())); private final PromptTemplate promptTemplate; private final PromptTemplate emptyContextPromptTemplate; private final boolean allowEmptyContext; private final Function<List<Document>, String> documentFormatter;
public ContextualQueryAugmenter(@Nullable PromptTemplate promptTemplate, @Nullable PromptTemplate emptyContextPromptTemplate, @Nullable Boolean allowEmptyContext, @Nullable Function<List<Document>, String> documentFormatter) { this.promptTemplate = promptTemplate != null ? promptTemplate : DEFAULTPROMPTTEMPLATE; this.emptyContextPromptTemplate = emptyContextPromptTemplate != null ? emptyContextPromptTemplate : DEFAULTEMPTYCONTEXTPROMPTTEMPLATE; this.allowEmptyContext = allowEmptyContext != null ? allowEmptyContext : false; this.documentFormatter = documentFormatter != null ? documentFormatter : DEFAULTDOCUMENTFORMATTER; PromptAssert.templateHasRequiredPlaceholders(this.promptTemplate, new String[]{"query", "context"}); }
public Query augment(Query query, List<Document> documents) { Assert.notNull(query, "query cannot be null"); Assert.notNull(documents, "documents cannot be null"); logger.debug("Augmenting query with contextual data"); if (documents.isEmpty()) { return this.augmentQueryWhenEmptyContext(query); } else { String documentContext = (String)this.documentFormatter.apply(documents); Map<String, Object> promptParameters = Map.of("query", query.text(), "context", documentContext); return new Query(this.promptTemplate.render(promptParameters)); } }
private Query augmentQueryWhenEmptyContext(Query query) { if (this.allowEmptyContext) { logger.debug("Empty context is allowed. Returning the original query."); return query; } else { logger.debug("Empty context is not allowed. Returning a specific query for empty context."); return new Query(this.emptyContextPromptTemplate.render()); } }
public static Builder builder() { return new Builder(); }
public static class Builder { private PromptTemplate promptTemplate; private PromptTemplate emptyContextPromptTemplate; private Boolean allowEmptyContext; private Function<List<Document>, String> documentFormatter;
public Builder promptTemplate(PromptTemplate promptTemplate) { this.promptTemplate = promptTemplate; return this; }
public Builder emptyContextPromptTemplate(PromptTemplate emptyContextPromptTemplate) { this.emptyContextPromptTemplate = emptyContextPromptTemplate; return this; }
public Builder allowEmptyContext(Boolean allowEmptyContext) { this.allowEmptyContext = allowEmptyContext; return this; }
public Builder documentFormatter(Function<List<Document>, String> documentFormatter) { this.documentFormatter = documentFormatter; return this; }
public ContextualQueryAugmenter build() { return new ContextualQueryAugmenter(this.promptTemplate, this.emptyContextPromptTemplate, this.allowEmptyContext, this.documentFormatter); } }}ETL Pipeline 源码解析
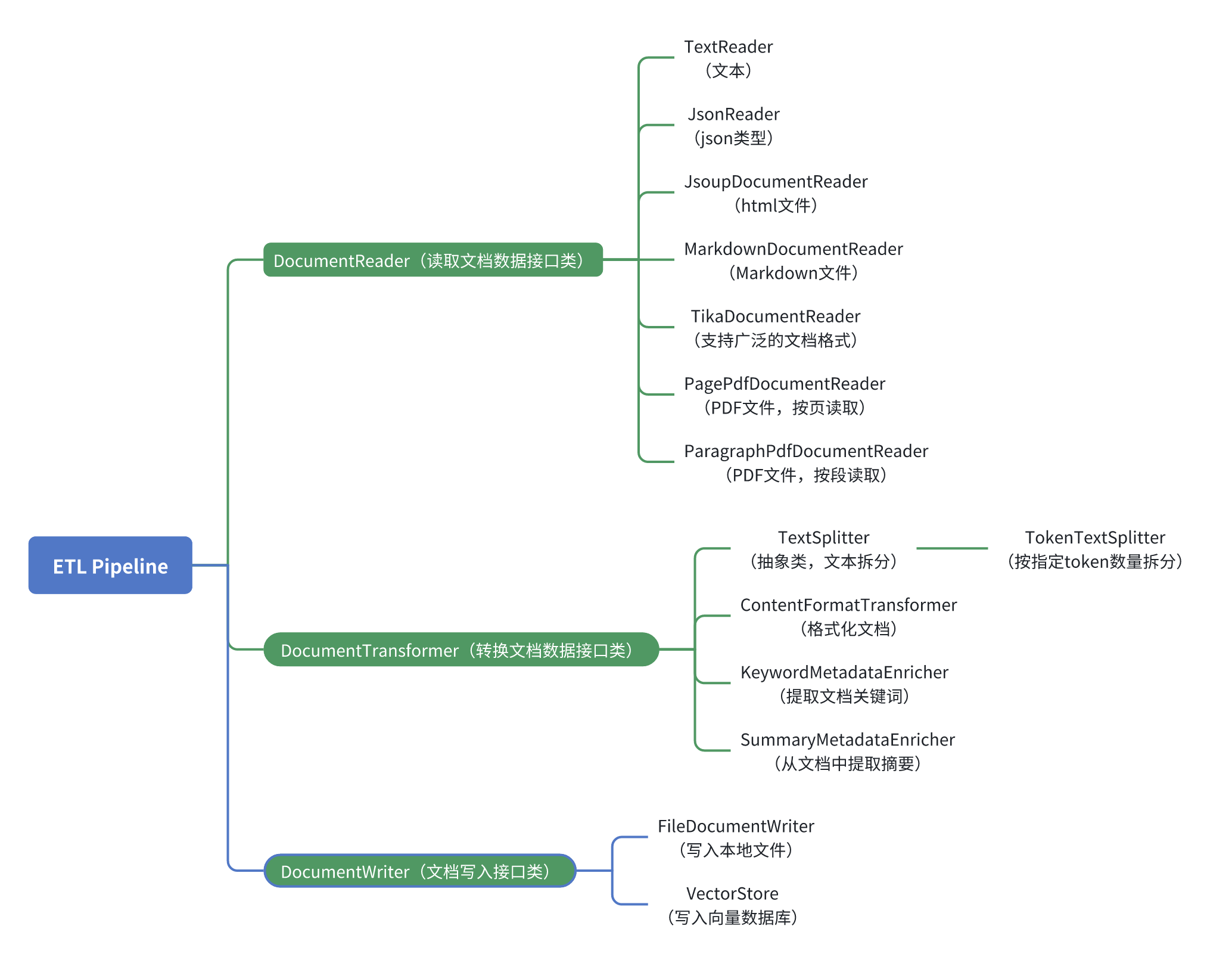
DocumentReader(读取文档数据接口类)
package org.springframework.ai.document;
import java.util.List;import java.util.function.Supplier;
public interface DocumentReader extends Supplier<List<Document>> { default List<Document> read() { return (List)this.get(); }}TextReader
用于从资源中读取文本内容并将其转换为 Document 对象
Resource resource:读取的资源Map<String, Object> customMetadata:存储与 Document 对象相关的元数据Charset charset:指定读取文本时使用的字符集,默认为 UTF8
方法说明
| 方法名称 | 描述 |
| TextReader | 通过资源URL、资源对象构造读取器 |
| setCharset | 设置读取文本时的字符集,默认为UTF8 |
| getCharset | 获取当前使用的字符集 |
| getCustomMetadata | 获取自定义元数据 |
| get | 读取文本,返回Document列表 |
| getResourceIdentifier | 获取资源的唯一标识(如文件名、URI、URL或描述信息) |
package org.springframework.ai.reader;
import java.io.IOException;import java.net.URI;import java.net.URL;import java.nio.charset.Charset;import java.nio.charset.StandardCharsets;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.Objects;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentReader;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.util.StreamUtils;
public class TextReader implements DocumentReader { public static final String CHARSETMETADATA = "charset"; public static final String SOURCEMETADATA = "source"; private final Resource resource; private final Map<String, Object> customMetadata; private Charset charset;
public TextReader(String resourceUrl) { this((new DefaultResourceLoader()).getResource(resourceUrl)); }
public TextReader(Resource resource) { this.customMetadata = new HashMap(); this.charset = StandardCharsets.UTF8; Objects.requireNonNull(resource, "The Spring Resource must not be null"); this.resource = resource; }
public Charset getCharset() { return this.charset; }
public void setCharset(Charset charset) { Objects.requireNonNull(charset, "The charset must not be null"); this.charset = charset; }
public Map<String, Object> getCustomMetadata() { return this.customMetadata; }
public List<Document> get() { try { String document = StreamUtils.copyToString(this.resource.getInputStream(), this.charset); this.customMetadata.put("charset", this.charset.name()); this.customMetadata.put("source", this.resource.getFilename()); this.customMetadata.put("source", this.getResourceIdentifier(this.resource)); return List.of(new Document(document, this.customMetadata)); } catch (IOException e) { throw new RuntimeException(e); } }
protected String getResourceIdentifier(Resource resource) { String filename = resource.getFilename(); if (filename != null && !filename.isEmpty()) { return filename; } else { try { URI uri = resource.getURI(); if (uri != null) { return uri.toString(); } } catch (IOException var5) { }
try { URL url = resource.getURL(); if (url != null) { return url.toString(); } } catch (IOException var4) { }
return resource.getDescription(); } }}JsonReader
用于从 JSON 资源中读取数据并将其转换为 Document 对象
Resource resource:表示要读取的 JSON 资源JsonMetadataGenerator jsonMetadataGenerator:用于生成与 JSON 数据相关的元数据ObjectMapper objectMapper:用于解析 JSON 数据List<String> jsonKeysToUse:用于从 JSON 中提取哪些字段作为文档内容,若未指定则使用整个 JSON 对象
方法说明
| 方法名称 | 描述 |
| JsonReader | 通过资源对象、提取的字段名构造读取器 |
| get | 读取json文件,返回Document列表 |
package org.springframework.ai.reader;
import com.fasterxml.jackson.core.type.TypeReference;import com.fasterxml.jackson.databind.JsonNode;import com.fasterxml.jackson.databind.ObjectMapper;import java.io.IOException;import java.util.Collections;import java.util.List;import java.util.Map;import java.util.Objects;import java.util.stream.Stream;import java.util.stream.StreamSupport;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentReader;import org.springframework.core.io.Resource;
public class JsonReader implements DocumentReader { private final Resource resource; private final JsonMetadataGenerator jsonMetadataGenerator; private final ObjectMapper objectMapper; private final List<String> jsonKeysToUse;
public JsonReader(Resource resource) { this(resource); }
public JsonReader(Resource resource, String... jsonKeysToUse) { this(resource, new EmptyJsonMetadataGenerator(), jsonKeysToUse); }
public JsonReader(Resource resource, JsonMetadataGenerator jsonMetadataGenerator, String... jsonKeysToUse) { this.objectMapper = new ObjectMapper(); Objects.requireNonNull(jsonKeysToUse, "keys must not be null"); Objects.requireNonNull(jsonMetadataGenerator, "jsonMetadataGenerator must not be null"); Objects.requireNonNull(resource, "The Spring Resource must not be null"); this.resource = resource; this.jsonMetadataGenerator = jsonMetadataGenerator; this.jsonKeysToUse = List.of(jsonKeysToUse); }
public List<Document> get() { try { JsonNode rootNode = this.objectMapper.readTree(this.resource.getInputStream()); return rootNode.isArray() ? StreamSupport.stream(rootNode.spliterator(), true).map((jsonNode) -> this.parseJsonNode(jsonNode, this.objectMapper)).toList() : Collections.singletonList(this.parseJsonNode(rootNode, this.objectMapper)); } catch (IOException e) { throw new RuntimeException(e); } }
private Document parseJsonNode(JsonNode jsonNode, ObjectMapper objectMapper) { Map<String, Object> item = (Map)objectMapper.convertValue(jsonNode, new TypeReference<Map<String, Object>>() { }); StringBuilder sb = new StringBuilder(); Stream var10000 = this.jsonKeysToUse.stream(); Objects.requireNonNull(item); var10000.filter(item::containsKey).forEach((key) -> sb.append(key).append(": ").append(item.get(key)).append(System.lineSeparator())); Map<String, Object> metadata = this.jsonMetadataGenerator.generate(item); String content = sb.isEmpty() ? item.toString() : sb.toString(); return new Document(content, metadata); }
protected List<Document> get(JsonNode rootNode) { return rootNode.isArray() ? StreamSupport.stream(rootNode.spliterator(), true).map((jsonNode) -> this.parseJsonNode(jsonNode, this.objectMapper)).toList() : Collections.singletonList(this.parseJsonNode(rootNode, this.objectMapper)); }
public List<Document> get(String pointer) { try { JsonNode rootNode = this.objectMapper.readTree(this.resource.getInputStream()); JsonNode targetNode = rootNode.at(pointer); if (targetNode.isMissingNode()) { throw new IllegalArgumentException("Invalid JSON Pointer: " + pointer); } else { return this.get(targetNode); } } catch (IOException e) { throw new RuntimeException("Error reading JSON resource", e); } }}JsoupDocumentReader
用于从 HTML 文档中提取文本内容,并将其转换为 Document 对象
各字段含义:
Resource htmlResource:要读取的 HTML 资源JsoupDocumentReaderConfig config:配置 HTML 文档读取行为,包括字符集、选择器、是否提取所有元素,是否按元素分组等
方法说明
| 方法名称 | 描述 |
| JsoupDocumentReader | 通过资源URL、资源对象、解析HTML配置等构造读取器 |
| get | 读取html文件,返回Document列表 |
package org.springframework.ai.reader.jsoup;
import java.io.IOException;import java.io.InputStream;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import java.util.stream.Collectors;import org.jsoup.Jsoup;import org.jsoup.nodes.Element;import org.jsoup.select.Elements;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentReader;import org.springframework.ai.reader.jsoup.config.JsoupDocumentReaderConfig;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;
public class JsoupDocumentReader implements DocumentReader { private final Resource htmlResource; private final JsoupDocumentReaderConfig config;
public JsoupDocumentReader(String htmlResource) { this((new DefaultResourceLoader()).getResource(htmlResource)); }
public JsoupDocumentReader(Resource htmlResource) { this(htmlResource, JsoupDocumentReaderConfig.defaultConfig()); }
public JsoupDocumentReader(String htmlResource, JsoupDocumentReaderConfig config) { this((new DefaultResourceLoader()).getResource(htmlResource), config); }
public JsoupDocumentReader(Resource htmlResource, JsoupDocumentReaderConfig config) { this.htmlResource = htmlResource; this.config = config; }
public List<Document> get() { try (InputStream inputStream = this.htmlResource.getInputStream()) { org.jsoup.nodes.Document doc = Jsoup.parse(inputStream, this.config.charset, ""); List<Document> documents = new ArrayList(); if (this.config.allElements) { String allText = doc.body().text(); Document document = new Document(allText); this.addMetadata(doc, document); documents.add(document); } else if (this.config.groupByElement) { for(Element element : doc.select(this.config.selector)) { String elementText = element.text(); Document document = new Document(elementText); this.addMetadata(doc, document); documents.add(document); } } else { Elements elements = doc.select(this.config.selector); String text = (String)elements.stream().map(Element::text).collect(Collectors.joining(this.config.separator)); Document document = new Document(text); this.addMetadata(doc, document); documents.add(document); }
return documents; } catch (IOException e) { throw new RuntimeException("Failed to read HTML resource: " + String.valueOf(this.htmlResource), e); } }
private void addMetadata(org.jsoup.nodes.Document jsoupDoc, Document springDoc) { Map<String, Object> metadata = new HashMap(); metadata.put("title", jsoupDoc.title());
for(String metaTag : this.config.metadataTags) { String value = jsoupDoc.select("meta[name=" + metaTag + "]").attr("content"); if (!value.isEmpty()) { metadata.put(metaTag, value); } }
if (this.config.includeLinkUrls) { Elements links = jsoupDoc.select("a[href]"); List<String> linkUrls = links.stream().map((link) -> link.attr("abs:href")).toList(); metadata.put("linkUrls", linkUrls); }
metadata.putAll(this.config.additionalMetadata); springDoc.getMetadata().putAll(metadata); }}JsoupDocumentReaderConfig
配置 JsoupDocumentReader 行为的工具类
String charset:读取 HTML 文档时使用的字符编码,默认值为 “UTF-8”String selector:用于提取 HTML 元素的 CSS 选择器,默认值为 “body”String separator:在提取多个元素的文本内容时使用的分隔符,默认值为 “\n”boolean allElements:是否提取 HTML 文档中所有元素的文本内容,并生成一个 Document 对象,默认值为 falseboolean groupByElement:是否按元素分组提取文本内容,并为每个元素生成一个 Document 对象,默认值为 falseboolean includeLinkUrls:是否将 HTML 文档中的链接 URL 包含在元数据中,默认值为 falseList<String> metadataTags:指定从 HTML 文档的 标签中提取哪些元数据,默认包含 “description” 和 “keywords”Map<String, Object> additionalMetadata:用于添加额外的元数据到生成的 Document 对象中
package org.springframework.ai.reader.jsoup.config;
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import org.springframework.util.Assert;
public final class JsoupDocumentReaderConfig { public final String charset; public final String selector; public final String separator; public final boolean allElements; public final boolean groupByElement; public final boolean includeLinkUrls; public final List<String> metadataTags; public final Map<String, Object> additionalMetadata;
private JsoupDocumentReaderConfig(Builder builder) { this.charset = builder.charset; this.selector = builder.selector; this.separator = builder.separator; this.allElements = builder.allElements; this.includeLinkUrls = builder.includeLinkUrls; this.metadataTags = builder.metadataTags; this.groupByElement = builder.groupByElement; this.additionalMetadata = builder.additionalMetadata; }
public static Builder builder() { return new Builder(); }
public static JsoupDocumentReaderConfig defaultConfig() { return builder().build(); }
public static final class Builder { private String charset = "UTF-8"; private String selector = "body"; private String separator = "\n"; private boolean allElements = false; private boolean includeLinkUrls = false; private List<String> metadataTags = new ArrayList(List.of("description", "keywords")); private boolean groupByElement = false; private Map<String, Object> additionalMetadata = new HashMap();
private Builder() { }
public Builder charset(String charset) { this.charset = charset; return this; }
public Builder selector(String selector) { this.selector = selector; return this; }
public Builder separator(String separator) { this.separator = separator; return this; }
public Builder allElements(boolean allElements) { this.allElements = allElements; return this; }
public Builder groupByElement(boolean groupByElement) { this.groupByElement = groupByElement; return this; }
public Builder includeLinkUrls(boolean includeLinkUrls) { this.includeLinkUrls = includeLinkUrls; return this; }
public Builder metadataTag(String metadataTag) { this.metadataTags.add(metadataTag); return this; }
public Builder metadataTags(List<String> metadataTags) { this.metadataTags = new ArrayList(metadataTags); return this; }
public Builder additionalMetadata(String key, Object value) { Assert.notNull(key, "key must not be null"); Assert.notNull(value, "value must not be null"); this.additionalMetadata.put(key, value); return this; }
public Builder additionalMetadata(Map<String, Object> additionalMetadata) { Assert.notNull(additionalMetadata, "additionalMetadata must not be null"); this.additionalMetadata = additionalMetadata; return this; }
public JsoupDocumentReaderConfig build() { return new JsoupDocumentReaderConfig(this); } }}MarkdownDocumentReader
用于从 Markdown 文件中读取内容并将其转换为 Document 对象。基于 CommonMark 库解析 Markdown 文档,支持将标题、段落、代码块等内容分组为 Document 对象,并生成相关元数据
Resource markdownResource:要读取的 Markdown 资源MarkdownDocumentReaderConfig config:配置 Markdown 文档读取行为,包括是否将水平分割线视为文档分隔符、是否包含代码块、是否包含引用块等Parser parser:解析 Markdown 文档的 CommonMark 解析器,用于将 Markdown 文本解析为节点树
DocumentVisitor 作为内部静态类,继承自 CommonMark 的 AbstractVisitor,用于遍历和解析 Markdown 的语法树节点,将其内容按配置分组、提取为结构化的 Document 对象
- 历 Markdown 解析后的节点树,根据配置(如是否按水平线分组、是否包含代码块/引用等)将内容分组
- 识别标题、段落、代码块、引用等不同类型节点,提取文本和元数据,构建 Document
- 支持为不同类型内容(如标题、代码块、引用)添加分类、标题、语言等元数据,便于后续 AI 处理。
| 方法名称 | 描述 |
| MarkdownDocumentReader | 通过资源URL、资源对象、解析markdown配置等构造读取器 |
| get | 读取markdown文件,返回Document列表 |
package org.springframework.ai.reader.markdown;
import java.io.IOException;import java.io.InputStream;import java.io.InputStreamReader;import java.util.ArrayList;import java.util.List;import java.util.Map;import java.util.Objects;import org.commonmark.node.AbstractVisitor;import org.commonmark.node.BlockQuote;import org.commonmark.node.Code;import org.commonmark.node.FencedCodeBlock;import org.commonmark.node.HardLineBreak;import org.commonmark.node.Heading;import org.commonmark.node.ListItem;import org.commonmark.node.Node;import org.commonmark.node.SoftLineBreak;import org.commonmark.node.Text;import org.commonmark.node.ThematicBreak;import org.commonmark.parser.Parser;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentReader;import org.springframework.ai.reader.markdown.config.MarkdownDocumentReaderConfig;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;
public class MarkdownDocumentReader implements DocumentReader { private final Resource markdownResource; private final MarkdownDocumentReaderConfig config; private final Parser parser;
public MarkdownDocumentReader(String markdownResource) { this((new DefaultResourceLoader()).getResource(markdownResource), MarkdownDocumentReaderConfig.defaultConfig()); }
public MarkdownDocumentReader(String markdownResource, MarkdownDocumentReaderConfig config) { this((new DefaultResourceLoader()).getResource(markdownResource), config); }
public MarkdownDocumentReader(Resource markdownResource, MarkdownDocumentReaderConfig config) { this.markdownResource = markdownResource; this.config = config; this.parser = Parser.builder().build(); }
public List<Document> get() { try (InputStream input = this.markdownResource.getInputStream()) { Node node = this.parser.parseReader(new InputStreamReader(input)); DocumentVisitor documentVisitor = new DocumentVisitor(this.config); node.accept(documentVisitor); return documentVisitor.getDocuments(); } catch (IOException e) { throw new RuntimeException(e); } }
static class DocumentVisitor extends AbstractVisitor { private final List<Document> documents = new ArrayList(); private final List<String> currentParagraphs = new ArrayList(); private final MarkdownDocumentReaderConfig config; private Document.Builder currentDocumentBuilder;
DocumentVisitor(MarkdownDocumentReaderConfig config) { this.config = config; }
public void visit(org.commonmark.node.Document document) { this.currentDocumentBuilder = Document.builder(); super.visit(document); }
public void visit(Heading heading) { this.buildAndFlush(); super.visit(heading); }
public void visit(ThematicBreak thematicBreak) { if (this.config.horizontalRuleCreateDocument) { this.buildAndFlush(); }
super.visit(thematicBreak); }
public void visit(SoftLineBreak softLineBreak) { this.translateLineBreakToSpace(); super.visit(softLineBreak); }
public void visit(HardLineBreak hardLineBreak) { this.translateLineBreakToSpace(); super.visit(hardLineBreak); }
public void visit(ListItem listItem) { this.translateLineBreakToSpace(); super.visit(listItem); }
public void visit(BlockQuote blockQuote) { if (!this.config.includeBlockquote) { this.buildAndFlush(); }
this.translateLineBreakToSpace(); this.currentDocumentBuilder.metadata("category", "blockquote"); super.visit(blockQuote); }
public void visit(Code code) { this.currentParagraphs.add(code.getLiteral()); this.currentDocumentBuilder.metadata("category", "codeinline"); super.visit(code); }
public void visit(FencedCodeBlock fencedCodeBlock) { if (!this.config.includeCodeBlock) { this.buildAndFlush(); }
this.translateLineBreakToSpace(); this.currentParagraphs.add(fencedCodeBlock.getLiteral()); this.currentDocumentBuilder.metadata("category", "codeblock"); this.currentDocumentBuilder.metadata("lang", fencedCodeBlock.getInfo()); this.buildAndFlush(); super.visit(fencedCodeBlock); }
public void visit(Text text) { Node var3 = text.getParent(); if (var3 instanceof Heading heading) { this.currentDocumentBuilder.metadata("category", "header%d".formatted(heading.getLevel())).metadata("title", text.getLiteral()); } else { this.currentParagraphs.add(text.getLiteral()); }
super.visit(text); }
public List<Document> getDocuments() { this.buildAndFlush(); return this.documents; }
private void buildAndFlush() { if (!this.currentParagraphs.isEmpty()) { String content = String.join("", this.currentParagraphs); Document.Builder builder = this.currentDocumentBuilder.text(content); Map var10000 = this.config.additionalMetadata; Objects.requireNonNull(builder); var10000.forEach(builder::metadata); Document document = builder.build(); this.documents.add(document); this.currentParagraphs.clear(); }
this.currentDocumentBuilder = Document.builder(); }
private void translateLineBreakToSpace() { if (!this.currentParagraphs.isEmpty()) { this.currentParagraphs.add(" "); }
} }}MarkdownDocumentReaderConfig
配置 MarkdownDocumentReader 的行为
boolean horizontalRuleCreateDocument:是否将水平分割线分隔的文本创建为新的 Documentboolean includeCodeBlock:是否将代码块包含在段落文档中,还是单独创建新文档boolean includeBlockquote:是否将引用块包含在段落文档中,还是单独创建新文档Map<String, Object> additionalMetadata:添加额外元数据
package org.springframework.ai.reader.markdown.config;
import java.util.HashMap;import java.util.Map;import org.springframework.util.Assert;
public class MarkdownDocumentReaderConfig { public final boolean horizontalRuleCreateDocument; public final boolean includeCodeBlock; public final boolean includeBlockquote; public final Map<String, Object> additionalMetadata;
public MarkdownDocumentReaderConfig(Builder builder) { this.horizontalRuleCreateDocument = builder.horizontalRuleCreateDocument; this.includeCodeBlock = builder.includeCodeBlock; this.includeBlockquote = builder.includeBlockquote; this.additionalMetadata = builder.additionalMetadata; }
public static MarkdownDocumentReaderConfig defaultConfig() { return builder().build(); }
public static Builder builder() { return new Builder(); }
public static final class Builder { private boolean horizontalRuleCreateDocument = false; private boolean includeCodeBlock = false; private boolean includeBlockquote = false; private Map<String, Object> additionalMetadata = new HashMap();
private Builder() { }
public Builder withHorizontalRuleCreateDocument(boolean horizontalRuleCreateDocument) { this.horizontalRuleCreateDocument = horizontalRuleCreateDocument; return this; }
public Builder withIncludeCodeBlock(boolean includeCodeBlock) { this.includeCodeBlock = includeCodeBlock; return this; }
public Builder withIncludeBlockquote(boolean includeBlockquote) { this.includeBlockquote = includeBlockquote; return this; }
public Builder withAdditionalMetadata(String key, Object value) { Assert.notNull(key, "key must not be null"); Assert.notNull(value, "value must not be null"); this.additionalMetadata.put(key, value); return this; }
public Builder withAdditionalMetadata(Map<String, Object> additionalMetadata) { Assert.notNull(additionalMetadata, "additionalMetadata must not be null"); this.additionalMetadata = additionalMetadata; return this; }
public MarkdownDocumentReaderConfig build() { return new MarkdownDocumentReaderConfig(this); } }}PagePdfDocumentReader
用于将 PDF 文件按页分组解析为多个 Document,每个 Document 可包含一页或多页内容,支持自定义分组和页面裁剪
PDDocument document:要读取的 PDF 文档对象- String resourceFileName:存储 PDF 文件的名字
PdfDocumentReaderConfig config:配置 PDF 文档读取行为,包括每份文档包含的页数、页边距
| 方法名称 | 描述 |
| PagePdfDocumentReader | 通过资源URL、资源对象、解析PDF配置等构造读取器 |
| get | 读取PDF,返回Document列表 |
| toDocument | 将指定页内容和元数据封装为 Document |
package org.springframework.ai.reader.pdf;
import java.awt.Rectangle;import java.io.IOException;import java.util.ArrayList;import java.util.List;import java.util.stream.Collectors;import org.apache.pdfbox.io.RandomAccessReadBuffer;import org.apache.pdfbox.pdfparser.PDFParser;import org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.pdmodel.PDPage;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentReader;import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;import org.springframework.ai.reader.pdf.layout.PDFLayoutTextStripperByArea;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.util.CollectionUtils;import org.springframework.util.StringUtils;
public class PagePdfDocumentReader implements DocumentReader { public static final String METADATASTARTPAGENUMBER = "pagenumber"; public static final String METADATAENDPAGENUMBER = "endpagenumber"; public static final String METADATAFILENAME = "filename"; private static final String PDFPAGEREGION = "pdfPageRegion"; protected final PDDocument document; private final Logger logger; protected String resourceFileName; private PdfDocumentReaderConfig config;
public PagePdfDocumentReader(String resourceUrl) { this((new DefaultResourceLoader()).getResource(resourceUrl)); }
public PagePdfDocumentReader(Resource pdfResource) { this(pdfResource, PdfDocumentReaderConfig.defaultConfig()); }
public PagePdfDocumentReader(String resourceUrl, PdfDocumentReaderConfig config) { this((new DefaultResourceLoader()).getResource(resourceUrl), config); }
public PagePdfDocumentReader(Resource pdfResource, PdfDocumentReaderConfig config) { this.logger = LoggerFactory.getLogger(this.getClass());
try { PDFParser pdfParser = new PDFParser(new RandomAccessReadBuffer(pdfResource.getInputStream())); this.document = pdfParser.parse(); this.resourceFileName = pdfResource.getFilename(); this.config = config; } catch (Exception e) { throw new RuntimeException(e); } }
public List<Document> get() { List<Document> readDocuments = new ArrayList();
try { PDFLayoutTextStripperByArea pdfTextStripper = new PDFLayoutTextStripperByArea(); int pageNumber = 0; int pagesPerDocument = 0; int startPageNumber = pageNumber; List<String> pageTextGroupList = new ArrayList(); int totalPages = this.document.getDocumentCatalog().getPages().getCount(); int logFrequency = totalPages > 10 ? totalPages / 10 : 1; int counter = 0; PDPage lastPage = (PDPage)this.document.getDocumentCatalog().getPages().iterator().next();
for(PDPage page : this.document.getDocumentCatalog().getPages()) { lastPage = page; if (counter % logFrequency == 0 && counter / logFrequency < 10) { this.logger.info("Processing PDF page: {}", counter + 1); }
++counter; ++pagesPerDocument; if (this.config.pagesPerDocument != 0 && pagesPerDocument >= this.config.pagesPerDocument) { pagesPerDocument = 0; String aggregatedPageTextGroup = (String)pageTextGroupList.stream().collect(Collectors.joining()); if (StringUtils.hasText(aggregatedPageTextGroup)) { readDocuments.add(this.toDocument(page, aggregatedPageTextGroup, startPageNumber, pageNumber)); }
pageTextGroupList.clear(); startPageNumber = pageNumber + 1; }
int x0 = (int)page.getMediaBox().getLowerLeftX(); int xW = (int)page.getMediaBox().getWidth(); int y0 = (int)page.getMediaBox().getLowerLeftY() + this.config.pageTopMargin; int yW = (int)page.getMediaBox().getHeight() - (this.config.pageTopMargin + this.config.pageBottomMargin); pdfTextStripper.addRegion("pdfPageRegion", new Rectangle(x0, y0, xW, yW)); pdfTextStripper.extractRegions(page); String pageText = pdfTextStripper.getTextForRegion("pdfPageRegion"); if (StringUtils.hasText(pageText)) { pageText = this.config.pageExtractedTextFormatter.format(pageText, pageNumber); pageTextGroupList.add(pageText); }
++pageNumber; pdfTextStripper.removeRegion("pdfPageRegion"); }
if (!CollectionUtils.isEmpty(pageTextGroupList)) { readDocuments.add(this.toDocument(lastPage, (String)pageTextGroupList.stream().collect(Collectors.joining()), startPageNumber, pageNumber)); }
this.logger.info("Processing {} pages", totalPages); return readDocuments; } catch (IOException e) { throw new RuntimeException(e); } }
protected Document toDocument(PDPage page, String docText, int startPageNumber, int endPageNumber) { Document doc = new Document(docText); doc.getMetadata().put("pagenumber", startPageNumber); if (startPageNumber != endPageNumber) { doc.getMetadata().put("endpagenumber", endPageNumber); }
doc.getMetadata().put("filename", this.resourceFileName); return doc; }}PdfDocumentReaderConfig
PDF 文档读取器的配置类,用于控制 PDF 解析和分组行为
int ALLPAGES:常量,值为 0,表示将所有页合并为一个 Documentboolean reversedParagraphPosition:是否反转每页内段落顺序,默认为 falseint pagesPerDocument:每个 Document 包含的页数,0 表示所有页合并,默认 1int pageTopMargin:每页顶部裁剪的像素数,默认 0int pageBottomMargin:每页底部裁剪的像素数,默认 0int pageExtractedTextFormatter:提取文本后的格式化器,可自定义每页文本的处理方式
package org.springframework.ai.reader.pdf.config;
import org.springframework.ai.reader.ExtractedTextFormatter;import org.springframework.util.Assert;
public final class PdfDocumentReaderConfig { public static final int ALLPAGES = 0; public final boolean reversedParagraphPosition; public final int pagesPerDocument; public final int pageTopMargin; public final int pageBottomMargin; public final ExtractedTextFormatter pageExtractedTextFormatter;
private PdfDocumentReaderConfig(Builder builder) { this.pagesPerDocument = builder.pagesPerDocument; this.pageBottomMargin = builder.pageBottomMargin; this.pageTopMargin = builder.pageTopMargin; this.pageExtractedTextFormatter = builder.pageExtractedTextFormatter; this.reversedParagraphPosition = builder.reversedParagraphPosition; }
public static Builder builder() { return new Builder(); }
public static PdfDocumentReaderConfig defaultConfig() { return builder().build(); }
public static final class Builder { private int pagesPerDocument = 1; private int pageTopMargin = 0; private int pageBottomMargin = 0; private ExtractedTextFormatter pageExtractedTextFormatter = ExtractedTextFormatter.defaults(); private boolean reversedParagraphPosition = false;
private Builder() { }
public Builder withPageExtractedTextFormatter(ExtractedTextFormatter pageExtractedTextFormatter) { Assert.notNull(pageExtractedTextFormatter, "PageExtractedTextFormatter must not be null."); this.pageExtractedTextFormatter = pageExtractedTextFormatter; return this; }
public Builder withPagesPerDocument(int pagesPerDocument) { Assert.isTrue(pagesPerDocument >= 0, "Page count must be a positive value."); this.pagesPerDocument = pagesPerDocument; return this; }
public Builder withPageTopMargin(int topMargin) { Assert.isTrue(topMargin >= 0, "Page margins must be a positive value."); this.pageTopMargin = topMargin; return this; }
public Builder withPageBottomMargin(int bottomMargin) { Assert.isTrue(bottomMargin >= 0, "Page margins must be a positive value."); this.pageBottomMargin = bottomMargin; return this; }
public Builder withReversedParagraphPosition(boolean reversedParagraphPosition) { this.reversedParagraphPosition = reversedParagraphPosition; return this; }
public PdfDocumentReaderConfig build() { return new PdfDocumentReaderConfig(this); } }}ParagraphPdfDocumentReader
用于将 PDF 文件按段落(基于目录/结构信息)解析为多个 Document,每个 Document 通常对应一个段落
PDDocument document:要读取的 PDF 文档对象String resourceFileName:存储 PDF 文件的名字PdfDocumentReaderConfig config:配置 PDF 文档读取行为,包括每份文档包含的页数、页边距ParagraphManager paragraphTextExtractor:负责解析 PDF 并提取段落信息
| 方法名称 | 描述 |
| ParagraphPdfDocumentReader | 通过资源URL、资源对象、解析PDF配置等构造读取器 |
| get | 读取带目录的PDF,返回Document列表 |
| toDocument | 将指定段落内容和元数据封装为 Document |
| addMetadata | 为 Document 添加元数据 |
| getTextBetweenParagraphs | 提取两个段落之间的文本内容 |
package org.springframework.ai.reader.pdf;
import java.awt.Rectangle;import java.util.ArrayList;import java.util.Iterator;import java.util.List;import org.apache.pdfbox.io.RandomAccessReadBuffer;import org.apache.pdfbox.pdfparser.PDFParser;import org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.pdmodel.PDPage;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentReader;import org.springframework.ai.reader.pdf.config.ParagraphManager;import org.springframework.ai.reader.pdf.config.PdfDocumentReaderConfig;import org.springframework.ai.reader.pdf.layout.PDFLayoutTextStripperByArea;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.util.CollectionUtils;import org.springframework.util.StringUtils;
public class ParagraphPdfDocumentReader implements DocumentReader { private static final String METADATASTARTPAGE = "pagenumber"; private static final String METADATAENDPAGE = "endpagenumber"; private static final String METADATATITLE = "title"; private static final String METADATALEVEL = "level"; private static final String METADATAFILENAME = "filename"; protected final PDDocument document; private final Logger logger; private final ParagraphManager paragraphTextExtractor; protected String resourceFileName; private PdfDocumentReaderConfig config;
public ParagraphPdfDocumentReader(String resourceUrl) { this((new DefaultResourceLoader()).getResource(resourceUrl)); }
public ParagraphPdfDocumentReader(Resource pdfResource) { this(pdfResource, PdfDocumentReaderConfig.defaultConfig()); }
public ParagraphPdfDocumentReader(String resourceUrl, PdfDocumentReaderConfig config) { this((new DefaultResourceLoader()).getResource(resourceUrl), config); }
public ParagraphPdfDocumentReader(Resource pdfResource, PdfDocumentReaderConfig config) { this.logger = LoggerFactory.getLogger(this.getClass());
try { PDFParser pdfParser = new PDFParser(new RandomAccessReadBuffer(pdfResource.getInputStream())); this.document = pdfParser.parse(); this.config = config; this.paragraphTextExtractor = new ParagraphManager(this.document); this.resourceFileName = pdfResource.getFilename(); } catch (IllegalArgumentException iae) { throw iae; } catch (Exception e) { throw new RuntimeException(e); } }
public List<Document> get() { List<ParagraphManager.Paragraph> paragraphs = this.paragraphTextExtractor.flatten(); List<Document> documents = new ArrayList(paragraphs.size()); if (!CollectionUtils.isEmpty(paragraphs)) { this.logger.info("Start processing paragraphs from PDF"); Iterator<ParagraphManager.Paragraph> itr = paragraphs.iterator(); ParagraphManager.Paragraph current = (ParagraphManager.Paragraph)itr.next(); ParagraphManager.Paragraph next; if (!itr.hasNext()) { documents.add(this.toDocument(current, current)); } else { for(; itr.hasNext(); current = next) { next = (ParagraphManager.Paragraph)itr.next(); Document document = this.toDocument(current, next); if (document != null && StringUtils.hasText(document.getText())) { documents.add(this.toDocument(current, next)); } } } }
this.logger.info("End processing paragraphs from PDF"); return documents; }
protected Document toDocument(ParagraphManager.Paragraph from, ParagraphManager.Paragraph to) { String docText = this.getTextBetweenParagraphs(from, to); if (!StringUtils.hasText(docText)) { return null; } else { Document document = new Document(docText); this.addMetadata(from, to, document); return document; } }
protected void addMetadata(ParagraphManager.Paragraph from, ParagraphManager.Paragraph to, Document document) { document.getMetadata().put("title", from.title()); document.getMetadata().put("pagenumber", from.startPageNumber()); document.getMetadata().put("endpagenumber", to.startPageNumber()); document.getMetadata().put("level", from.level()); document.getMetadata().put("filename", this.resourceFileName); }
public String getTextBetweenParagraphs(ParagraphManager.Paragraph fromParagraph, ParagraphManager.Paragraph toParagraph) { int startPage = fromParagraph.startPageNumber() - 1; int endPage = toParagraph.startPageNumber() - 1;
try { StringBuilder sb = new StringBuilder(); PDFLayoutTextStripperByArea pdfTextStripper = new PDFLayoutTextStripperByArea(); pdfTextStripper.setSortByPosition(true);
for(int pageNumber = startPage; pageNumber <= endPage; ++pageNumber) { PDPage page = this.document.getPage(pageNumber); int fromPosition = fromParagraph.position(); int toPosition = toParagraph.position(); if (this.config.reversedParagraphPosition) { fromPosition = (int)(page.getMediaBox().getHeight() - (float)fromPosition); toPosition = (int)(page.getMediaBox().getHeight() - (float)toPosition); }
int x0 = (int)page.getMediaBox().getLowerLeftX(); int xW = (int)page.getMediaBox().getWidth(); int y0 = (int)page.getMediaBox().getLowerLeftY(); int yW = (int)page.getMediaBox().getHeight(); if (pageNumber == startPage) { y0 = fromPosition; yW = (int)page.getMediaBox().getHeight() - fromPosition; }
if (pageNumber == endPage) { yW = toPosition - y0; }
if (y0 + yW == (int)page.getMediaBox().getHeight()) { yW -= this.config.pageBottomMargin; }
if (y0 == 0) { y0 += this.config.pageTopMargin; yW -= this.config.pageTopMargin; }
pdfTextStripper.addRegion("pdfPageRegion", new Rectangle(x0, y0, xW, yW)); pdfTextStripper.extractRegions(page); String text = pdfTextStripper.getTextForRegion("pdfPageRegion"); if (StringUtils.hasText(text)) { sb.append(text); }
pdfTextStripper.removeRegion("pdfPageRegion"); }
String text = sb.toString(); if (StringUtils.hasText(text)) { text = this.config.pageExtractedTextFormatter.format(text, startPage); }
return text; } catch (Exception e) { throw new RuntimeException(e); } }}ParagraphManager
类用于管理 PDF 文档的段落结构,主要通过解析 PDF 目录(TOC/书签)生成段落树,并可将其扁平化为段落列表,便于后续内容提取和分组
Paragraph rootParagraph:段落树的根节点,类型为 Paragraph,包含所有段落的层级结构PDDocument document:PDFBox 的 PDDocument,表示当前处理的 PDF 文档
| 方法名称 | 描述 |
| ParagraphManager | 传入 PDF 文档,自动解析目录生成段落树 |
| flatten | 将段落树扁平化为 Paragraph 列表,便于顺序遍历 |
| getParagraphsByLevel | 按指定层级获取段落列表,可选是否包含跨层级段落 |
| Paragraph | 静态内部类,表示段落的元数据(标题、层级、起止页码、位置、子段落等) |
| generateParagraphs | ParagraphManager 的核心递归方法,用于遍历 PDF 目录(TOC/书签)的树结构,将每个目录项(PDOutlineItem)转换为 Paragraph,并构建出完整的段落树(章节层级结构) |
package org.springframework.ai.reader.pdf.config;
import java.io.IOException;import java.io.PrintStream;import java.util.ArrayList;import java.util.List;import org.apache.pdfbox.pdmodel.PDDocument;import org.apache.pdfbox.pdmodel.PDPage;import org.apache.pdfbox.pdmodel.PDPageTree;import org.apache.pdfbox.pdmodel.interactive.documentnavigation.destination.PDPageXYZDestination;import org.apache.pdfbox.pdmodel.interactive.documentnavigation.outline.PDOutlineItem;import org.apache.pdfbox.pdmodel.interactive.documentnavigation.outline.PDOutlineNode;import org.springframework.util.Assert;import org.springframework.util.CollectionUtils;
public class ParagraphManager { private final Paragraph rootParagraph; private final PDDocument document;
public ParagraphManager(PDDocument document) { Assert.notNull(document, "PDDocument must not be null"); Assert.notNull(document.getDocumentCatalog().getDocumentOutline(), "Document outline (e.g. TOC) is null. Make sure the PDF document has a table of contents (TOC). If not, consider the PagePdfDocumentReader or the TikaDocumentReader instead.");
try { this.document = document; this.rootParagraph = this.generateParagraphs(new Paragraph((Paragraph)null, "root", -1, 1, this.document.getNumberOfPages(), 0), this.document.getDocumentCatalog().getDocumentOutline(), 0); this.printParagraph(this.rootParagraph, System.out); } catch (Exception e) { throw new RuntimeException(e); } }
public List<Paragraph> flatten() { List<Paragraph> paragraphs = new ArrayList();
for(Paragraph child : this.rootParagraph.children()) { this.flatten(child, paragraphs); }
return paragraphs; }
private void flatten(Paragraph current, List<Paragraph> paragraphs) { paragraphs.add(current);
for(Paragraph child : current.children()) { this.flatten(child, paragraphs); }
}
private void printParagraph(Paragraph paragraph, PrintStream printStream) { printStream.println(paragraph);
for(Paragraph childParagraph : paragraph.children()) { this.printParagraph(childParagraph, printStream); }
}
protected Paragraph generateParagraphs(Paragraph parentParagraph, PDOutlineNode bookmark, Integer level) throws IOException { for(PDOutlineItem current = bookmark.getFirstChild(); current != null; current = current.getNextSibling()) { int pageNumber = this.getPageNumber(current); int nextSiblingNumber = this.getPageNumber(current.getNextSibling()); if (nextSiblingNumber < 0) { nextSiblingNumber = this.getPageNumber(current.getLastChild()); }
int paragraphPosition = current.getDestination() instanceof PDPageXYZDestination ? ((PDPageXYZDestination)current.getDestination()).getTop() : 0; Paragraph currentParagraph = new Paragraph(parentParagraph, current.getTitle(), level, pageNumber, nextSiblingNumber, paragraphPosition); parentParagraph.children().add(currentParagraph); this.generateParagraphs(currentParagraph, current, level + 1); }
return parentParagraph; }
private int getPageNumber(PDOutlineItem current) throws IOException { if (current == null) { return -1; } else { PDPage currentPage = current.findDestinationPage(this.document); PDPageTree pages = this.document.getDocumentCatalog().getPages();
for(int i = 0; i < pages.getCount(); ++i) { PDPage page = pages.get(i); if (page.equals(currentPage)) { return i + 1; } }
return -1; } }
public List<Paragraph> getParagraphsByLevel(Paragraph paragraph, int level, boolean interLevelText) { List<Paragraph> resultList = new ArrayList(); if (paragraph.level() < level) { if (!CollectionUtils.isEmpty(paragraph.children())) { if (interLevelText) { Paragraph interLevelParagraph = new Paragraph(paragraph.parent(), paragraph.title(), paragraph.level(), paragraph.startPageNumber(), ((Paragraph)paragraph.children().get(0)).startPageNumber(), paragraph.position()); resultList.add(interLevelParagraph); }
for(Paragraph child : paragraph.children()) { resultList.addAll(this.getParagraphsByLevel(child, level, interLevelText)); } } } else if (paragraph.level() == level) { resultList.add(paragraph); }
return resultList; }
public static record Paragraph(Paragraph parent, String title, int level, int startPageNumber, int endPageNumber, int position, List<Paragraph> children) { public Paragraph(Paragraph parent, String title, int level, int startPageNumber, int endPageNumber, int position) { this(parent, title, level, startPageNumber, endPageNumber, position, new ArrayList()); }
public String toString() { String indent = this.level < 0 ? "" : (new String(new char[this.level * 2])).replace('\u0000', ' '); return indent + " " + this.level + ") " + this.title + " [" + this.startPageNumber + "," + this.endPageNumber + "], children = " + this.children.size() + ", pos = " + this.position; } }}TikaDocumentReader
用于从多种文档格式(如 PDF、DOC/DOCX、PPT/PPTX、HTML 等)中提取文本,并将其封装为 Document 对象,基于 Apache Tika 库实现,支持广泛的文档格式。
AutoDetectParser parser:自动检索文档类型并文本的解析器ContentHandler handler:管理内容提取的处理器Metadata metadata:读取文档相关的元数据ParseContext context:解析过程信息的上下文Resource resource:指向文档的资源对象ExtractedTextFormatter textFormatter:格式化提取的文本
| 方法名称 | 描述 |
| TikaDocumentReader | 通过资源URL、资源对象、文本格式化器等构造读取器 |
| get | 从多种文档格式读取,返回Document列表 |
package org.springframework.ai.reader.tika;
import java.io.IOException;import java.io.InputStream;import java.util.List;import java.util.Objects;import org.apache.tika.metadata.Metadata;import org.apache.tika.parser.AutoDetectParser;import org.apache.tika.parser.ParseContext;import org.apache.tika.sax.BodyContentHandler;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentReader;import org.springframework.ai.reader.ExtractedTextFormatter;import org.springframework.core.io.DefaultResourceLoader;import org.springframework.core.io.Resource;import org.springframework.util.StringUtils;import org.xml.sax.ContentHandler;
public class TikaDocumentReader implements DocumentReader { public static final String METADATASOURCE = "source"; private final AutoDetectParser parser; private final ContentHandler handler; private final Metadata metadata; private final ParseContext context; private final Resource resource; private final ExtractedTextFormatter textFormatter;
public TikaDocumentReader(String resourceUrl) { this(resourceUrl, ExtractedTextFormatter.defaults()); }
public TikaDocumentReader(String resourceUrl, ExtractedTextFormatter textFormatter) { this((new DefaultResourceLoader()).getResource(resourceUrl), textFormatter); }
public TikaDocumentReader(Resource resource) { this(resource, ExtractedTextFormatter.defaults()); }
public TikaDocumentReader(Resource resource, ExtractedTextFormatter textFormatter) { this(resource, new BodyContentHandler(-1), textFormatter); }
public TikaDocumentReader(Resource resource, ContentHandler contentHandler, ExtractedTextFormatter textFormatter) { this.parser = new AutoDetectParser(); this.handler = contentHandler; this.metadata = new Metadata(); this.context = new ParseContext(); this.resource = resource; this.textFormatter = textFormatter; }
public List<Document> get() { try (InputStream stream = this.resource.getInputStream()) { this.parser.parse(stream, this.handler, this.metadata, this.context); return List.of(this.toDocument(this.handler.toString())); } catch (Exception e) { throw new RuntimeException(e); } }
private Document toDocument(String docText) { docText = (String)Objects.requireNonNullElse(docText, ""); docText = this.textFormatter.format(docText); Document doc = new Document(docText); doc.getMetadata().put("source", this.resourceName()); return doc; }
private String resourceName() { try { String resourceName = this.resource.getFilename(); if (!StringUtils.hasText(resourceName)) { resourceName = this.resource.getURI().toString(); }
return resourceName; } catch (IOException e) { return String.format("Invalid source URI: %s", e.getMessage()); } }}DocumentTransformer(转换文档数据接口类)
package org.springframework.ai.document;
import java.util.List;import java.util.function.Function;
public interface DocumentTransformer extends Function<List<Document>, List<Document>> { default List<Document> transform(List<Document> transform) { return (List)this.apply(transform); }}TextSplitter
主要用于将长文本型 Document 拆分为多个较小的文本块(chunk),它为具体的文本分割策略(如按长度、按句子、按段落等)提供了通用框架
boolean copyContentFormatter:表示是否将文档内容格式化后,拆分复制到子文档中
| 方法名称 | 描述 |
| apply | 对输入文档列表进行拆分,返回拆分后的文档列表 |
| split | 拆分文档,返回拆分后的文档列表 |
| setCopyContentFormatter | 控制是否继承内容格式化器 |
| isCopyContentFormatter | 获取 copyContentFormatter 当前值 |
package org.springframework.ai.transformer.splitter;
import java.util.ArrayList;import java.util.List;import java.util.Map;import java.util.stream.Collectors;import org.slf4j.Logger;import org.slf4j.LoggerFactory;import org.springframework.ai.document.ContentFormatter;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentTransformer;
public abstract class TextSplitter implements DocumentTransformer { private static final Logger logger = LoggerFactory.getLogger(TextSplitter.class); private boolean copyContentFormatter = true;
public List<Document> apply(List<Document> documents) { return this.doSplitDocuments(documents); }
public List<Document> split(List<Document> documents) { return this.apply(documents); }
public List<Document> split(Document document) { return this.apply(List.of(document)); }
public boolean isCopyContentFormatter() { return this.copyContentFormatter; }
public void setCopyContentFormatter(boolean copyContentFormatter) { this.copyContentFormatter = copyContentFormatter; }
private List<Document> doSplitDocuments(List<Document> documents) { List<String> texts = new ArrayList(); List<Map<String, Object>> metadataList = new ArrayList(); List<ContentFormatter> formatters = new ArrayList();
for(Document doc : documents) { texts.add(doc.getText()); metadataList.add(doc.getMetadata()); formatters.add(doc.getContentFormatter()); }
return this.createDocuments(texts, formatters, metadataList); }
private List<Document> createDocuments(List<String> texts, List<ContentFormatter> formatters, List<Map<String, Object>> metadataList) { List<Document> documents = new ArrayList();
for(int i = 0; i < texts.size(); ++i) { String text = (String)texts.get(i); Map<String, Object> metadata = (Map)metadataList.get(i); List<String> chunks = this.splitText(text); if (chunks.size() > 1) { logger.info("Splitting up document into " + chunks.size() + " chunks."); }
for(String chunk : chunks) { Map<String, Object> metadataCopy = (Map)metadata.entrySet().stream().filter((e) -> e.getKey() != null && e.getValue() != null).collect(Collectors.toMap(Map.Entry::getKey, Map.Entry::getValue)); Document newDoc = new Document(chunk, metadataCopy); if (this.copyContentFormatter) { newDoc.setContentFormatter((ContentFormatter)formatters.get(i)); }
documents.add(newDoc); } }
return documents; }
protected abstract List<String> splitText(String text);}TokenTextSplitter
用于将文本按 token 拆分为指定大小块,基于 jtokit 库实现,适用于需要按 token 粒度处理文本的场景,如 LLM 的输入处理。
int chunkSize:每个文本块的目标 token 数量,默认为 800int minChunkSizeChars:每个文本块的最小字符数,默认为 350int minChunkLengthToEmbed:丢弃小于此长度的文本块,默认为 5int maxNumChunks:文本中生成的最大块数,默认为 10000boolean keepSeparator:是否保留分隔符(如换号符),默认EncodingRegistry registry:用于获取编码的注册表Encoding encoding:用于编码和解码的 token 的编码器
| 方法名称 | 描述 |
| splitText | 实现自 TextSplitter,将文本按 token 分块,返回分块后的字符串列表 |
| doSplit | 核心分块逻辑,按 token 长度切分文本 |
package org.springframework.ai.transformer.splitter;
import com.knuddels.jtokkit.Encodings;import com.knuddels.jtokkit.api.Encoding;import com.knuddels.jtokkit.api.EncodingRegistry;import com.knuddels.jtokkit.api.EncodingType;import com.knuddels.jtokkit.api.IntArrayList;import java.util.ArrayList;import java.util.List;import java.util.Objects;import org.springframework.util.Assert;
public class TokenTextSplitter extends TextSplitter { private static final int DEFAULTCHUNKSIZE = 800; private static final int MINCHUNKSIZECHARS = 350; private static final int MINCHUNKLENGTHTOEMBED = 5; private static final int MAXNUMCHUNKS = 10000; private static final boolean KEEPSEPARATOR = true; private final EncodingRegistry registry; private final Encoding encoding; private final int chunkSize; private final int minChunkSizeChars; private final int minChunkLengthToEmbed; private final int maxNumChunks; private final boolean keepSeparator;
public TokenTextSplitter() { this(800, 350, 5, 10000, true); }
public TokenTextSplitter(boolean keepSeparator) { this(800, 350, 5, 10000, keepSeparator); }
public TokenTextSplitter(int chunkSize, int minChunkSizeChars, int minChunkLengthToEmbed, int maxNumChunks, boolean keepSeparator) { this.registry = Encodings.newLazyEncodingRegistry(); this.encoding = this.registry.getEncoding(EncodingType.CL100KBASE); this.chunkSize = chunkSize; this.minChunkSizeChars = minChunkSizeChars; this.minChunkLengthToEmbed = minChunkLengthToEmbed; this.maxNumChunks = maxNumChunks; this.keepSeparator = keepSeparator; }
public static Builder builder() { return new Builder(); }
protected List<String> splitText(String text) { return this.doSplit(text, this.chunkSize); }
protected List<String> doSplit(String text, int chunkSize) { if (text != null && !text.trim().isEmpty()) { List<Integer> tokens = this.getEncodedTokens(text); List<String> chunks = new ArrayList(); int numchunks = 0;
while(!tokens.isEmpty() && numchunks < this.maxNumChunks) { List<Integer> chunk = tokens.subList(0, Math.min(chunkSize, tokens.size())); String chunkText = this.decodeTokens(chunk); if (chunkText.trim().isEmpty()) { tokens = tokens.subList(chunk.size(), tokens.size()); } else { int lastPunctuation = Math.max(chunkText.lastIndexOf(46), Math.max(chunkText.lastIndexOf(63), Math.max(chunkText.lastIndexOf(33), chunkText.lastIndexOf(10)))); if (lastPunctuation != -1 && lastPunctuation > this.minChunkSizeChars) { chunkText = chunkText.substring(0, lastPunctuation + 1); }
String chunkTextToAppend = this.keepSeparator ? chunkText.trim() : chunkText.replace(System.lineSeparator(), " ").trim(); if (chunkTextToAppend.length() > this.minChunkLengthToEmbed) { chunks.add(chunkTextToAppend); }
tokens = tokens.subList(this.getEncodedTokens(chunkText).size(), tokens.size()); ++numchunks; } }
if (!tokens.isEmpty()) { String remainingtext = this.decodeTokens(tokens).replace(System.lineSeparator(), " ").trim(); if (remainingtext.length() > this.minChunkLengthToEmbed) { chunks.add(remainingtext); } }
return chunks; } else { return new ArrayList(); } }
private List<Integer> getEncodedTokens(String text) { Assert.notNull(text, "Text must not be null"); return this.encoding.encode(text).boxed(); }
private String decodeTokens(List<Integer> tokens) { Assert.notNull(tokens, "Tokens must not be null"); IntArrayList tokensIntArray = new IntArrayList(tokens.size()); Objects.requireNonNull(tokensIntArray); tokens.forEach(tokensIntArray::add); return this.encoding.decode(tokensIntArray); }
public static final class Builder { private int chunkSize = 800; private int minChunkSizeChars = 350; private int minChunkLengthToEmbed = 5; private int maxNumChunks = 10000; private boolean keepSeparator = true;
private Builder() { }
public Builder withChunkSize(int chunkSize) { this.chunkSize = chunkSize; return this; }
public Builder withMinChunkSizeChars(int minChunkSizeChars) { this.minChunkSizeChars = minChunkSizeChars; return this; }
public Builder withMinChunkLengthToEmbed(int minChunkLengthToEmbed) { this.minChunkLengthToEmbed = minChunkLengthToEmbed; return this; }
public Builder withMaxNumChunks(int maxNumChunks) { this.maxNumChunks = maxNumChunks; return this; }
public Builder withKeepSeparator(boolean keepSeparator) { this.keepSeparator = keepSeparator; return this; }
public TokenTextSplitter build() { return new TokenTextSplitter(this.chunkSize, this.minChunkSizeChars, this.minChunkLengthToEmbed, this.maxNumChunks, this.keepSeparator); } }}ContentFormatTransformer
对 Document 列表中的每个文档应用内容格式化器,以格式化文档
boolean disableTemplateRewrite:表示是否禁用内容格式化器的模版重写功能ContentFormatter contentFormatter:用于格式化文档内容的实例
package org.springframework.ai.transformer;
import java.util.ArrayList;import java.util.List;import org.springframework.ai.document.ContentFormatter;import org.springframework.ai.document.DefaultContentFormatter;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentTransformer;
public class ContentFormatTransformer implements DocumentTransformer { private final boolean disableTemplateRewrite; private final ContentFormatter contentFormatter;
public ContentFormatTransformer(ContentFormatter contentFormatter) { this(contentFormatter, false); }
public ContentFormatTransformer(ContentFormatter contentFormatter, boolean disableTemplateRewrite) { this.contentFormatter = contentFormatter; this.disableTemplateRewrite = disableTemplateRewrite; }
public List<Document> apply(List<Document> documents) { if (this.contentFormatter != null) { documents.forEach(this::processDocument); }
return documents; }
private void processDocument(Document document) { ContentFormatter var4 = document.getContentFormatter(); if (var4 instanceof DefaultContentFormatter docFormatter) { var4 = this.contentFormatter; if (var4 instanceof DefaultContentFormatter toUpdateFormatter) { this.updateFormatter(document, docFormatter, toUpdateFormatter); return; } }
this.overrideFormatter(document); }
private void updateFormatter(Document document, DefaultContentFormatter docFormatter, DefaultContentFormatter toUpdateFormatter) { List<String> updatedEmbedExcludeKeys = new ArrayList(docFormatter.getExcludedEmbedMetadataKeys()); updatedEmbedExcludeKeys.addAll(toUpdateFormatter.getExcludedEmbedMetadataKeys()); List<String> updatedInterfaceExcludeKeys = new ArrayList(docFormatter.getExcludedInferenceMetadataKeys()); updatedInterfaceExcludeKeys.addAll(toUpdateFormatter.getExcludedInferenceMetadataKeys()); DefaultContentFormatter.Builder builder = DefaultContentFormatter.builder().withExcludedEmbedMetadataKeys(updatedEmbedExcludeKeys).withExcludedInferenceMetadataKeys(updatedInterfaceExcludeKeys).withMetadataTemplate(docFormatter.getMetadataTemplate()).withMetadataSeparator(docFormatter.getMetadataSeparator()); if (!this.disableTemplateRewrite) { builder.withTextTemplate(docFormatter.getTextTemplate()); }
document.setContentFormatter(builder.build()); }
private void overrideFormatter(Document document) { document.setContentFormatter(this.contentFormatter); }}ContentFormatte(格式化接口类)
public interface ContentFormatter {
String format(Document document, MetadataMode mode);
}DefaultContentFormatter
用于格式化 Document 对象的内容和元数据,通过模版和配置来控制文档显示方式
String metadataTemplate:元数据格式化模版,包含{key}和{value}占位符String metadataSeparator:元数据字段之间的分隔符String textTemplate:文档文本格式化模板,包含{content}和{metadatastring}占位符List<String> excludedInferenceMetadataKeys:在推理模式下排除的元数据键列表List<String> excludedEmbedMetadataKeys:在嵌入模式下排除的元数据键列表
package org.springframework.ai.document;
import java.util.ArrayList;import java.util.Arrays;import java.util.Collections;import java.util.HashMap;import java.util.HashSet;import java.util.List;import java.util.Map;import java.util.Set;import java.util.stream.Collectors;import org.springframework.util.Assert;
public final class DefaultContentFormatter implements ContentFormatter { private static final String TEMPLATECONTENTPLACEHOLDER = "{content}"; private static final String TEMPLATEMETADATASTRINGPLACEHOLDER = "{metadatastring}"; private static final String TEMPLATEVALUEPLACEHOLDER = "{value}"; private static final String TEMPLATEKEYPLACEHOLDER = "{key}"; private static final String DEFAULTMETADATATEMPLATE = String.format("%s: %s", "{key}", "{value}"); private static final String DEFAULTMETADATASEPARATOR = System.lineSeparator(); private static final String DEFAULTTEXTTEMPLATE = String.format("%s\n\n%s", "{metadatastring}", "{content}"); private final String metadataTemplate; private final String metadataSeparator; private final String textTemplate; private final List<String> excludedInferenceMetadataKeys; private final List<String> excludedEmbedMetadataKeys;
private DefaultContentFormatter(Builder builder) { this.metadataTemplate = builder.metadataTemplate; this.metadataSeparator = builder.metadataSeparator; this.textTemplate = builder.textTemplate; this.excludedInferenceMetadataKeys = builder.excludedInferenceMetadataKeys; this.excludedEmbedMetadataKeys = builder.excludedEmbedMetadataKeys; }
public static Builder builder() { return new Builder(); }
public static DefaultContentFormatter defaultConfig() { return builder().build(); }
public String format(Document document, MetadataMode metadataMode) { Map<String, Object> metadata = this.metadataFilter(document.getMetadata(), metadataMode); String metadataText = (String)metadata.entrySet().stream().map((metadataEntry) -> this.metadataTemplate.replace("{key}", (CharSequence)metadataEntry.getKey()).replace("{value}", metadataEntry.getValue().toString())).collect(Collectors.joining(this.metadataSeparator)); return this.textTemplate.replace("{metadatastring}", metadataText).replace("{content}", document.getText()); }
protected Map<String, Object> metadataFilter(Map<String, Object> metadata, MetadataMode metadataMode) { if (metadataMode == MetadataMode.ALL) { return new HashMap(metadata); } else if (metadataMode == MetadataMode.NONE) { return new HashMap(Collections.emptyMap()); } else { Set<String> usableMetadataKeys = new HashSet(metadata.keySet()); if (metadataMode == MetadataMode.INFERENCE) { usableMetadataKeys.removeAll(this.excludedInferenceMetadataKeys); } else if (metadataMode == MetadataMode.EMBED) { usableMetadataKeys.removeAll(this.excludedEmbedMetadataKeys); }
return new HashMap((Map)metadata.entrySet().stream().filter((e) -> usableMetadataKeys.contains(e.getKey())).collect(Collectors.toMap((e) -> (String)e.getKey(), (e) -> e.getValue()))); } }
public String getMetadataTemplate() { return this.metadataTemplate; }
public String getMetadataSeparator() { return this.metadataSeparator; }
public String getTextTemplate() { return this.textTemplate; }
public List<String> getExcludedInferenceMetadataKeys() { return Collections.unmodifiableList(this.excludedInferenceMetadataKeys); }
public List<String> getExcludedEmbedMetadataKeys() { return Collections.unmodifiableList(this.excludedEmbedMetadataKeys); }
public static final class Builder { private String metadataTemplate; private String metadataSeparator; private String textTemplate; private List<String> excludedInferenceMetadataKeys; private List<String> excludedEmbedMetadataKeys;
private Builder() { this.metadataTemplate = DefaultContentFormatter.DEFAULTMETADATATEMPLATE; this.metadataSeparator = DefaultContentFormatter.DEFAULTMETADATASEPARATOR; this.textTemplate = DefaultContentFormatter.DEFAULTTEXTTEMPLATE; this.excludedInferenceMetadataKeys = new ArrayList(); this.excludedEmbedMetadataKeys = new ArrayList(); }
public Builder from(DefaultContentFormatter fromFormatter) { this.withExcludedEmbedMetadataKeys(fromFormatter.getExcludedEmbedMetadataKeys()).withExcludedInferenceMetadataKeys(fromFormatter.getExcludedInferenceMetadataKeys()).withMetadataSeparator(fromFormatter.getMetadataSeparator()).withMetadataTemplate(fromFormatter.getMetadataTemplate()).withTextTemplate(fromFormatter.getTextTemplate()); return this; }
public Builder withMetadataTemplate(String metadataTemplate) { Assert.hasText(metadataTemplate, "Metadata Template must not be empty"); this.metadataTemplate = metadataTemplate; return this; }
public Builder withMetadataSeparator(String metadataSeparator) { Assert.notNull(metadataSeparator, "Metadata separator must not be empty"); this.metadataSeparator = metadataSeparator; return this; }
public Builder withTextTemplate(String textTemplate) { Assert.hasText(textTemplate, "Document's text template must not be empty"); this.textTemplate = textTemplate; return this; }
public Builder withExcludedInferenceMetadataKeys(List<String> excludedInferenceMetadataKeys) { Assert.notNull(excludedInferenceMetadataKeys, "Excluded inference metadata keys must not be null"); this.excludedInferenceMetadataKeys = excludedInferenceMetadataKeys; return this; }
public Builder withExcludedInferenceMetadataKeys(String... keys) { Assert.notNull(keys, "Excluded inference metadata keys must not be null"); this.excludedInferenceMetadataKeys.addAll(Arrays.asList(keys)); return this; }
public Builder withExcludedEmbedMetadataKeys(List<String> excludedEmbedMetadataKeys) { Assert.notNull(excludedEmbedMetadataKeys, "Excluded Embed metadata keys must not be null"); this.excludedEmbedMetadataKeys = excludedEmbedMetadataKeys; return this; }
public Builder withExcludedEmbedMetadataKeys(String... keys) { Assert.notNull(keys, "Excluded Embed metadata keys must not be null"); this.excludedEmbedMetadataKeys.addAll(Arrays.asList(keys)); return this; }
public DefaultContentFormatter build() { return new DefaultContentFormatter(this); } }}KeywordMetadataEnricher
从文档中提取关键词,并将其作为元数据添加到文档中。通过调用 ChatModel 生成关键词,并将关键词存储在文档的元数据中
ChatModel chatModel:与 LLM 交互,生成关键词int keywordCount:要提取的关键词数量
package org.springframework.ai.model.transformer;
import java.util.List;import java.util.Map;import org.springframework.ai.chat.model.ChatModel;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentTransformer;import org.springframework.util.Assert;
public class KeywordMetadataEnricher implements DocumentTransformer { public static final String CONTEXTSTRPLACEHOLDER = "contextstr"; public static final String KEYWORDSTEMPLATE = "{contextstr}. Give %s unique keywords for this\ndocument. Format as comma separated. Keywords:"; private static final String EXCERPTKEYWORDSMETADATAKEY = "excerptkeywords"; private final ChatModel chatModel; private final int keywordCount;
public KeywordMetadataEnricher(ChatModel chatModel, int keywordCount) { Assert.notNull(chatModel, "ChatModel must not be null"); Assert.isTrue(keywordCount >= 1, "Document count must be >= 1"); this.chatModel = chatModel; this.keywordCount = keywordCount; }
public List<Document> apply(List<Document> documents) { for(Document document : documents) { PromptTemplate template = new PromptTemplate(String.format("{contextstr}. Give %s unique keywords for this\ndocument. Format as comma separated. Keywords:", this.keywordCount)); Prompt prompt = template.create(Map.of("contextstr", document.getText())); String keywords = this.chatModel.call(prompt).getResult().getOutput().getText(); document.getMetadata().putAll(Map.of("excerptkeywords", keywords)); }
return documents; }}SummaryMetadataEnricher
用于从文档中提取摘要,并将其作为元数据添加到文档中。支持提取当前文档、前一个文档和下一个文档的摘要,并将这些摘要存储在文档的元数据中
-
ChatModel chatModel:与 LLM 交互,生成摘要 -
List<SummaryType> summaryTypes:要提取的摘要类型列表(当前、前一个、后一个) -
MetadataMode metadataMode:元数据模式,用于控制文档内容的格式化方式- ALL:格式化内容时包含所有元数据(如作者、页码、标题等),适合需要上下文丰富信息的场景
- EMBED:仅包含用于向量嵌入相关的元数据。通常用于向量数据库检索,保证只输出对嵌入有用的元数据,减少无关信息干扰
- INFERENCE:仅包含推理相关的元数据。适合推理、问答等场景,输出对模型推理有帮助的元数据,过滤掉无关内容
- NONE:只输出纯文本内容,不包含任何元数据,适合只关心正文的场景
-
String summaryTemplate:用于生成摘要的模版
package org.springframework.ai.model.transformer;
import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import org.springframework.ai.chat.model.ChatModel;import org.springframework.ai.chat.prompt.Prompt;import org.springframework.ai.chat.prompt.PromptTemplate;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentTransformer;import org.springframework.ai.document.MetadataMode;import org.springframework.util.Assert;import org.springframework.util.CollectionUtils;
public class SummaryMetadataEnricher implements DocumentTransformer { public static final String DEFAULTSUMMARYEXTRACTTEMPLATE = "Here is the content of the section:\n{contextstr}\n\nSummarize the key topics and entities of the section.\n\nSummary:"; private static final String SECTIONSUMMARYMETADATAKEY = "sectionsummary"; private static final String NEXTSECTIONSUMMARYMETADATAKEY = "nextsectionsummary"; private static final String PREVSECTIONSUMMARYMETADATAKEY = "prevsectionsummary"; private static final String CONTEXTSTRPLACEHOLDER = "contextstr"; private final ChatModel chatModel; private final List<SummaryType> summaryTypes; private final MetadataMode metadataMode; private final String summaryTemplate;
public SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes) { this(chatModel, summaryTypes, "Here is the content of the section:\n{contextstr}\n\nSummarize the key topics and entities of the section.\n\nSummary:", MetadataMode.ALL); }
public SummaryMetadataEnricher(ChatModel chatModel, List<SummaryType> summaryTypes, String summaryTemplate, MetadataMode metadataMode) { Assert.notNull(chatModel, "ChatModel must not be null"); Assert.hasText(summaryTemplate, "Summary template must not be empty"); this.chatModel = chatModel; this.summaryTypes = CollectionUtils.isEmpty(summaryTypes) ? List.of(SummaryMetadataEnricher.SummaryType.CURRENT) : summaryTypes; this.metadataMode = metadataMode; this.summaryTemplate = summaryTemplate; }
public List<Document> apply(List<Document> documents) { List<String> documentSummaries = new ArrayList();
for(Document document : documents) { String documentContext = document.getFormattedContent(this.metadataMode); Prompt prompt = (new PromptTemplate(this.summaryTemplate)).create(Map.of("contextstr", documentContext)); documentSummaries.add(this.chatModel.call(prompt).getResult().getOutput().getText()); }
for(int i = 0; i < documentSummaries.size(); ++i) { Map<String, Object> summaryMetadata = this.getSummaryMetadata(i, documentSummaries); ((Document)documents.get(i)).getMetadata().putAll(summaryMetadata); }
return documents; }
private Map<String, Object> getSummaryMetadata(int i, List<String> documentSummaries) { Map<String, Object> summaryMetadata = new HashMap(); if (i > 0 && this.summaryTypes.contains(SummaryMetadataEnricher.SummaryType.PREVIOUS)) { summaryMetadata.put("prevsectionsummary", documentSummaries.get(i - 1)); }
if (i < documentSummaries.size() - 1 && this.summaryTypes.contains(SummaryMetadataEnricher.SummaryType.NEXT)) { summaryMetadata.put("nextsectionsummary", documentSummaries.get(i + 1)); }
if (this.summaryTypes.contains(SummaryMetadataEnricher.SummaryType.CURRENT)) { summaryMetadata.put("sectionsummary", documentSummaries.get(i)); }
return summaryMetadata; }
public static enum SummaryType { PREVIOUS, CURRENT, NEXT; }}DocumentWriter(文档写入接口类)
package org.springframework.ai.document;
import java.util.List;import java.util.function.Consumer;
public interface DocumentWriter extends Consumer<List<Document>> { default void write(List<Document> documents) { this.accept(documents); }}FileDocumentWriter
将一组 Document 文档对象的内容写入到指定文件,支持追加写入、文档分隔标记、元数据格式化等功能
String fileName:写入文件的名称boolean withDocumentMarkers:表示是否在文件中包含文档标记(如文档索引、页码)MetadataMode metadataMode:元数据模式,控制文档内容的格式化方式boolean append:是否将内容追加到文件末尾,而不是覆盖
| 方法名称 | 描述 |
| FileDocumentWriter | 通过文件名、分隔标记、元数据、追加等构造写入器 |
| accept | 将文档内容写入文件,支持分隔标记和元数据格式化 |
package org.springframework.ai.writer;
import java.io.FileWriter;import java.util.List;import org.springframework.ai.document.Document;import org.springframework.ai.document.DocumentWriter;import org.springframework.ai.document.MetadataMode;import org.springframework.util.Assert;
public class FileDocumentWriter implements DocumentWriter { public static final String METADATASTARTPAGENUMBER = "pagenumber"; public static final String METADATAENDPAGENUMBER = "endpagenumber"; private final String fileName; private final boolean withDocumentMarkers; private final MetadataMode metadataMode; private final boolean append;
public FileDocumentWriter(String fileName) { this(fileName, false, MetadataMode.NONE, false); }
public FileDocumentWriter(String fileName, boolean withDocumentMarkers) { this(fileName, withDocumentMarkers, MetadataMode.NONE, false); }
public FileDocumentWriter(String fileName, boolean withDocumentMarkers, MetadataMode metadataMode, boolean append) { Assert.hasText(fileName, "File name must have a text."); Assert.notNull(metadataMode, "MetadataMode must not be null."); this.fileName = fileName; this.withDocumentMarkers = withDocumentMarkers; this.metadataMode = metadataMode; this.append = append; }
public void accept(List<Document> docs) { try { try (FileWriter writer = new FileWriter(this.fileName, this.append)) { int index = 0;
for(Document doc : docs) { if (this.withDocumentMarkers) { writer.write(String.format("%n### Doc: %s, pages:[%s,%s]\n", index, doc.getMetadata().get("pagenumber"), doc.getMetadata().get("endpagenumber"))); }
writer.write(doc.getFormattedContent(this.metadataMode)); ++index; } }
} catch (Exception e) { throw new RuntimeException(e); } }}VectorStore
VectorStore 继承了 DocumentWriter 接口,详情可见第五章:向量数据库篇