项目简介
这是一个基于Spring AI Alibaba的自然语言转SQL项目,能让你用自然语言直接查询数据库,不需要写复杂的SQL。
Github repository: https://github.com/spring-ai-alibaba/dataagent
项目结构
这个项目分为三个部分:
spring-ai-alibaba-data-agent/
├── spring-ai-alibaba-data-agent-management # 管理端(可直接启动的Web应用)
├── spring-ai-alibaba-data-agent-chat # 核心功能(不能独立启动,供集成使用)
└── spring-ai-alibaba-data-agent-common # 公共代码
快速启动
项目进行本地测试是在spring-ai-alibaba-data-agent-management中进行
1. 业务数据库准备
可以在项目仓库获取测试表和数据:
文件在:spring-ai-alibaba-data-agent-management/src/main/resources/sql,里面有两个文件:schema.sql 和 data.sql
将表和数据导入到你的MySQL数据库中。
2. 配置
2.1 配置management数据库
在spring-ai-alibaba-data-agent-management/src/main/resources/application.yml中配置你的MySQL数据库连接信息。
初始化行为说明:默认开启自动创建表并插入示例数据(
spring.sql.init.mode: always)。生产环境建议关闭,避免示例数据回填覆盖你的业务数据。
spring:
datasource:
url: jdbc:mysql://127.0.0.1:3306/saa_data_agent?useUnicode=true&characterEncoding=utf-8&zeroDateTimeBehavior=convertToNull&transformedBitIsBoolean=true&allowMultiQueries=true&allowPublicKeyRetrieval=true&useSSL=false&serverTimezone=Asia/Shanghai
username: ${MYSQL_USERNAME:root}
password: ${MYSQL_PASSWORD:root}
driver-class-name: com.mysql.cj.jdbc.Driver
type: com.alibaba.druid.pool.DruidDataSource
2.2 可选:启用/关闭自动初始化(schema.sql + data.sql)
- 默认配置:
application.yml中已设置为开启
spring:
sql:
init:
mode: always # 默认:每次启动执行 schema.sql 与 data.sql
schema-locations: classpath:sql/schema.sql
data-locations: classpath:sql/data.sql
- 若不希望每次启动回填示例数据,可将
mode改为never关闭:
spring:
sql:
init:
mode: never # 关闭自动初始化
schema-locations: classpath:sql/schema.sql
data-locations: classpath:sql/data.sql
��注意:默认开启时(mode: always),data.sql 会在每次启动回填示例数据(即使你手动删除了数据)。生产环境请改为 mode: never,避免覆盖/复原业务数据。
2.3 配置 API Key
spring:
ai:
dashscope:
api-key: ${AI_DASHSCOPE_API_KEY}
chat:
enabled: true
options:
model: qwen-plus
embedding:
enabled: true
options:
model: text-embedding-v4
推荐将API Key配置到环境变量中,并使用${AI_DASHSCOPE_API_KEY}引用。
2.4 嵌入模型批处理策略配置
| 属性 | 说明 | 默认值 |
|---|---|---|
| spring.ai.alibaba.data-agent.embedding-batch.encoding-type | 文本编码类型,可参考com.knuddels.jtokkit.api.EncodingType | cl100k_base |
| spring.ai.alibaba.data-agent.embedding-batch.max-token-count | 每批次最大令牌数 值越小,每批次文档越少,但更安全 值越大,处理效率越高,但可能超出API限制 建议值:2000-8000,根据实际API限制调整 | 2000 |
| spring.ai.alibaba.data-agent.embedding-batch.reserve-percentage | 预留百分比 用于预留缓冲空间,避免超出限制 建议值:0.1-0.2(10%-20%) | 0.2 |
| spring.ai.alibaba.data-agent.embedding-batch.max-text-count | 每批次最大文本数量 适用于DashScope等有文本数量限制的API DashScope限制为10 | 10 |
2.5 向量库配置
| 属性 | 说明 | 默认值 |
|---|---|---|
| spring.ai.alibaba.data-agent.vector-store.similarity-threshold | 相似度阈值配置,用于过滤相似度分数大于等于此阈值的文档 | 0.2 |
| spring.ai.alibaba.data-agent.vector-store.batch-del-topk-limit | 一次删除操作中,最多删除的文档数量 | 5000 |
| spring.ai.alibaba.data-agent.vector-store.topk-limit | 查询返回最大文档数 | 30 |
| spring.ai.alibaba.data-agent.vector-store.enable-hybrid-search | 是否启用混合搜索。注意:项目目前默认只提供ES的混合检索能力, 如需要扩展其他向量库可自行继承重写 com.alibaba.cloud.ai.dataagent.service.hybrid.retrieval .AbstractHybridRetrievalStrategy#retrieve 该方法 并且修改com.alibaba.cloud.ai.service.hybrid. factory.HybridRetrievalStrategyFactory#getObject 注册相应的bean | false |
| spring.ai.alibaba.data-agent.vector-store.elasticsearch-min-score | Elasticsearch最小分数阈值,用于es执行关键词搜索时过滤相关性较低的文档。 开发时使用的es服务端版本 8.15.0 | 0.5 |
2.6 检索融合策略
| 属性 | 说明 | 默认值 |
|---|---|---|
| spring.ai.alibaba.data-agent.fusion-strategy | 多路召回结果融合策略 | rrf |
2.7 替换chat-model、embedding-model和vector-store的实现类
本项目的ChatModel和EmbeddingModel默认使用DashScope的实现,VectorStore默认使用内存向量,你可以替换成其他模型实现。
在根pom中的dependencies中可以替换ChatModel,EmbeddingModel和VectorStore的实现starter,以替换掉项目默认使用的实现:
<dependencies>
<!-- 在这里可以替换vector-store,chat-model和embedding-model的starter -->
<!-- 如果不使用默认依赖的话,需要手动配置application.yml -->
<dependency>
<groupId>com.alibaba.cloud.ai</groupId>
<artifactId>spring-ai-alibaba-starter-dashscope</artifactId>
<version>${spring-ai-alibaba.version}</version>
</dependency>
<!-- milvus -->
<!-- <dependency>-->
<!-- <groupId>org.springframework.ai</groupId>-->
<!-- <artifactId>spring-ai-starter-vector-store-milvus</artifactId>-->
<!-- </dependency>-->
</dependencies>
注意修改application.yml,以符合这些starter的需求。
举个例子,如果你需要使用Milvus作为向量库,使用DeepSeek的ChatModel,使用硅基流动的EmbeddingModel,你可以导入以下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-deepseek</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-model-openai</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-milvus</artifactId>
</dependency>
</dependencies>
然后这么写application.yml:
spring:
ai:
model:
chat: deepseek # 一定要配置此字段,否则会报多个Bean实例的异常
embedding: openai
deepseek:
chat:
api-key: ${DEEPSEEK_API_KEY}
openai:
api-key: ${SILICONFLOW_API_KEY}
embedding:
api-key: ${SILICONFLOW_API_KEY}
base-url: https://api.siliconflow.cn
options:
model: BAAI/bge-m3
vectorstore:
milvus:
initialize-schema: true
client:
host: ${MILVUS_HOST:192.168.16.100}
port: ${MILVUS_PORT:19530}
username: ${MILVUS_USERNAME:root}
password: ${MILVUS_PASSWORD}
databaseName: ${MILVUS_DATABASE:default}
collectionName: ${MILVUS_COLLECTION:vector_store}
embeddingDimension: 1536
indexType: IVF_FLAT
metricType: COSINE
id-field-name:
content-field-name:
metadata-field-name:
embedding-field-name:
3. 启动管理端
在spring-ai-alibaba-data-agent-management目录下,运行 DataAgentApplication.java 类。
4. 启动WEB页面
进入 spring-ai-alibaba-data-agent-frontend 目录
4.1 安装依赖
# 使用 npm
npm install
# 或使用 yarn
yarn install
4.2 启动服务
# 使用 npm
npm run dev
# 或使用 yarn
yarn dev
启动成功后,访问地址 http://localhost:3000
系统体验
数据智能体的创建与配置
访问 http://localhost:3000 ,可以看到当前项目的智能体列表(默认有四个占位智能体,并没有对接数据,可以删除掉然后创建新的智能体)
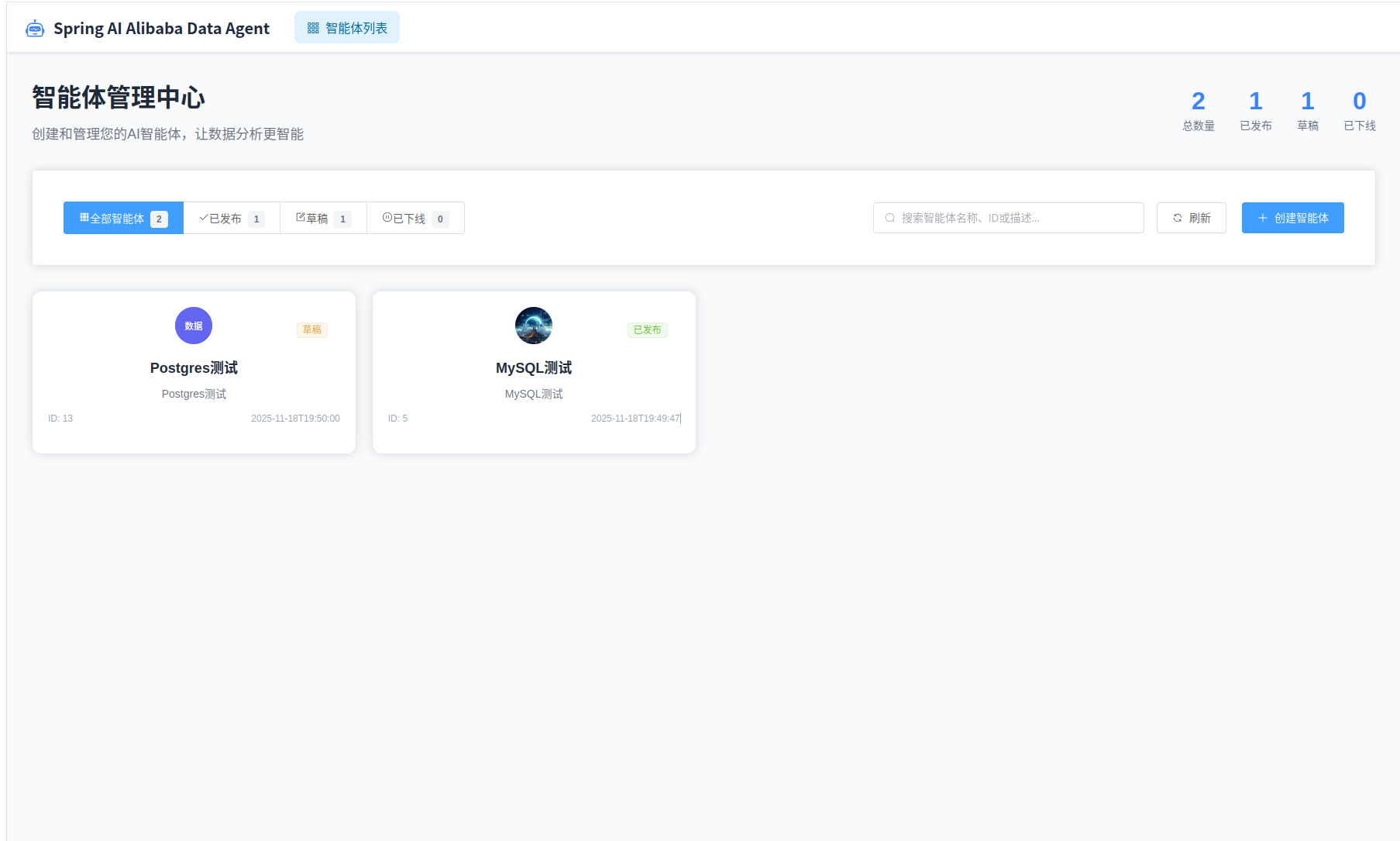
点击右上角“创建智能体” ,这里只需要输入智能体名称,其他配置都选默认。
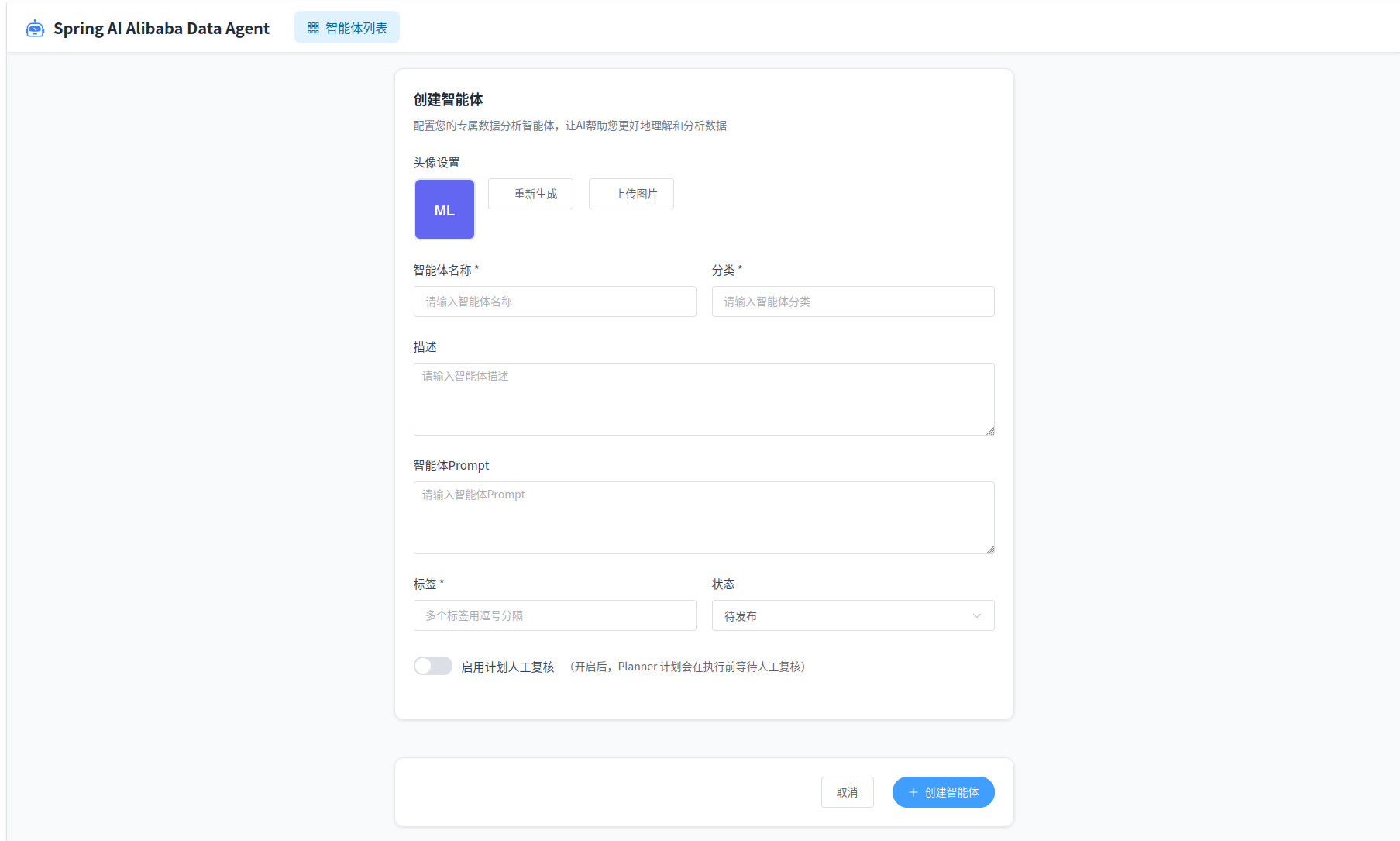
创建成功后,可以看到智能体配置页面。
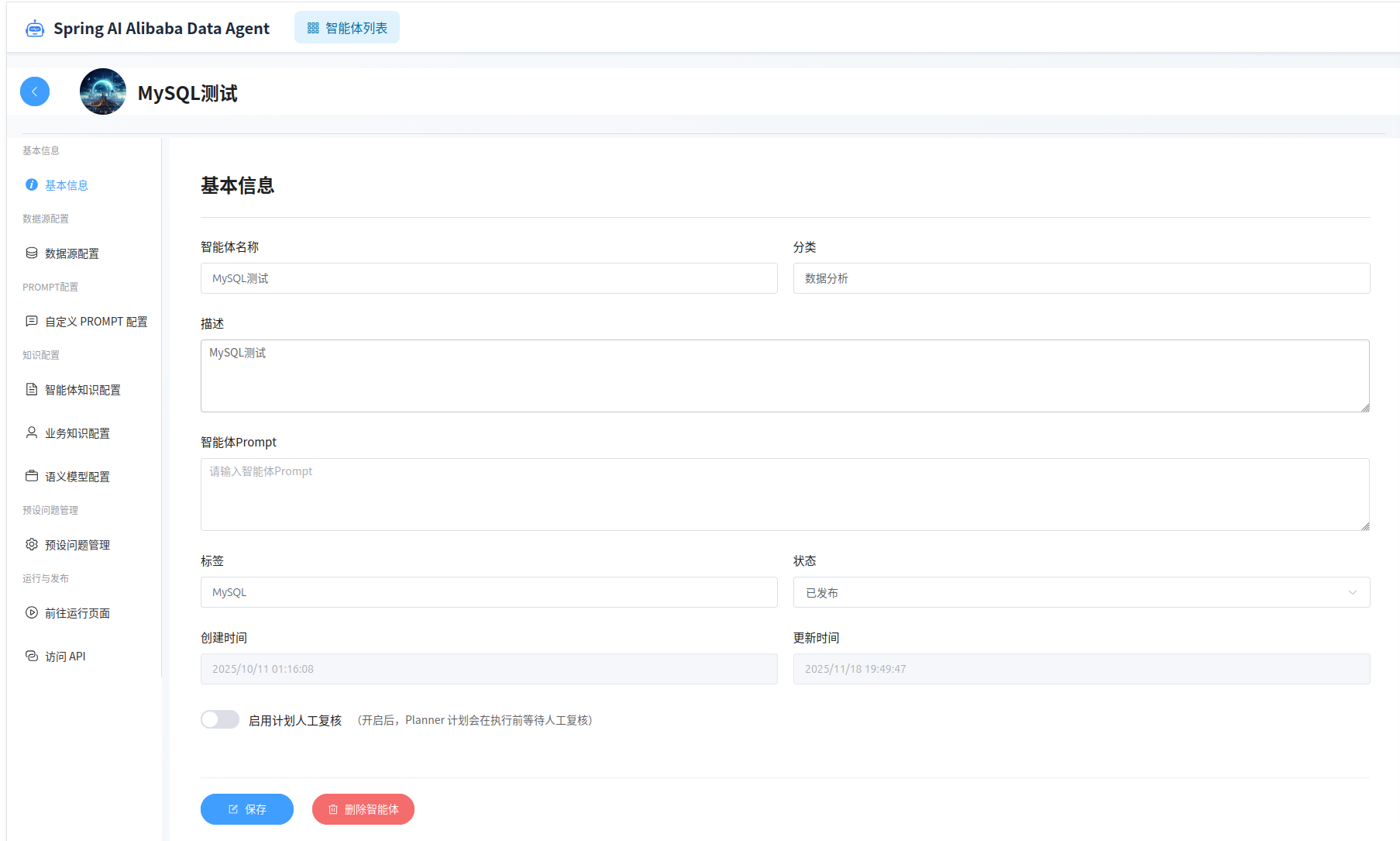
进入数据源配置页面,配置业务数据库(我们在环境初始化时第一步提供的业务数据库)。
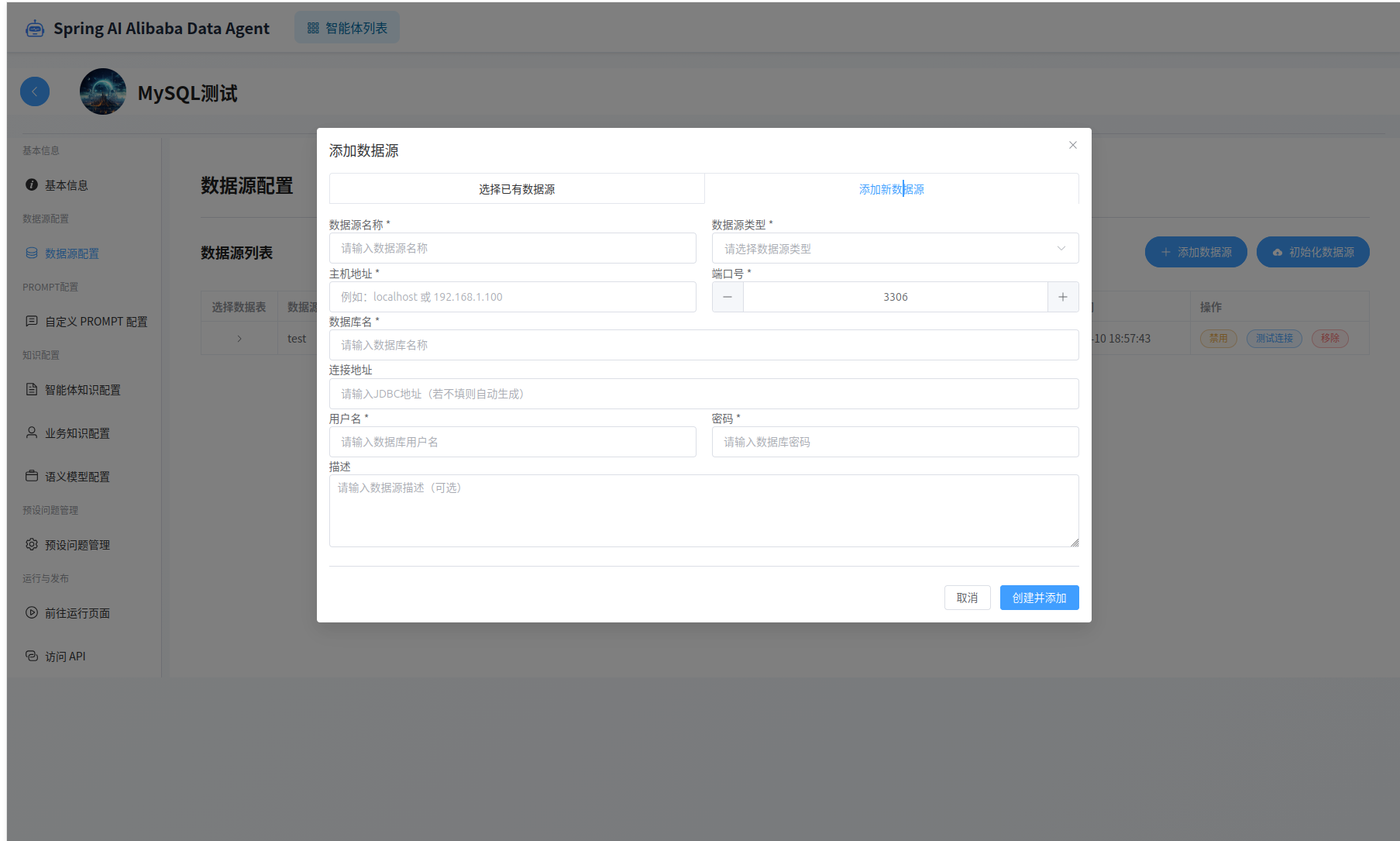
添加完成后,可以在列表页面验证数据源连接是否正常。
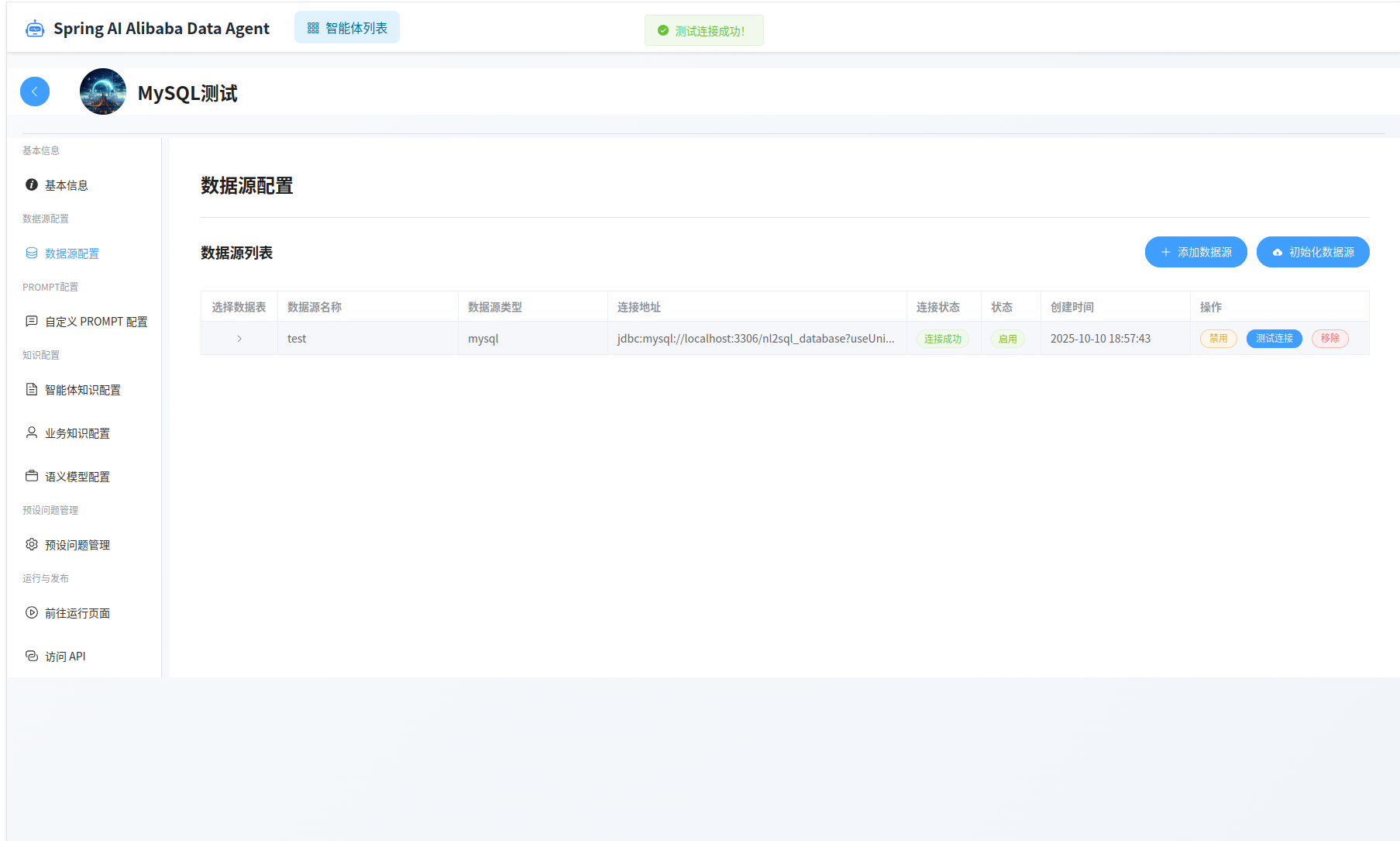
对于添加的新数据源,需要选择使用哪些数据表进行数据分析。
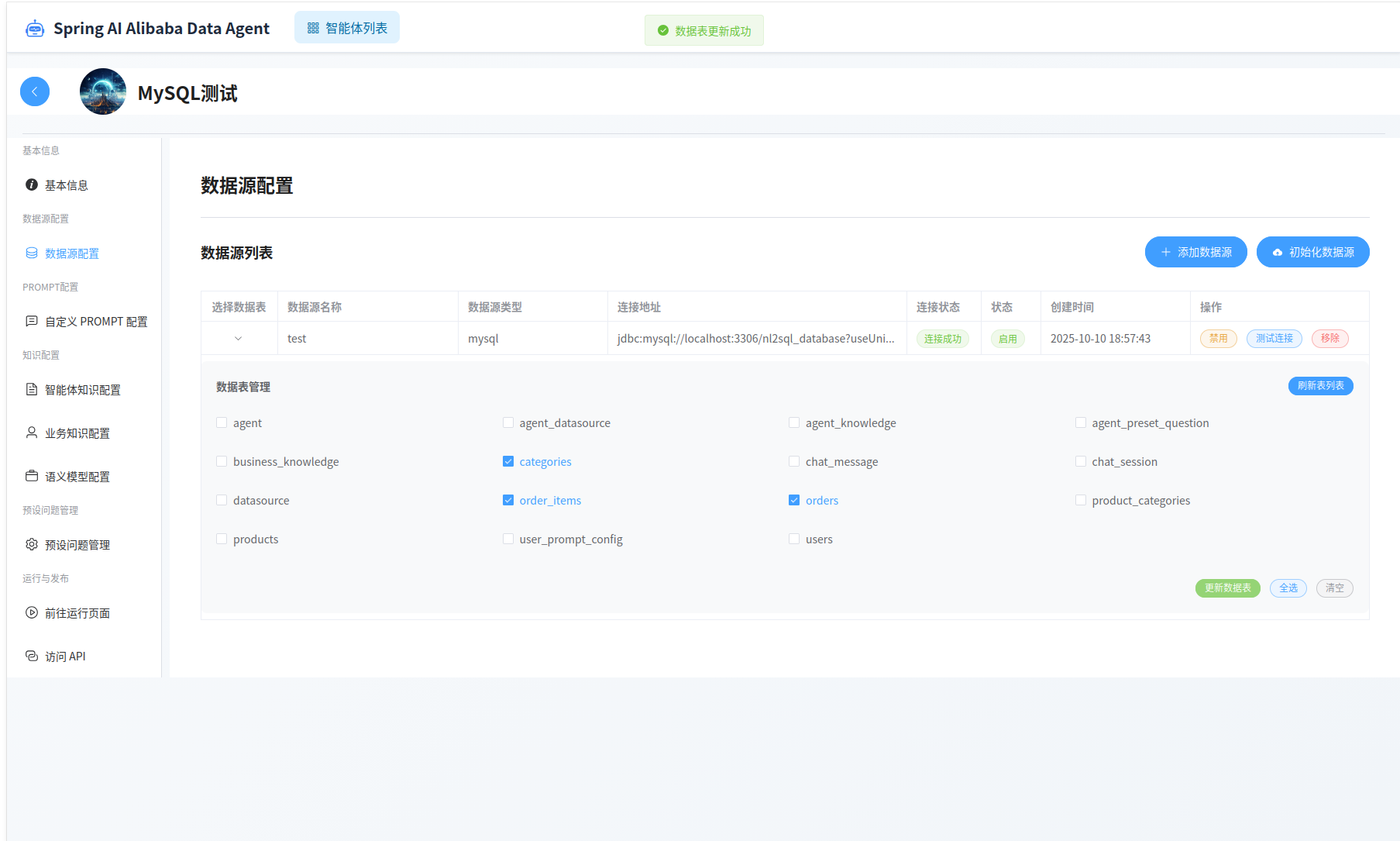
之后点击右上角的“初始化数据源”按钮。
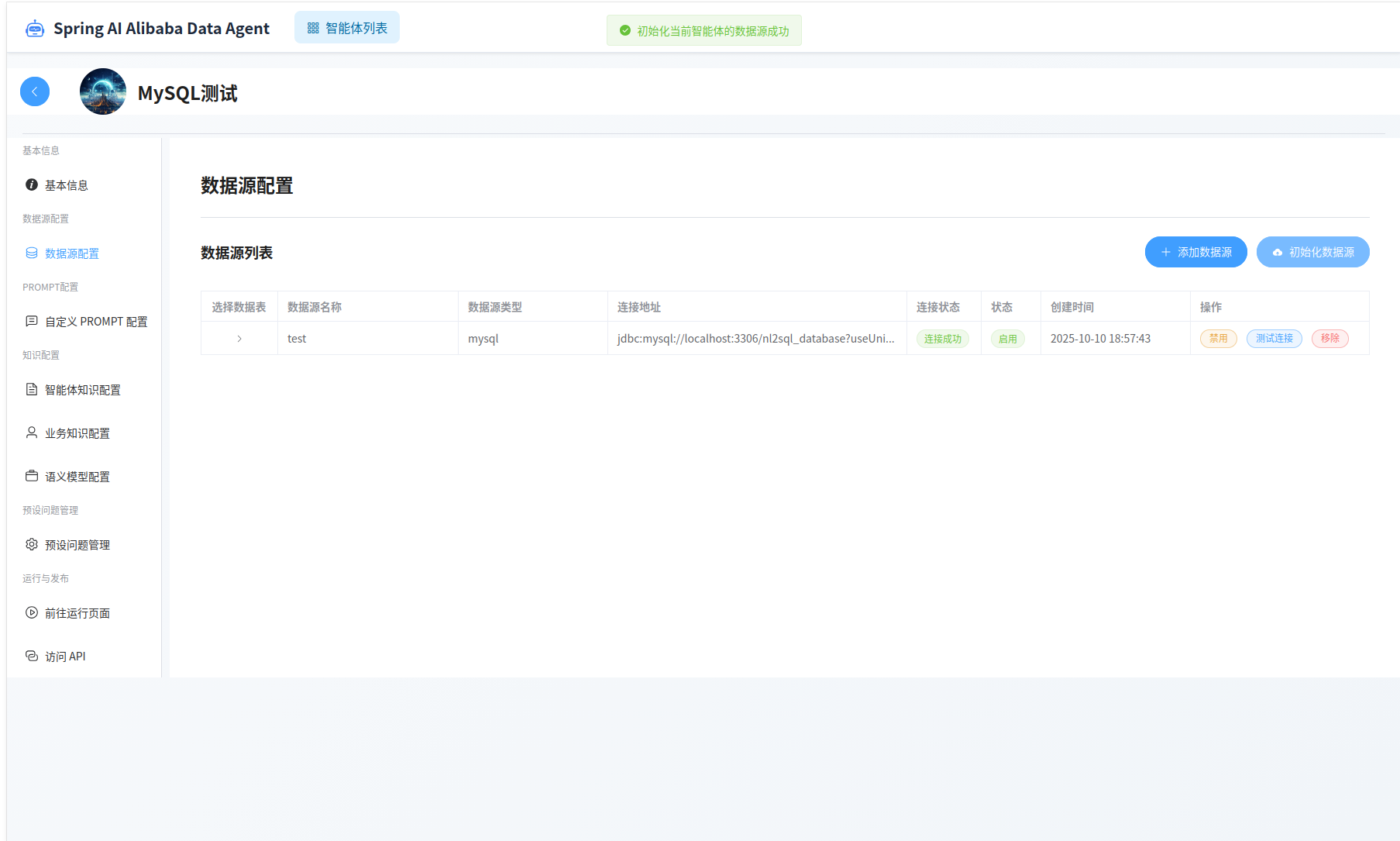
预设问题管理,可以为智能体设置预设问题
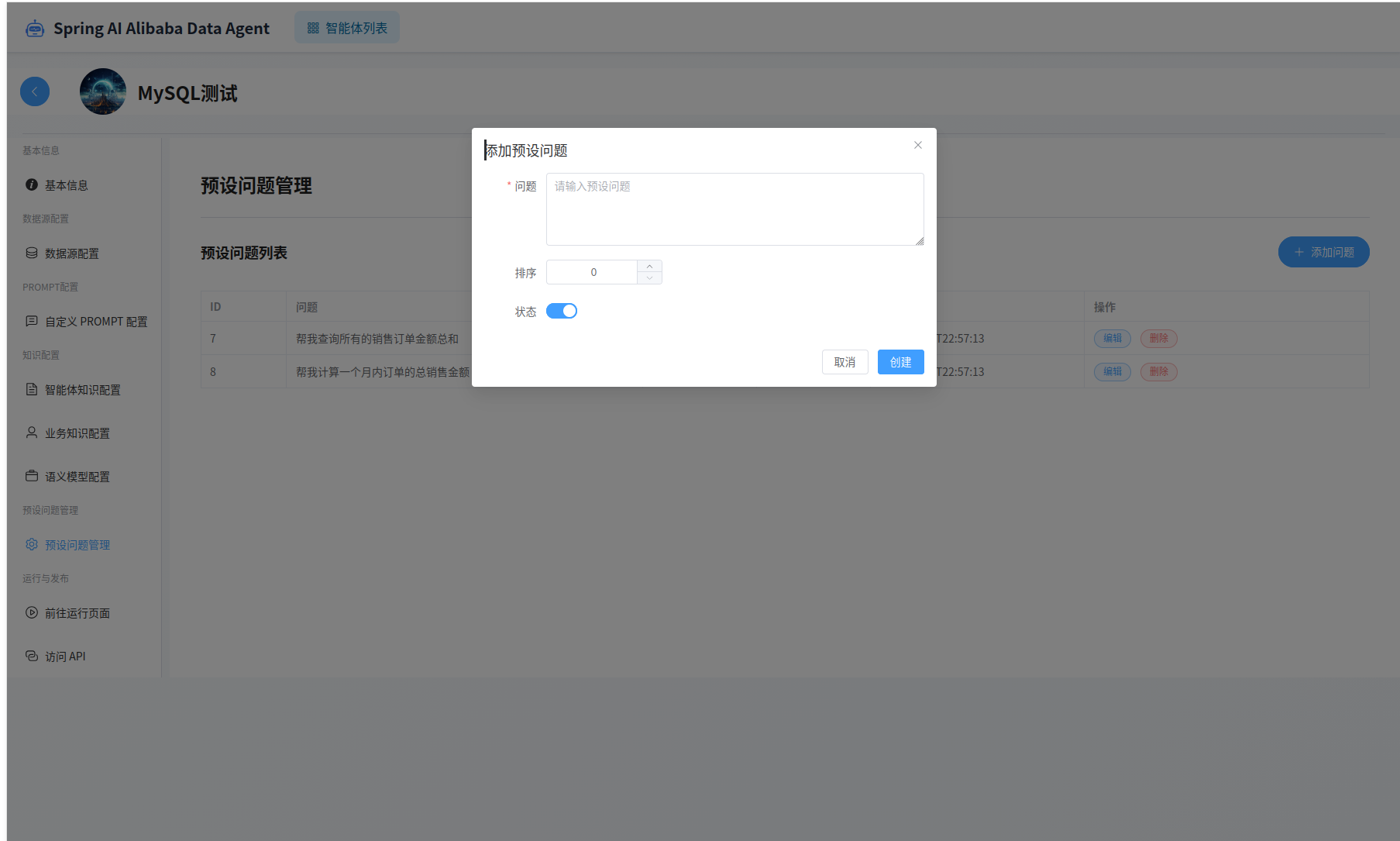
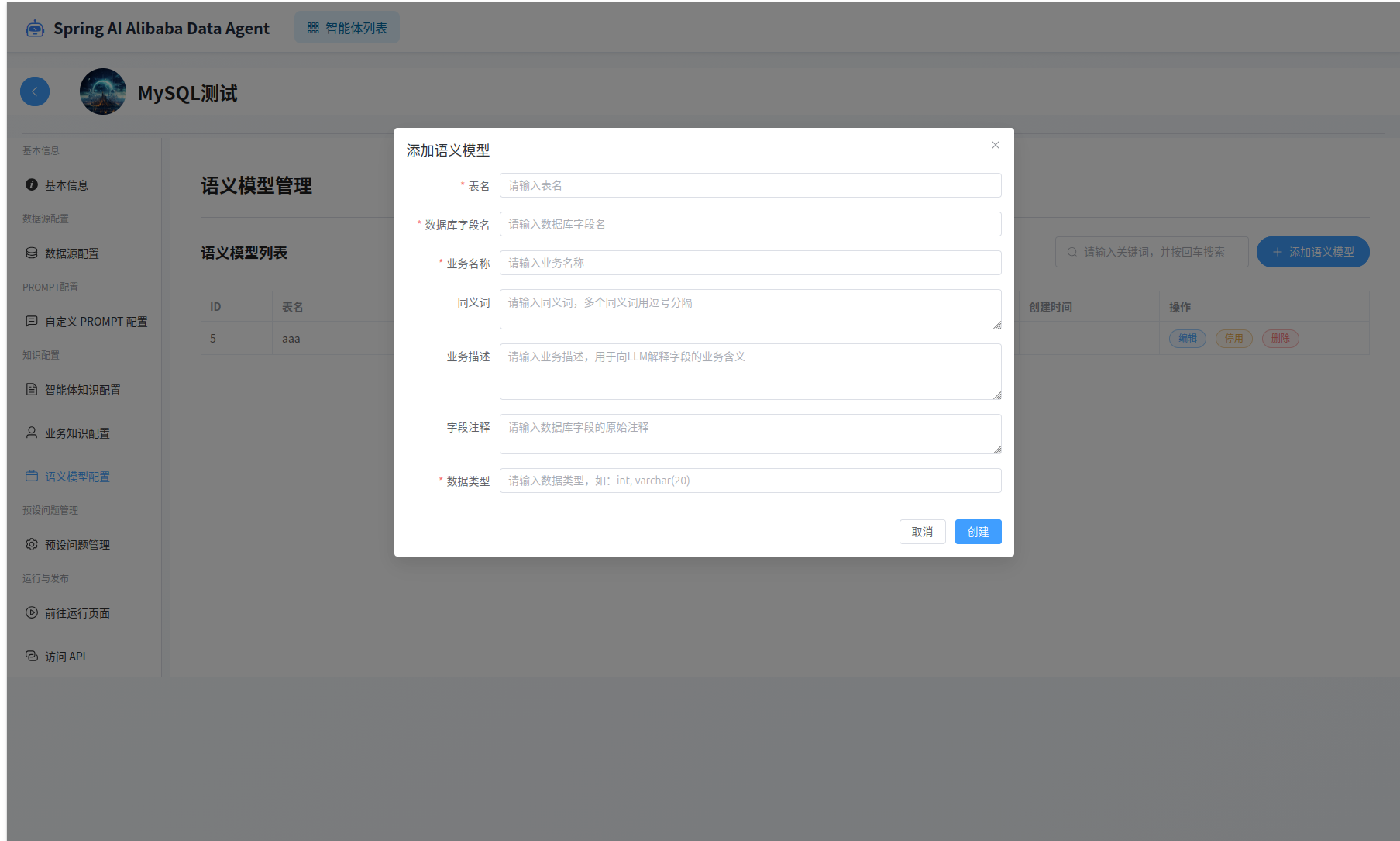
语义模型管理,可以为智能体设置语义模型。
语义模型库定义业务术语到数据库物理结构的精确转换规则,存储的是字段名的映射关系。
例如customerSatisfactionScore对应数据库中的csat_score字段。
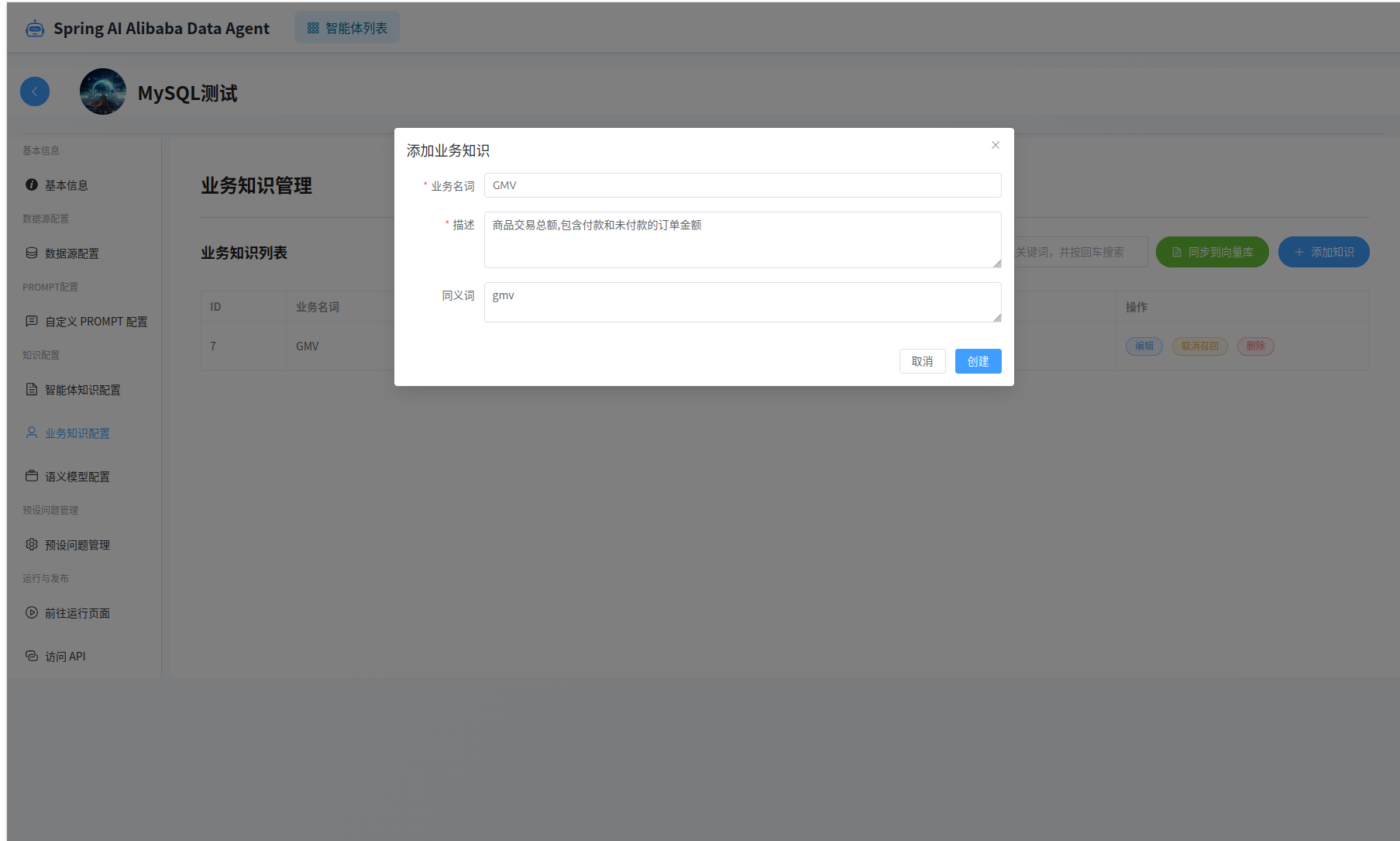
业务知识管理,可以为智能体设置业务知识。 业务知识定义了业务术语和业务规则,比如GMV= 商品交易总额,包含付款和未付款的订单金额。 业务知识可以设置为召回或者不召回,配置完成后需要点击右上角的“同步到向量库”按钮。
成功后可以点击“前往运行界面”使用智能体进行数据查询。 调试没问题后,可以发布智能体。
目前“智能体知识”和“访问API”当前版本暂未实现。
数据智能体的运行
运行界面
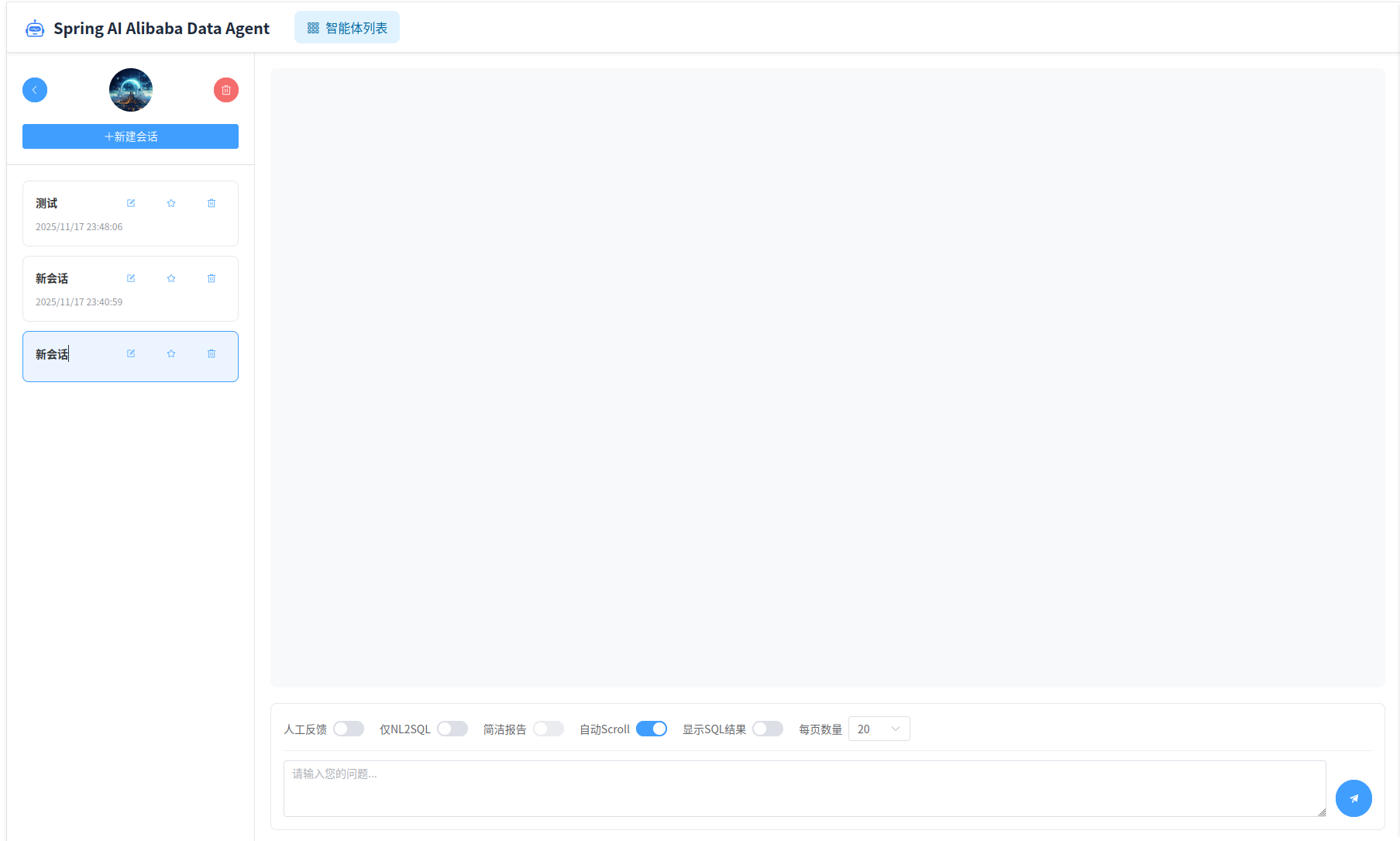
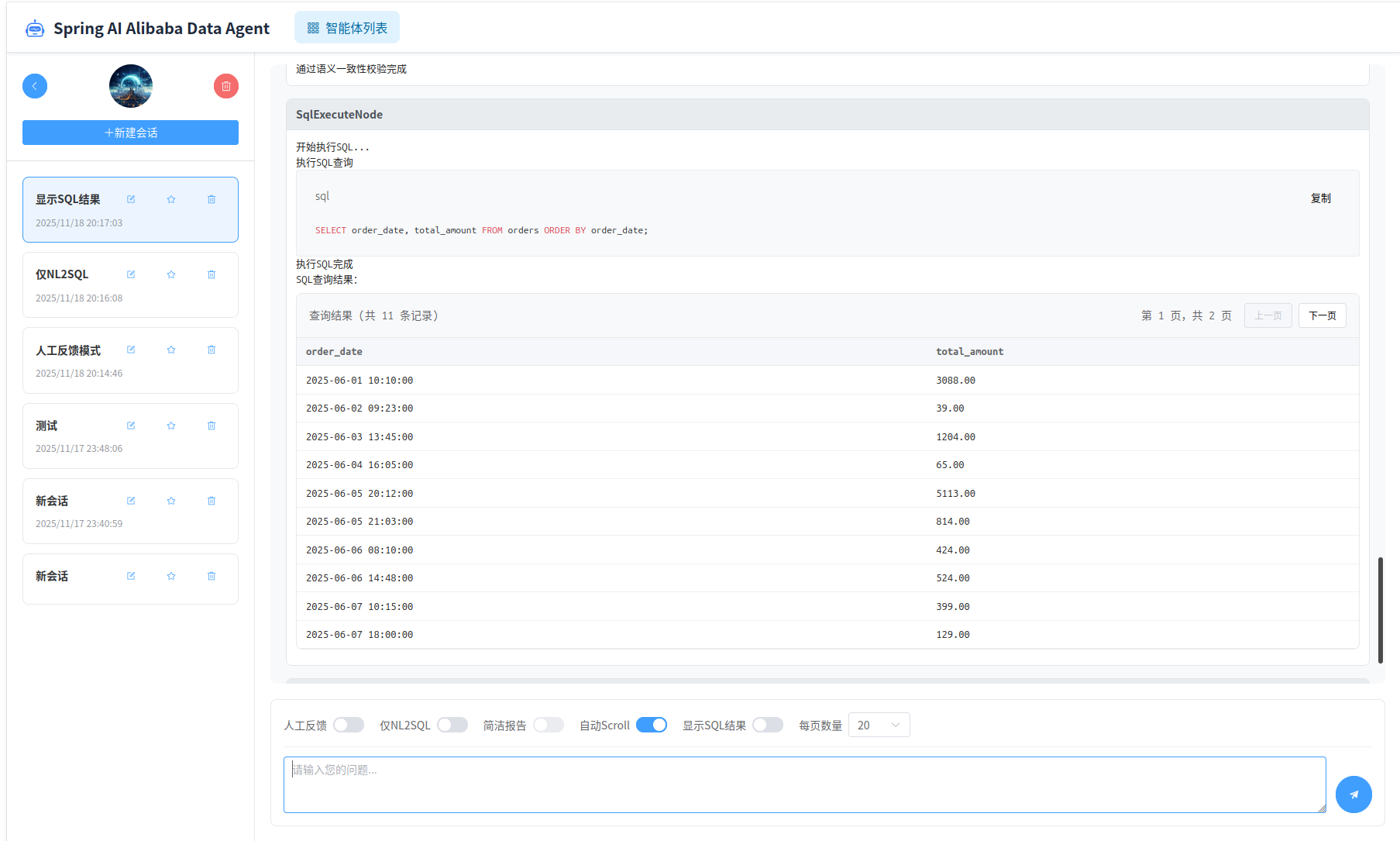
运行界面左侧是历史消息记录,右侧是当前会话记录、输入框以及请求参数配置。
输入框中输入问题,点击“发送”按钮,即可开始查询。
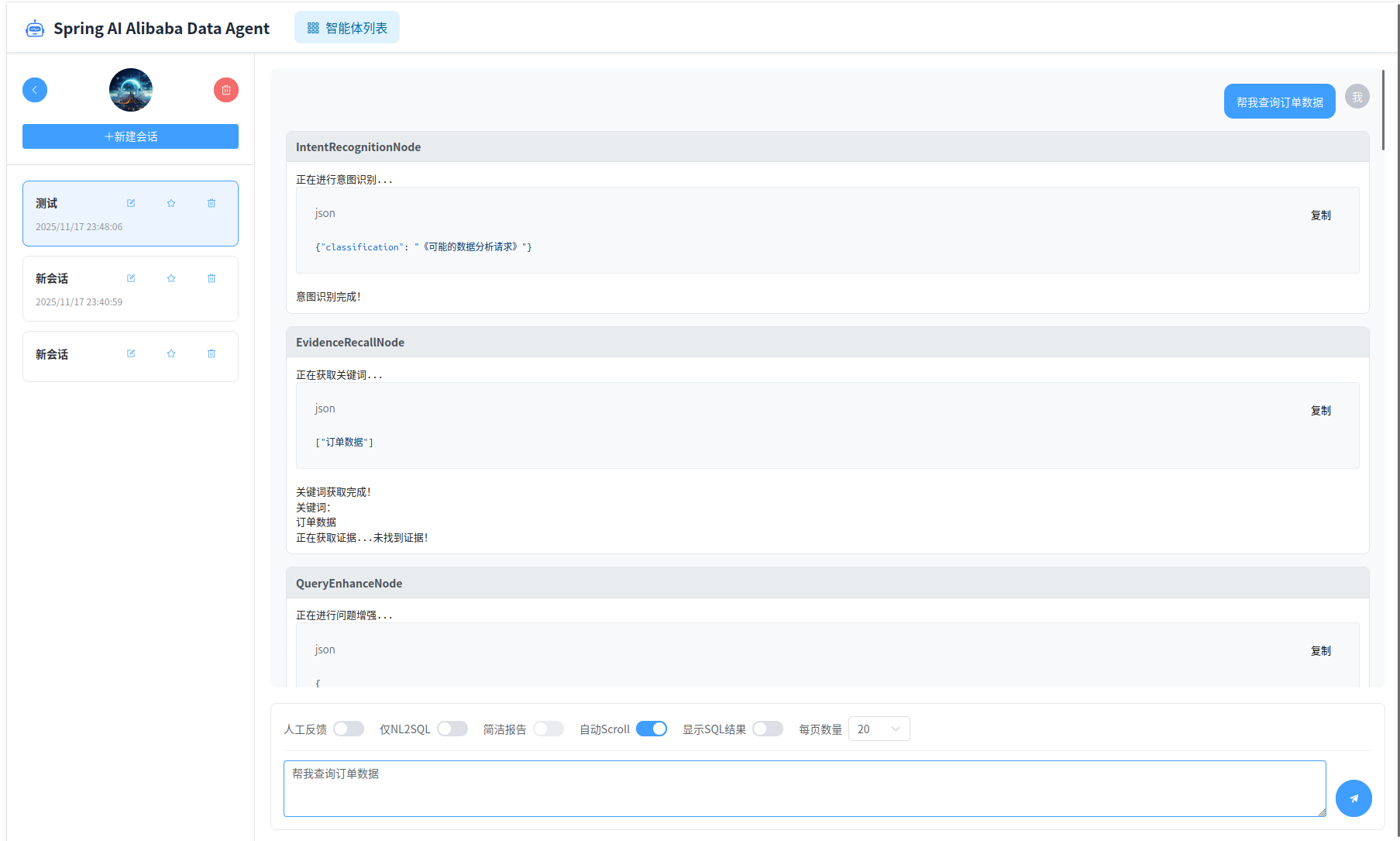
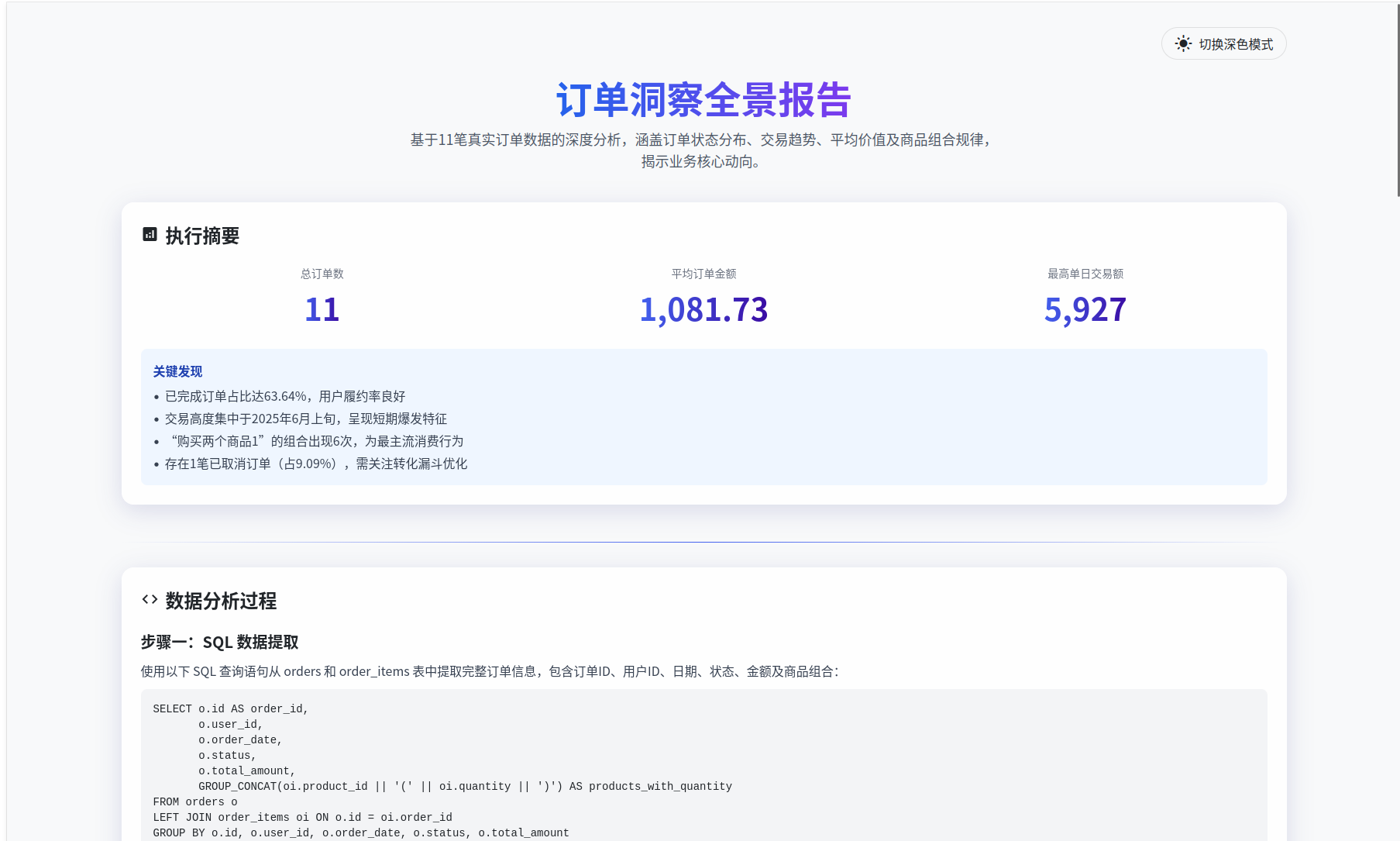
分析报告为HTML格式报告,点击“下载报告”按钮,即可下载最终报告。
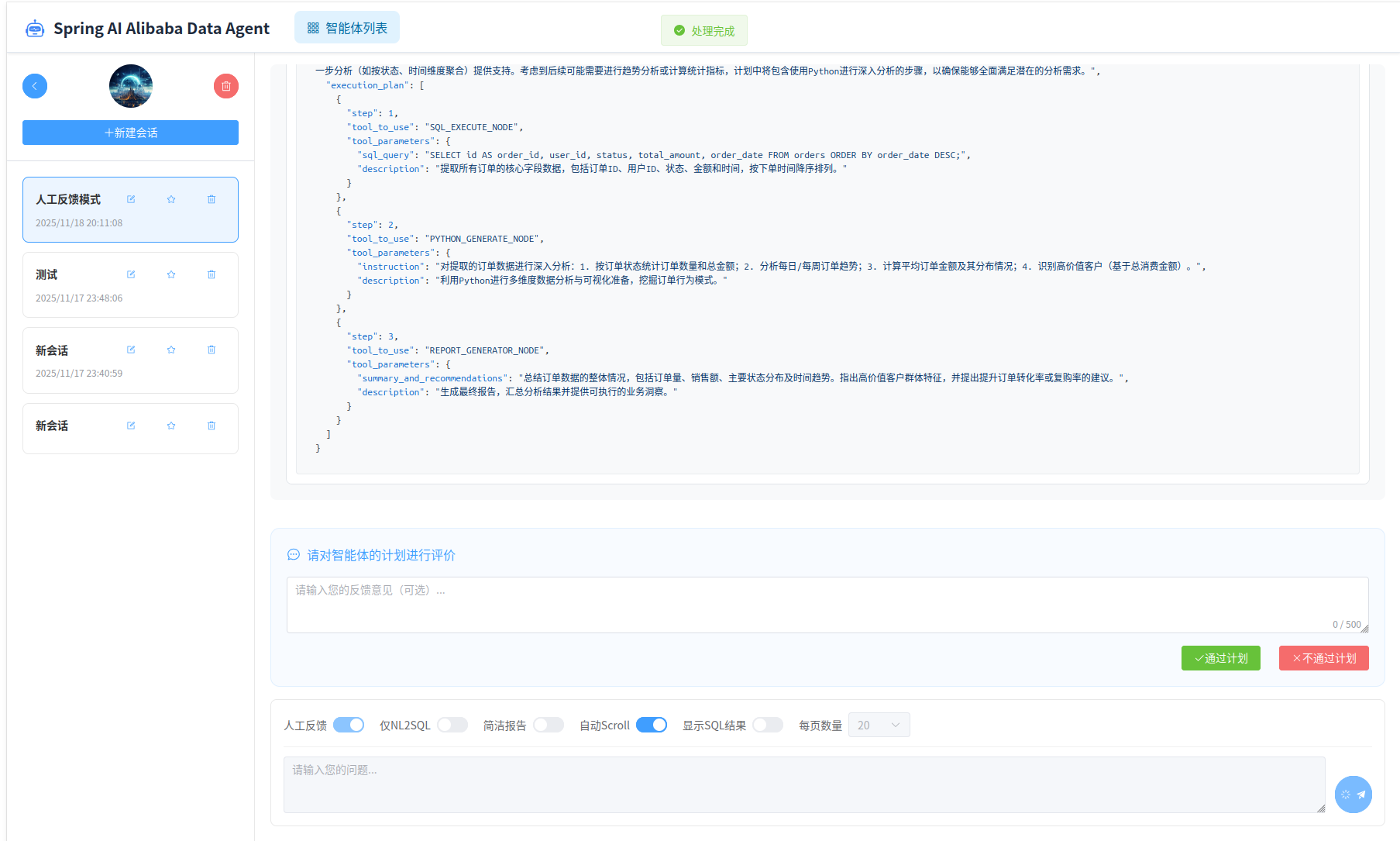
除了默认的请求模式,智能体运行时还支持“人工反馈”,“仅NL2SQL”,“简洁报告”和“显示SQL运行��结果”等模式。
默认情况不开启人工反馈模式,智能体直接自动生成计划并执行,并对SQL执行结果进行解析,生成报告。 如果开启人工反馈模式,则智能体会在生成计划后,等待用户确认,然后根据用户选择的反馈结果,更改计划或者执行计划。
“仅NL2SQL模式”会让智能体只生成SQL和运行获取结果,不会生成报告。
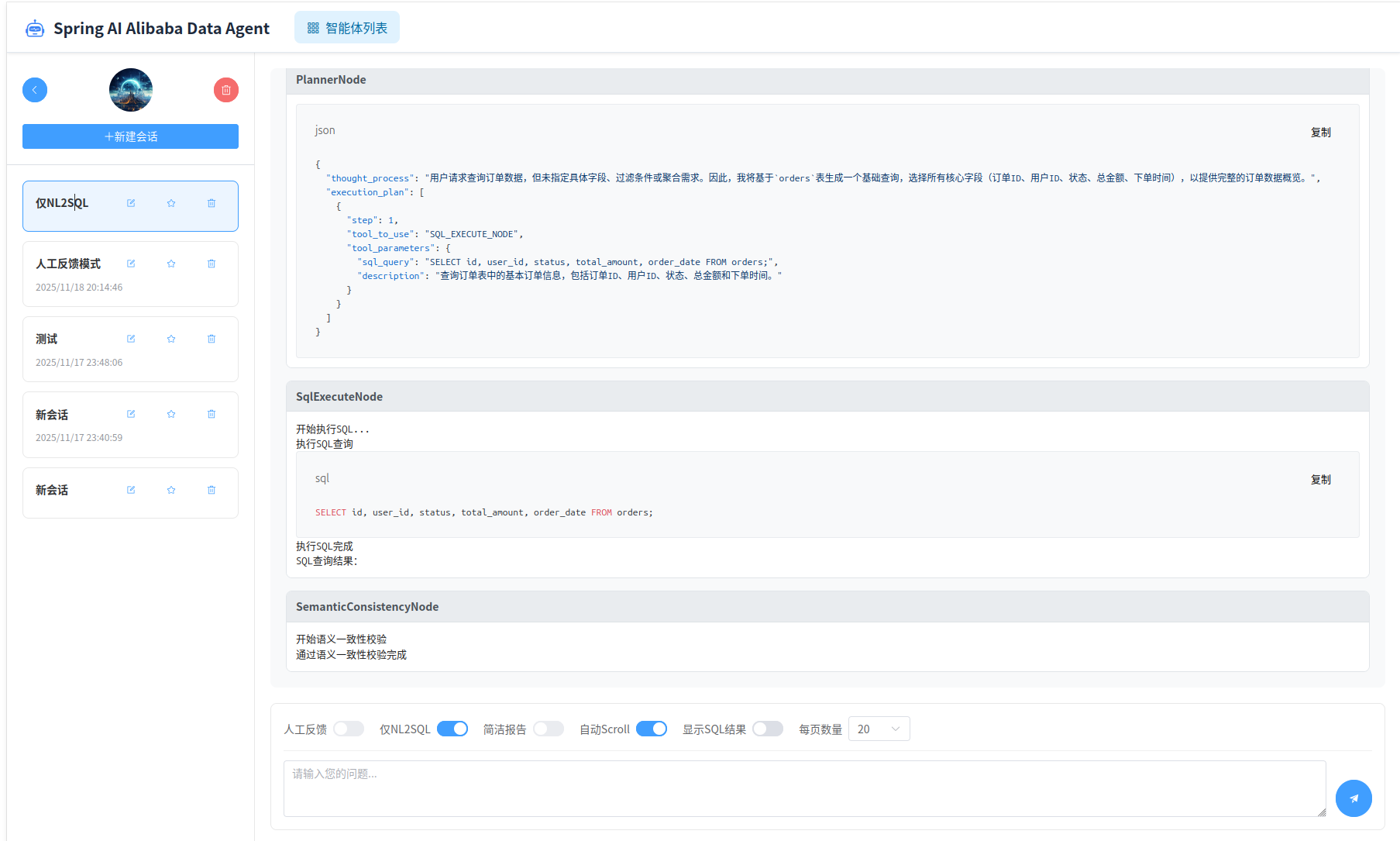
“显示SQL运行结果”会在生成SQL和运行获取结果后,将SQL运行结果展示给用户。